

 新火种
2023-11-27
新火种
2023-11-27 


改进分子表征学习,清华团队提出知识引导的图Transformer预训练框架

学习有效的分子特征表征以促进分子特性预测,对于药物发现具有重要意义。最近,人们通过自监督学习技术预训练图神经网络(GNN)以克服分子特性预测中数据稀缺的挑战。然而,当前基于自监督学习的方法存在两个主要障碍:缺乏明确的自监督学习策略和 GNN 的能力有限。
近日,来自清华大学、西湖大学和之江实验室的研究团队,提出了知识引导的图 Transformer 预训练(Knowledge-guided Pre-training of Graph Transformer,KPGT),这是一种自监督学习框架,通过显著增强的分子表征学习提供改进的、可泛化和稳健的分子特性预测。KPGT 框架集成了专为分子图设计的图 Transformer 和知识引导的预训练策略,以充分捕获分子的结构和语义知识。
通过对 63 个数据集进行广泛的计算测试,KPGT 在预测各个领域的分子特性方面表现出了卓越的性能。此外,通过鉴定两种抗肿瘤靶点的潜在抑制剂验证了 KPGT 在药物发现中的实际适用性。总体而言,KPGT 可以为推进 AI 辅助药物发现过程提供强大且有用的工具。
该研究以《A knowledge-guided pre-training framework for improving molecular representation learning》为题,于 2023 年 11 月 21 日发布在《Nature Communications》上。

通过实验确定分子特性需要大量时间和资源,鉴定具有所需特性的分子是药物发现领域最重大的挑战之一。近年来,基于 AI 的方法在预测分子特性方面发挥着越来越重要的作用。基于 AI 的分子特性预测方法的主要挑战之一是分子的表征。
近年来,基于深度学习的方法的出现成为预测分子特性的潜在有用工具,主要是因为它们具有从简单输入数据中自动提取有效特征的卓越能力。值得注意的是,各种神经网络架构,包括循环神经网络(RNN)、卷积神经网络(CNN)和图神经网络(GNN)擅长对各种格式的分子数据进行建模,从简化的分子输入行输入系统(SMILES)到分子图像和分子图。然而,标记分子的有限可用性和化学空间的广阔限制了它们的预测性能,特别是在处理分布外数据样本时。
随着自监督学习方法在自然语言处理和计算机视觉领域取得的显著成就,这些技术已被用于预训练 GNN 并改进分子的表征学习,从而在下游分子性质预测任务中取得实质性改进。
研究人员假设将定量描述分子特征的额外知识引入自监督学习框架可以有效应对这些挑战。分子有许多定量特征,例如分子描述符和指纹,可以通过当前建立的计算工具轻松获得。整合这些额外的知识可以将丰富的分子语义信息引入自监督学习中,从而大大增强语义丰富的分子表征的获取。
现有的自监督学习方法通常依赖 GNN 作为骨干模型。然而,GNN 只能提供有限的模型容量。此外,GNN 可能很难捕获原子之间的远程交互。基于 Transformer 的模型已经成为游戏规则改变者。其特点是参数数量不断增加,并且能够捕获长程相互作用,为全面模拟分子的结构特征提供了有希望的途径。
自监督学习框架 KPGT在此,研究人员引入了一种自监督学习框架 KPGT,旨在增强分子表征学习,从而推进下游分子属性预测任务。KPGT 框架包含两个主要组件:称为 Line Graph Transformer (LiGhT) 的骨干模型和知识引导的预训练策略。KPGT 框架结合了 LiGhT 的高容量模型,该模型专门用于精确建模分子图结构,以及捕获分子结构和语义知识的知识引导预训练策略。
研究人员利用 ChEMBL29 数据集中的大约 200 万个分子使用知识引导的预训练策略对 LiGhT 进行预训练。
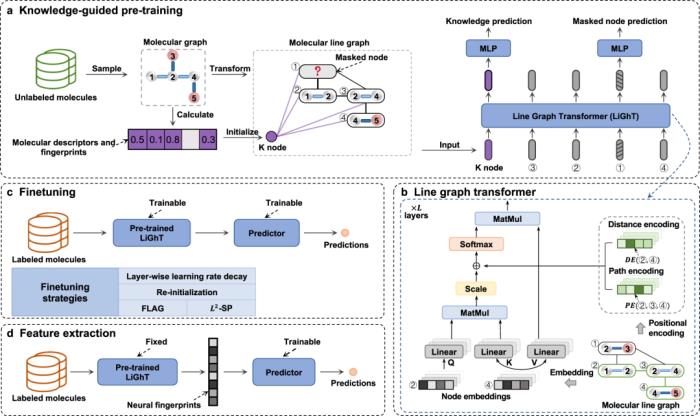
图示:KPGT 概述。(来源:论文)
KPGT 在分子性质预测方面优于基线方法。与几种基线方法相比,KPGT 在 63 个数据集上取得了很大的进步。
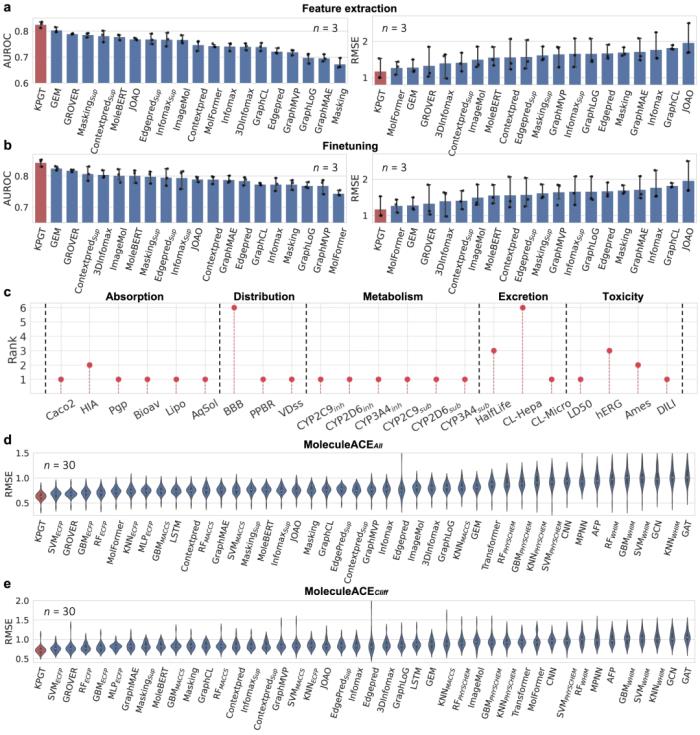
此外,通过成功利用 KPGT 识别造血祖细胞激酶 1 (HPK1) 和成纤维细胞生长因子受体 (FGFR1) 两个抗肿瘤靶点的潜在抑制剂,展示了 KPGT 的实际应用性。
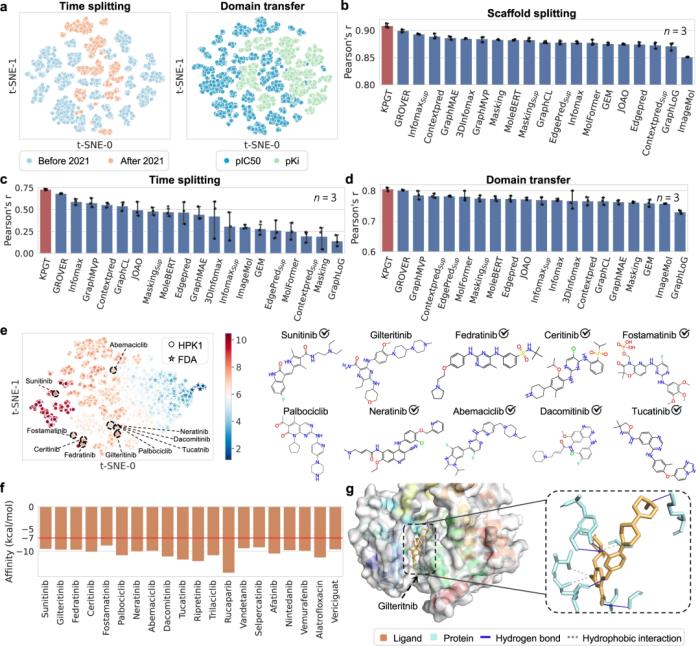
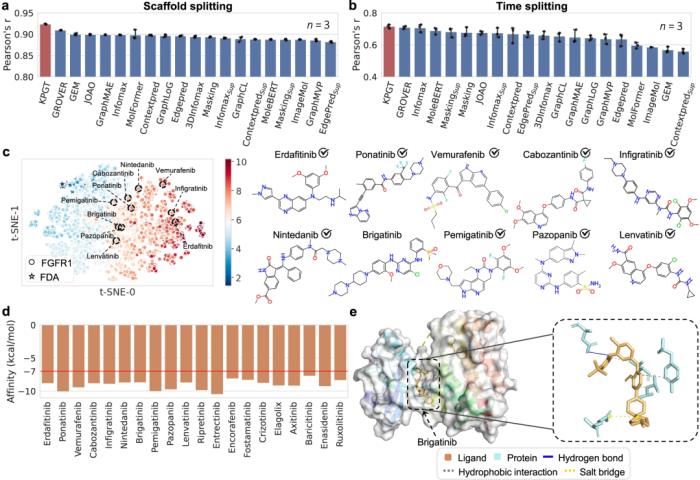
尽管 KPGT 在有效分子特性预测方面具有优势,但仍然存在一些局限性。
首先,附加知识的整合是所提方法最显著的特征。除了 KPGT 中使用的 200 个分子描述符和 512 个 RDKFP 之外,还有可能纳入各种其他类型的附加信息知识。此外,进一步的研究可以将三维 (3D) 分子构象整合到预训练过程中,从而使模型能够捕获有关分子的重要 3D 信息,并有可能增强表征学习能力。虽然 KPGT 目前采用具有大约 1 亿个参数的主干模型,以及对 200 万个分子的预训练,但探索更大规模的预训练可以为分子表征学习提供更实质性的好处。总的来说,KPGT 为有效的分子表征学习提供了强大的自监督学习框架,从而推动了人工智能辅助药物发现领域的发展。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









