

 新火种
2023-12-17
新火种
2023-12-17 


Transformer不读《红楼梦》,上下文长度真的越长越好?
原文来源:硅星人

图片来源:由无界 AI生成
在 Transformer 的自注意力(self-attention)机制中,每个token都与其他所有的token有关联。所以,如果我们有n个token,那么自注意力的计算复杂性是O(n^2)。随着序列长度n的增加,所需的计算量和存储空间会按平方增长,这会导致非常大的计算和存储开销。
这意味着,当你已经不满足喂给大模型一个两百字的段落,想扔给他一篇两万字的论文,它的计算量增加了1万倍。
图源:Harm de Vries博客
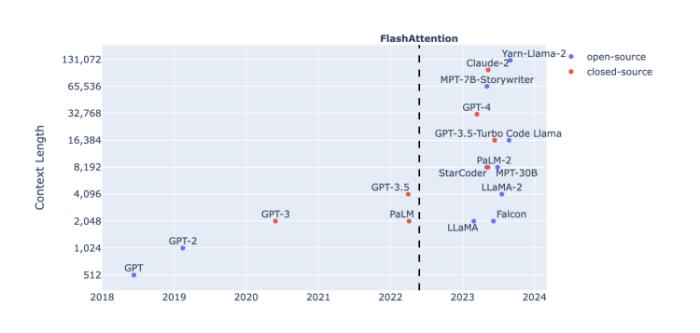
那个负责输入和输出的对话框就像人工智能通往现实世界的一个隘口。从ChatGPT第一次跃上4096个token,到GPT-4将上下文输入长度扩展到32k,再到MetaAI提出的数百万tokens的MegaByte方法,以及国内大模型厂商月之暗面和百川智能之间,20万与35万汉字的长度竞赛,大模型解决实际问题的进程,输入窗的胃口正在变成一个重要的先决条件。
换句话说,当它读《红楼梦》也能像读一个脑筋急转弯那么认真仔细,事情就好办多了。
突破奇点落在了token数上。关于它的研究也从来没有停下。
越长越好?
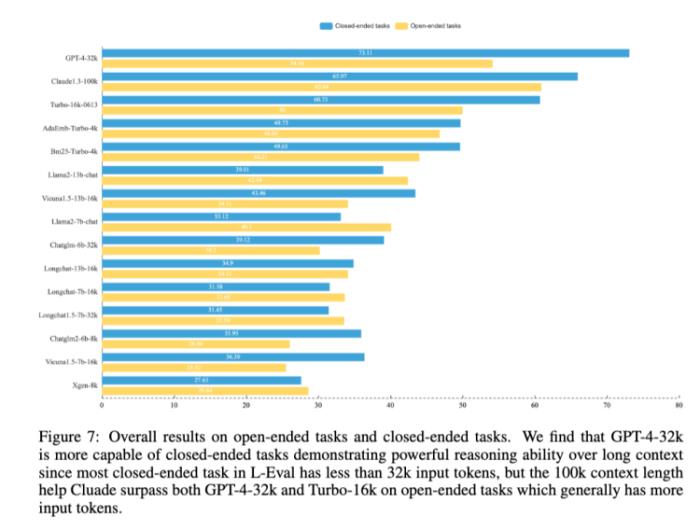
对于上下文长度的推进是必要的,复旦和香港大学的研究团队在一篇论文中做了论证。他们做了一个L-Eval的评价基准,在这个基准的测试下,Claude-100k在封闭任务上的推理能力仍然弱于GPT-4-32k,但在开放式任务中,长度更长——也就意味着通常拥有更多输入标记——的Claude-100k在表现上超过GPT-4-32k。
图源:《L-Eval:Instituting Standardized Evaluation for Long Context Language Models》
结论很积极,意味着勤能补拙的故事仍然是成立的,如果脑子不好,你可以多嘱咐几句,笨一点的学生也能成事。
在那之前,Google Brain也已经做了类似试验,一直参与Bard的研发训练的工程师Li Wei告诉硅星人,去年Google团队已经通过控制训练输入上下文长度的方式来观察模型的输出表现,结果确实上下文长度与模型表现成正相关。这个认识也对后来Bard的研发有所帮助。
至少这是个业内非常笃定的方向。那理论上,一直扩展上下文长度不就好了?
问题是扩张不得,而这个障碍仍然落在Transformer上。
梯度
基于transformer架构的大模型,也就意味着接受了自注意力机制赋予的能力和限制。自注意力机制对理解能力钟情,却天然与长文本输入有所违背。文本越长,训练就越艰难,最坏的结果可能是梯度的爆炸或者消失。
梯度是参数更新的方向和大小。理想的训练下,大模型在生成内容上与人类想要的回答之间的差距应该在每一轮深度学习后都比之前更接近。如果把模型想象成试图在学习一个线性关系y=wx+b的话,w表示模型正在寻找的那个权重。而梯度的概念就是在表达w是如何变化的。
一个稳定的学习过程是渐进的,渐进意味着微调有迹可循。就是说权重不能不变化,也不能突变。
不变化或者变化非常微弱——也就是梯度消失——意味着深度学习网络的学习时间无限延长;突变则被叫做梯度爆炸,权重更新过大,导致网络不稳定。这可能会导致权重变得非常大或模型发散,使得训练无法进行。
三角
而最核心的,短文本很多时候无法完整描述复杂问题,而在注意力机制的限制下,处理长文本需要大量算力,又意味着提高成本。上下文长度本身决定了对问题的描述能力,自注意力机制又决定了大模型的理解和拆解能力,而算力则在背后支撑了这一切。

图源:ArXiv
问题仍然在Transformer上,由于自注意力机制的计算复杂度问题,上下文长度的扩展被困在一个三角形里。
这个不可能三角就摆在这儿,解决方案也在这里。为了增加上下文长度,如果能够把算力(钱和卡)推向无限显然是最理想的。显然现在这不现实,那就只能动注意力机制的心思,从而让计算复杂度从n^2降下来。
对扩展上下文输入的努力很大程度上推动者一场Transformer的革新。
Transformer变形记
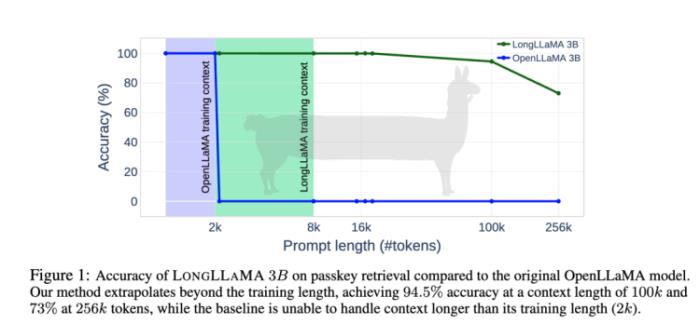
谷歌DeepMind研究团队在今年7月提出了一种新的Focused Transformer(FoT)框架,它采用了一个受对比学习启发的训练过程,以改善(key, value)空间的结构,并且允许一些注意力层通过 k-最近邻 (kNN) 算法访问外部记忆中的(key, value)对。这种机制有效地扩展了总的上下文长度。
这有点像是谷歌在2022年另一个Memorizing Transformer的衍生,后者基于Transformer的调整逻辑是在编码长文本时,模型一边往下读,边把之前见过的所有 token 保存在一个数据库中;在读当前片段时,会用kNN 的方式找到数据库中相似的内容。
Focused Transformer和LLaMA-3B开源模型做了结合,变成LongLLaMA-3B,再和LLaMA-3B在上下文输入的长度方面做了横向对比。结果是上下文输入长度到100k之后,LongLLaMA-3B的回答准确率才开始从94.5%迅速下滑。而LLaMA-3B在超过2k就瞬间跌倒0了。
图源:《Focused Transformer: Contrastive Training for Context Scaling》
从Transformer-XL在2019年出现,引入了分段循环机制(Segment Recurrent Mechanism)为模型提供了额外的上下文,到一年后Longformer和BigBird引入了稀疏注意力机制,将长度第一次扩展到4096个tokens,循环注意力和稀疏注意力机制就开始成为Transformer的改造方向。
Focused Transformer通过 kNN 算法也是实现了某种形式的稀疏注意力,更新的架构调整方案则是Ring Attention。
今年10月,伯克利的团队提出了环注意力(Ring Attention),Ring Attention从内存角度改变Transformer框架。通过分块处理自注意力机制和前馈网络计算的方法,上下文序列可以分布在多个设备上,并更有效地进行分析。这也理论上消除了单个设备所施加的内存限制,使得序列的训练和推断能够处理比之前的内存效率更高的Transformer长得多的序列。
也就是说,Ring Attention实现了“近乎无限的上下文”。
当头一棒
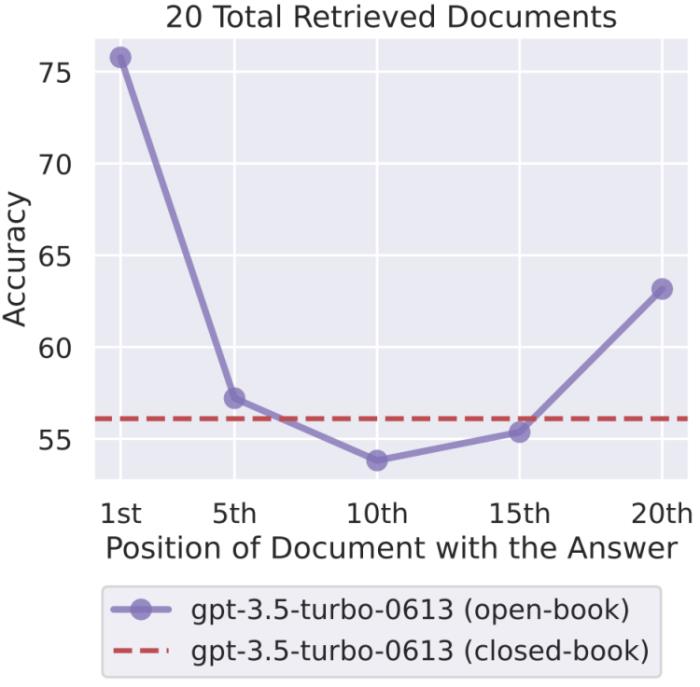
但这件事也不是绝对的。斯坦福在9月公布了一项研究表明,如果上下文太长,模型会略过中间不看。
他们对多种不同的开源(MPT-30B-Instruct、LongChat-13B (16K))和闭源(OpenAI 的 GPT-3.5-Turbo 和Anthropic 的 Claude)的语言模型进行了对照实验。研究者通过向输入上下文添加更多文档来增大输入上下文的长度(类似于在检索增强式生成任务中检索更多文档);以及通过修改输入上下文中文档的顺序,将相关信息放置在上下文的开头、中间或结尾,从而修改上下文中相关信息的位置。
图源:《Lost in the Middle: How Language Models Use Long Contexts》
结果是随着相关信息位置的变化,模型性能呈现出明显的 U 型趋势。也就是说,当相关信息出现在输入上下文的开头或末尾时,语言模型的性能最高;而当模型必须获取和使用的信息位于输入上下文中部时,模型性能会显著下降。举个例子,当相关信息被放置在其输入上下文中间时,GPT3.5-Turbo 在多文档问题任务上的性能劣于没有任何文档时的情况(即闭卷设置;56.1%)。此外,研究者还发现,当上下文更长时,模型性能会稳步下降;而且配有上下文扩展的模型并不一定就更善于使用自己的上下文。
当头一棒!
但这或许也是好事,如果文章太长,人们大概也只会记得开头和结尾,大模型与人类大脑何其相似。
交锋
目前全球主流的大模型中,GPT-4与LLaMA 2 Long的上下文长度都已经达到了32k,Claude 2.1达到200k。国内的大模型中,ChatGLM-6B的上下文长度达到了32k,最晚亮相的明星公司月之暗面直接拿出了一个200k的Kimi Chat。
月之暗面的思路同样是改造Transformer,但杨植麟同时也引出一场交锋。
蝌蚪模型和蜜蜂模型。
直白说,凹一个造型让模型看起来可以支持更长的上下文输入有很多途径,最简单的办法是牺牲模型本身的参数。
模型参数的降低,意味着内存消耗的减少以及计算的简单化,内存和计算资源的重新分配能够转变成同样算力资源下上下文输入长度的增加。回过头来看,Focused Transformer的验证放在一个3B的小参数模型上,对于Ring Attention的试验也更侧重于所提出方法的有效性验证,而没有经历百亿参数以上的大模型。
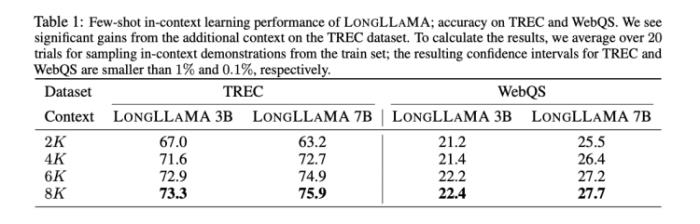
图源:《Focused Transformer: Contrastive Training for Context Scaling》
但10亿级别的模型参数并不具备太好的智能涌现能力。杨植麟形容其为蝌蚪模型,因为它做不了更多事情。
除此之外,另一种可以增加长度的方式是从外部引入搜索机制。
探索的原理
这也是目前相当多大模型能快速扩展上下文长度所采取的办法——如果不动自注意力机制,另一种方式就是把长文本变成短文本的集合。
比如常见的Retrieval-augmented generation (RAG) 。它是一个结合了检索 (retrieval) 和生成 (generation) 两种机制的深度学习框架,目的是将信息检索的能力引入到序列生成任务中,使得模型在生成响应或内容时可以利用一个外部的知识库。
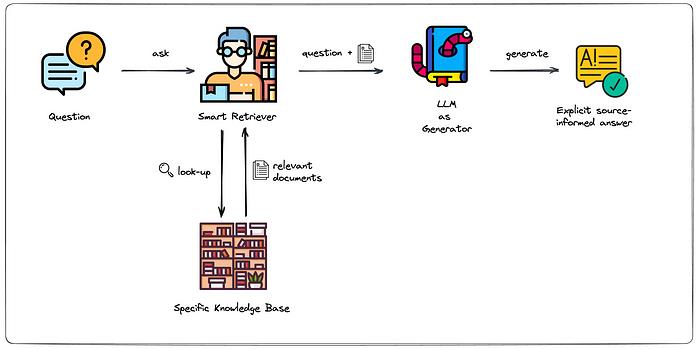
图源:Towhee
模型在处理长文本时,引入的搜索机制会在数据库中对短文本进行检索,以此来获得多个短文本回答构成的长文本。每次只加载所需要的短文本片段,从而避开了模型无法一次读入整个长文本的问题。
杨植麟将这类模型称为蜜蜂模型。
传统的 Transformer 机构,如 GPT,其输入长度有限,通常限于几百到几千的token。这意味着当需要处理大量的信息或长文档时,模型可能会遇到困难。RAG 通过其检索机制可以在一个大型的外部知识库中检索信息,然后仅将最相关的片段与原始输入一起送入生成模型。这使得模型能够处理比其原始输入长度更大。
这个观点背后的原理很有意思。如果循环注意力和稀疏注意力都是在模型内部对注意力机制进行改进,属于模型结构级的优化,那么通过在外部数据库中检索相关信息片段,然后将最相关的片段与原始输入一起送入生成模型,来避免直接处理完整的长文本,这仅仅属于输入级的优化。
这种方法的主要目的是从大量的文档中快速捕获与当前问题最相关的信息片段,而这些信息片段可能只代表了原始输入的部分上下文或某些特定方面。也就是说,这种方法更重视局部的信息,可能无法把握一个长文本输入的整体含义。
就像蜂巢中互相隔开的一个个模块。
蜜蜂模型的说法有一些戏谑意味的指向了市面上用外挂搜索来拓展窗口容量的大模型厂商,很难让人不想到近几个月发展迅速,一直强调自己“搜索基因”的百川智能。
10月30日,百川智能发布全新的Baichuan2-192K大模型。上下文窗口长度拉长到192K,折算成汉字约等于35万字。月之暗面的Kimi Chat才将Claude-100k的上下文长度扩充了2.5倍,Baichuan2-192K又几乎把Kimi Chat的上限翻了倍。
在长窗口文本理解评测榜单LongEval上,Baichuan2-192K的表现远优于Claude-100k,在窗口长度超过 100K后依然能够保持强劲性能,后者在70k之后的表现就极速下跌了。
也没这么多长文本
但关于“我们为什么不试试更长的上下文”这个问题,还有另一个观察角度。
公开可用的互联网抓取数据集CommonCrawl是 LLaMA 训练数据集的主要数据来源,包括从CommonCrawl中获取的另一个主要的数据集C4,两者占据了LLaMA 训练数据集中的82%,
CommonCrawl中的语料数据是很短的。ServiceNow 的研究员Harm de Vries在一篇分析文章中表示,这个占比庞大的数据集中,95%以上的语料数据文件的token数少于2k,并且实际上其中绝大多数的区间在1k以下。
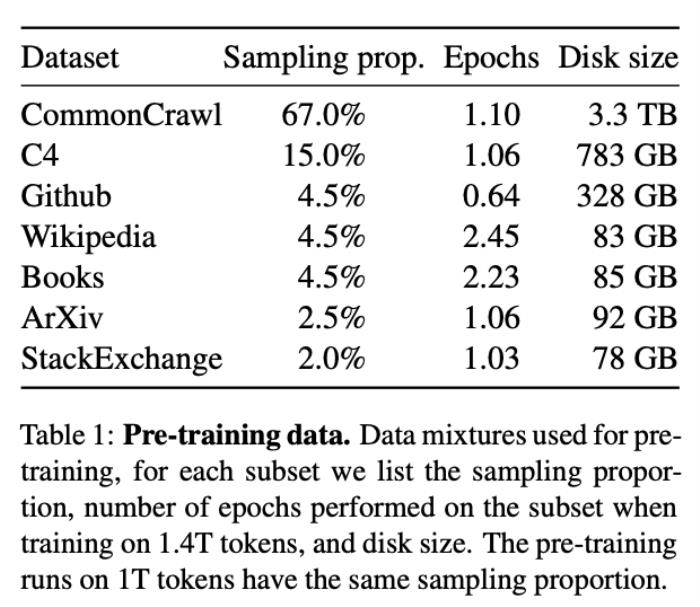
图源:Harm de Vries博客
“如果要在其中寻找到有明显上下文逻辑的长文本就更少了”,Li Wei说。
更长的训练预料被寄希望于书籍或论文甚至者维基百科等来源。Harm de Vries的研究表明,有50%以上的维基百科文章的词元数超过了4k个tokens,75%以上的图书词元数超过了16k个tokens。但无奈以LLaMA训练预料的主要数据来源分布来看,维基百科和书籍的占比都仅仅是4.5%,论文(ArXiv)的占比只有2.5%。三者相加只有270GB的数据,不到CommonCrawl一成。
或许目前也压根没有这么多长文本语料能够用于训练,Transformer们不读《红楼梦》也没有那么多《红楼梦》可读,是横贯在所有追求上下文长度的人们面前真正的难题。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










