新火种
2023-11-30
新火种
2023-11-30 


ChatGPT一周年|ChatGPT写了段总结,给自己打了这个分数
【编者按】2022年11月30日,可能将成为一个改变人类历史的日子——美国人工智能开发机构OpenAI推出聊天机器人ChatGPT。它不仅催生了人工智能界的又一轮高光期,还并不常见地被誉为“蒸汽机时刻”、“iPhone时刻”甚至“钻木取火时刻”。
这一年来,被称为“生成式人工智能”的革命性技术激发了全球科技界“把所有软件和硬件重做一遍”的冲动,让具有先发优势的AI基础设施提供商价值暴涨,使得从医疗到航天的科学探索获得被加倍赋能的前景,传说中“奇点”的到来从未变得如此具有可能性。
正如历史上任何一次技术变革,ChatGPT也给我们带来了深深的焦虑。既有对AI威胁人类生存的科幻式恐惧,也有对砸掉我们饭碗、骗取我们钱财、操纵我们心灵的现实担忧。连OpenAI自身,也刚刚经历了一场危机,差点没躲过一夜坍塌的命运。
这一年让我们产生了更多疑问:大语言模型下一步的进化方向是什么?训练数据快要耗尽了吗?如何看待中国的大语言模型发展?AGI(通用人工智能)是否会存在其他形式?为此,澎湃科技(www.thepaper.cn)询问了ChatGPT本尊,请它回答这些问题并给自己做一个年度总结。
其中,ChatGPT-3.5版本无法对部分问题提供具体信息,因此部分问题使用了ChatGPT-4.0版本。
以下为澎湃科技与ChatGPT的对话:
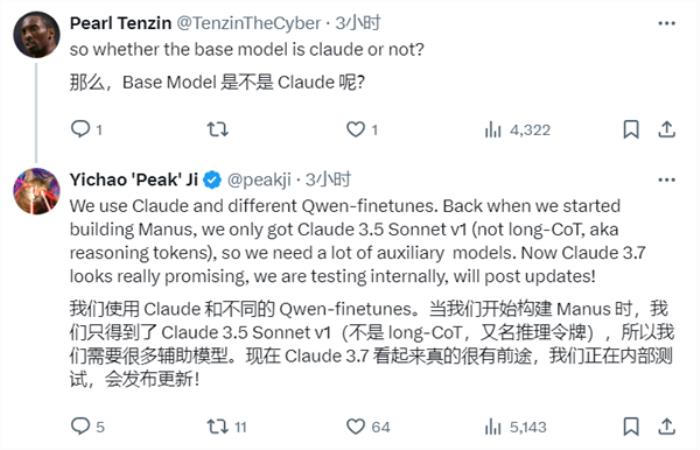
澎湃科技:ChatGPT推出一周年了,如果让你用3个关键词来形容ChatGPT发布后对行业的影响,你会用哪3个形容词?为什么是这3个词语?
ChatGPT:创新、智能化、交互性。
“创新”是因为ChatGPT的推出标志着自然语言处理领域的一项重大进展,开创了更高级的对话型人工智能。“智能化”强调了系统的智能程度和对复杂任务的适应能力。而“交互性”突显了用户能够与系统更自然、动态地交流,这对用户体验和应用场景的拓展都具有重要影响。
澎湃科技:过往一年,你怎么总结ChatGPT的表现?会打多少分?写一段年终总结吧。
ChatGPT:ChatGPT在过去一年中表现出色,取得了显著的进展。它成为自然语言处理领域的一项重要创新,为用户提供了更灵活、智能的对话体验。通过持续的更新和改进,ChatGPT在语境理解、回答问题以及生成自然语言文本方面取得了显著的成就。
然而,也要认识到一些挑战,例如在处理复杂或专业性话题时可能存在理解不足的情况。尽管在普通对话中表现卓越,但在某些情境下仍有改进的空间。未来,期望看到更多关注于提高模型的适应性和解决实际问题的努力。
综合考虑,给予ChatGPT过去一年的表现8.5/10的评分,看到了许多令人振奋的进展,但也认识到未来仍有继续改进和发展的机会。
澎湃科技:过去一周,OpenAI公司发生了戏剧性的变化。Sam Altman(注:OpenAI创始人山姆·奥特曼)重新回归,可能说明OpenAI在商业化扩张与对安全的重视之间,最终选择了前者?这与你们的使命冲突吗?
ChatGPT:过去一周,关于Sam Altman重新回归OpenAI领导岗位的消息并没有得到官方确认。至于OpenAI的使命和战略方向,它始终致力于促进和发展人工智能,同时确保其安全和有益。这包括在商业化和安全性之间寻找平衡。
OpenAI的使命是确保人工智能的发展能够以有利于全人类的方式进行。这意味着在开发商业产品和服务的同时,也需要考虑到安全性、伦理和社会影响。因此,公司的战略可能包括商业化的扩张,但这并不意味着会牺牲对AI安全和伦理的重视。
总的来说,OpenAI的目标是创造正面的社会影响,并在推动技术创新的同时,确保技术的使用是安全和负责任的。如果有关于OpenAI方向和策略的具体更新,它们通常会通过官方渠道公布。
*注:这个问题因为涉及最新信息,3.5版本回答不出来,所以改问4.0版本。以下问题都使用了4.0版本。
澎湃科技:过往一年,以ChatGPT为代表的AI技术应用到各个不同的场景中,也引发了不少关于法律的纠纷,怎么看ChatGPT带来的法律风险和挑战?
ChatGPT:过去一年,以ChatGPT等AI技术的广泛应用确实在法律领域引起了许多讨论和挑战。这些挑战主要集中在以下几个方面:
1. 版权和知识产权:AI生成的内容(如文本、艺术作品等)涉及版权归属问题。这引发了关于AI是否可以被视为作品的作者,以及AI使用人类创作的材料生成新作品是否侵犯了原始作品的版权的讨论。
2. 责任与问责:当AI应用在关键决策过程中(如医疗、金融等)时,若出现错误或损害,应由谁负责(AI开发者、用户、还是AI本身)是个复杂问题。
3. 隐私与数据保护:AI系统,尤其是像ChatGPT这样的基于大量数据训练的模型,涉及到大量个人和敏感数据的处理。这引发了关于数据隐私、安全性以及合规性的问题。
4. 伦理和偏见:AI系统可能在其回答和决策中体现出开发过程中的偏见,这可能引起关于算法公正性和非歧视的法律挑战。
应对这些挑战的方法包括:制定明确的法律和政策框架、增强AI系统的透明度和可解释性、确保数据处理的合规性、以及在AI系统的设计和应用中考虑伦理和公平性。这些都是目前AI领域研究和讨论的热点话题。随着技术的不断进步和应用的扩展,相关的法律和伦理框架也将继续发展和完善。
澎湃科技:在保障用户的数据安全方面,ChatGPT有什么改善计划?
ChatGPT:您的总结非常到位。确实,随着AI技术如ChatGPT的广泛应用,这些挑战和问题已成为法律、伦理和社会学领域的重要议题。特别值得一提的是,这些挑战并非静态的,而是随着技术的进步和社会认知的变化而不断发展。
例如,在版权和知识产权方面,现行的法律体系可能需要适应新的技术现实,考虑到AI如何创作和使用内容。在责任与问责问题上,可能需要新的法律框架来确定在AI辅助或自动化决策过程中的责任分配。
隐私和数据保护方面的挑战尤其突出,因为AI系统通常需要处理大量的个人数据,这涉及到数据保护法规的遵守和用户隐私的保护。
伦理和偏见的问题则需要我们深入研究AI算法的设计和训练过程,确保其不会放大现有的社会偏见或造成新的不公平现象。
总之,AI技术的发展和应用给现有的法律和伦理框架带来了挑战,同时也提供了更新和改进这些框架的机会。这需要法律专家、技术开发者、政策制定者和社会各界的共同努力。随着对这些问题的深入研究和讨论,我们可以期待更加全面和成熟的解决方案。
澎湃科技:你希望ChatGPT接下来的发展目标和路径是什么样的?
ChatGPT:作为一个AI模型,我没有个人的希望或期望。然而,可以展望ChatGPT未来可能的发展方向,这些方向反映了目前在人工智能领域的趋势和需求:
1. 更高的准确性和可靠性:不断提升模型的精确度,确保信息的准确性和时效性,减少误解和错误。
2. 增强的理解和生成能力:通过更先进的算法和更大的数据集训练,提高模型的语言理解和回答生成能力,使其能够处理更复杂和多样的查询。
3. 更强的个性化和适应性:发展AI的能力,以更好地理解和适应不同用户的需求和偏好,提供更个性化的交互体验。
4. 伦理和公平性的加强:加大对模型偏见和伦理问题的关注,确保AI的使用更加公正和无歧视。
5. 隐私和安全性的提升:强化数据处理的安全性和隐私保护,以增强用户对使用AI技术的信任。
6. 多模态能力的发展:除了文本,还可以整合图像、声音等多种数据类型的处理能力,实现更全面的AI应用。
7. 跨领域应用的扩展:将ChatGPT的应用扩展到更多领域,如教育、医疗、法律等,提供更专业和定制化的服务。
8. 可解释性和透明度的增强:提高AI决策过程的可解释性,使用户能更好地理解AI的工作原理和决策依据。
这些目标和路径旨在使ChatGPT成为一个更有效、更安全、更负责任的AI工具,同时为用户提供更丰富、更个性化的体验。随着技术的不断进步,ChatGPT和类似的AI系统将继续在这些方向上发展和完善。
澎湃科技:大语言模型下一步的进化方向是什么,有什么挑战?
ChatGPT:大型语言模型(如GPT系列)的下一步进化方向可能包括以下几个关键领域,同时也面临着相应的挑战:
进化方向:
1. 更高级的理解能力:进一步提升模型对复杂语言结构和隐含意义的理解能力。
2. 多模态集成:整合文本、图像、声音等多种数据类型,使模型能够处理和理解跨媒体的信息。
3. 更强的推理和创造能力:提升模型在复杂问题解决和创造性任务(如编程、艺术创作等)中的表现。
4. 个性化和适应性:使模型更好地适应个别用户的特定需求和偏好。
5. 可解释性和透明度:增强模型的决策过程的可视化和解释能力,提高用户的信任和理解。
面临的挑战:
1. 数据和隐私问题:如何在不侵犯用户隐私的情况下收集和处理大量数据。
2. 偏见和公平性:避免训练数据中的偏见在模型输出中得到放大。
3. 复杂性管理:随着模型规模的增大,如何有效管理和运行越来越复杂的系统。
4. 安全性和滥用风险:防止模型被用于生成误导性或有害内容,确保安全和负责任的使用。
5. 技术和算法的创新:持续的研究和开发以解决现有模型的局限性,如长期记忆、因果推理等。
总体而言,大型语言模型的未来发展将是在提升技术能力的同时,不断解决伴随其成长的伦理、法律和社会挑战。这需要来自技术、法律、伦理和社会各领域的专家共同参与和努力。随着技术的发展,我们可以预期更加先进、智能且负责任的大型语言模型。
澎湃科技:大模型的训练数据快要耗尽了吗?怎么解决这个问题?
ChatGPT:关于大模型的训练数据快要耗尽的问题,实际情况比较复杂。虽然目前的大型语言模型(如GPT系列)已经使用了海量的数据,但理论上,随着互联网和数字内容的不断增长,数据源是持续更新和扩充的。
以下是这个问题的一些关键考虑因素以及可能的解决方案:
数据源的丰富性:
1. 持续更新的内容:互联网上的内容是持续更新的,包括新闻、论坛帖子、社交媒体更新等,提供了不断更新的数据源。
2. 多样化的数据类型:除了文本数据,还可以探索图像、视频、音频等其他类型的数据。
数据耗尽的问题:
1. 质量而非数量:重点可能逐渐从“更多数据”转向“更高质量或更相关数据”的获取。未标记数据的挑战:大量的数据未经标记或分类,这需要更高效的数据处理和学习算法。
解决方案:
1. 更有效的学习算法:发展新的学习算法,让模型能够从更少的数据中学习更多的信息。
2. 强化学习和迁移学习:利用已有模型作为基础,适应新的任务或数据集。
3. 数据增强和合成:通过数据增强技术创造新的训练数据。
4. 更多的用户生成数据:利用用户与AI互动中产生的数据进行训练。
5. 众包和社区参与:鼓励社区和用户提供或标注数据。
6. 跨领域数据集合并:整合不同领域和类型的数据集。
总体来说,虽然数据的质量和相关性是挑战,但随着技术的进步和创新方法的应用,可以有效地利用现有和新产生的数据资源,继续推动大型语言模型的发展。
澎湃科技:除了生成式AI,AGI是否会存在其他形式?AGI的下一阶段会是什么?
ChatGPT:当谈到AGI(人工通用智能)时,人们通常指的是具有类似人类一般智能水平的系统,具备多个领域的学习和适应能力。除了生成式AI,AGI的发展可能探索其他形式,例如:
集成式AI系统: 将不同领域的专业化AI系统整合,以实现更全面的智能。这可能涉及语言处理、视觉感知、决策制定等方面的协同工作。
融合多模态信息: 整合文本、图像、语音等多模态信息,使系统更全面地感知和理解世界。
迁移学习和元学习: 使AI系统能够更有效地从一个领域迁移到另一个领域,实现更灵活的学习和适应性。
关于AGI的下一阶段,这是一个难以准确预测的问题。一些研究者可能专注于提高系统的认知能力,使其能够更好地模拟人类的智能行为。同时,也可能出现更注重伦理、安全性和社会适应性的研究方向,以确保AGI的广泛应用是安全和有益的。AGI的发展方向将在未来的研究和技术创新中逐步揭晓。
澎湃科技:听说过百模之战吗?如何看待中国的大语言模型发展?
ChatGPT:“百模之战”是指中国在大型语言模型(LLM)领域的一系列活跃发展。中国的技术公司和研究机构在这一领域投入了大量资源,致力于开发与国际先进水平相媲美的语言模型。以下是对中国大语言模型发展的一些观点:
1. 技术创新:中国在人工智能领域有着强大的研发能力和技术创新潜力,特别是在自然语言处理(NLP)和机器学习领域。
2. 数据优势:中国拥有庞大的网民基数和丰富的语言数据资源,这为训练大型语言模型提供了有利条件。
3. 政策支持:中国政府对AI技术的发展给予了高度重视和支持,这有助于推动相关研究和应用的快速发展。
4. 应用场景丰富:中国市场的多样性为语言模型的实际应用提供了广泛的场景,从而促进了技术的快速迭代和优化。
5. 国际合作与竞争:中国的大语言模型发展不仅是国内竞争的结果,也受到国际技术发展的影响和激励。
6. 挑战与机遇:与全球其他地区一样,中国在发展大型语言模型时也面临着技术、伦理、法律等方面的挑战,但同时也拥有巨大的市场潜力和应用前景。
综上所述,中国在大型语言模型的发展上展现了强劲的动力和潜力。随着技术的进一步成熟和市场的深入开发,中国有可能在这一领域实现重要的突破和贡献。

相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章