新火种
2023-12-08
新火种
2023-12-08 


伯克利分校推开放大模型Starling-7B接受人工智能反馈训练
要点:
由加州大学伯克利分校研究人员推出的Starling-7B是一款基于Reinforcement Learning from AI Feedback(RLAIF)的开放式大型语言模型(LLM),采用人工智能反馈来提升其性能,特别是在聊天机器人响应方面。
RLAIF采用来自其他人工智能模型的反馈进行训练,以改进模型的性能。相比于以往的人工反馈,AI反馈具有更低的成本、更快的速度、更透明和更可扩展的潜力。Starling-7B通过RLAIF在性能上取得了显著的改进。
Starling-7B在两个基准测试中(MT-Bench和AlpacaEval)表现优异,尤其在安全性和帮助性方面。研究人员指出,虽然RLAIF主要提高了模型的帮助性和安全性,但在基本能力方面,如回答基于知识的问题、数学或编码,改进不大。未来的研究方向可能包括引入高质量的人工反馈数据,以更好地适应模型对人类需求的理解。
站长之家11月29日 消息:加州大学伯克利分校的研究人员推出了一款名为Starling-7B的开放式大型语言模型(LLM),采用了一种称为Reinforcement Learning from AI Feedback(RLAIF)的创新训练方法。
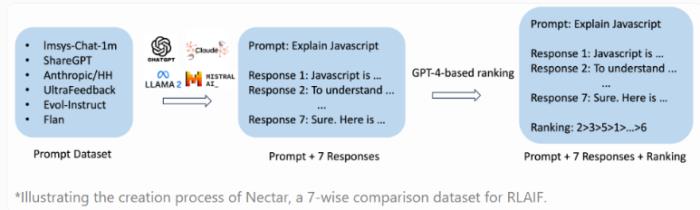
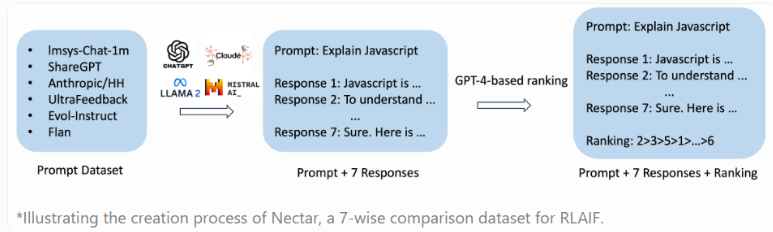
RLAIF的独特之处在于利用其他人工智能模型的反馈来提升性能,相较于传统的人工反馈,这种方法更具有成本效益、速度快、透明度高、可扩展性强的优势。Starling-7B基于新的Nectar数据集进行训练,包含183,000个聊天提示和380万个成对比较。
研究人员使用两个基准测试(MT-Bench和AlpacaEval)评估了Starling-7B的性能,这两个测试使用GPT-4进行评分,分别关注模型在简单指令跟随任务中的安全性和帮助性。Starling-7B在MT-Bench中表现良好,与OpenAI的GPT-4和GPT-4Turbo相媲美,在AlpacaEval中达到了与商业聊天机器人相当的水平。
研究人员指出,RLAIF主要改善了模型的帮助性和安全性,而在基本能力方面,如回答基于知识的问题、数学或编码等,改进较小。
尽管基准测试的实际应用有限,但对RLAIF的应用前景充满希望。研究人员建议的下一步是通过引入高质量的人工反馈数据,更好地调整模型以满足人类需求。
与此同时,研究人员强调,Starling-7B和其他类似的大型语言模型在需要推理或数学任务时仍然存在困难,并可能产生幻觉。他们将Nectar数据集、Starling-RM-7B-alpha奖励模型和Starling-LM-7B-alpha语言模型发布在Hugging Face上,并提供了研究许可证,代码和论文将很快公开。感兴趣的人还可以在聊天机器人领域测试该模型。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章