

 新火种
2023-11-23
新火种
2023-11-23 


大模型扫盲系列——初识大模型
 大数据文摘受权转载自数据派THU
大数据文摘受权转载自数据派THU
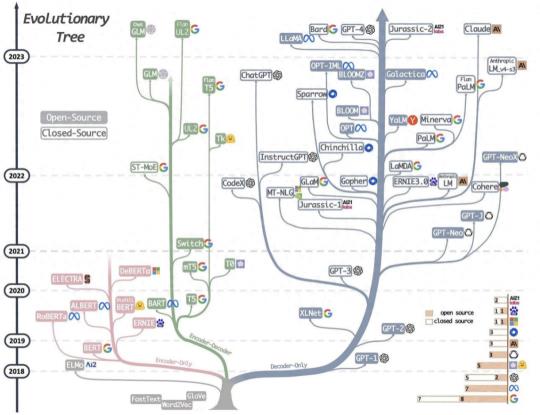
 当前流行的大模型的网络架构其实并没有很多新的技术,还是一直沿用当前NLP领域最热门最有效的架构——Transformer结构。相比于传统的循环神经网络(RNN)和长短时记忆网络(LSTM),Transformer具有独特的注意力机制(Attention),这相当于给模型加强理解力,对更重要的词能给予更多
当前流行的大模型的网络架构其实并没有很多新的技术,还是一直沿用当前NLP领域最热门最有效的架构——Transformer结构。相比于传统的循环神经网络(RNN)和长短时记忆网络(LSTM),Transformer具有独特的注意力机制(Attention),这相当于给模型加强理解力,对更重要的词能给予更多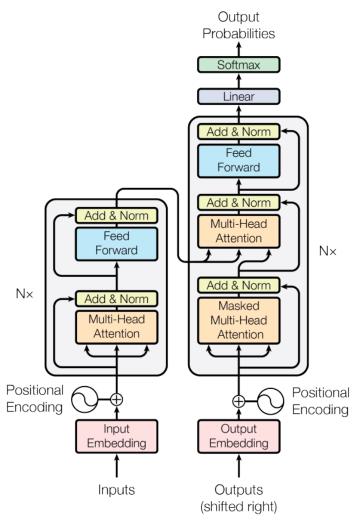 1)Encoder-Only,仅包含编码器部分,主要适用于不需要生成序列的任务,只需要对输入进行编码和处理的单向任务场景,如文本分类、情感分析等,这类代表是BERT相关的模型,例如BERT,RoBERT,ALBERT等训练三步骤
1)Encoder-Only,仅包含编码器部分,主要适用于不需要生成序列的任务,只需要对输入进行编码和处理的单向任务场景,如文本分类、情感分析等,这类代表是BERT相关的模型,例如BERT,RoBERT,ALBERT等训练三步骤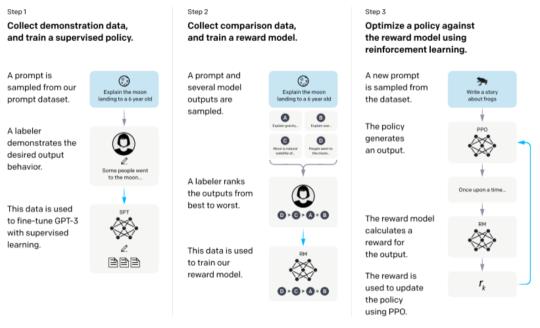 预训练是大模型训练的第一步,目的是让模型学习语言的统计模式和语义信息。主流的预训练阶段步骤基本都是近似的,其中最重要的就是数据,需要收集大量的无标注数据,例如互联网上的文本、新闻、博客、论坛等等。这些数据可以是多种语言的,并且需要经过一定的清洗和处理,以去除噪音,无关信息以及个人隐私相关的,最后会以tokenizer粒度输入到上文提到的语言模型中。这些数据经过清洗和处理后,用于训练和优化语言模型。预训练过程中,模型会学习词汇、句法和语义的规律,以及上下文之间的关系。OpenAI的ChatGPT4能有如此惊人的效果,主要的一个原因就是他们训练数据源比较优质。
预训练是大模型训练的第一步,目的是让模型学习语言的统计模式和语义信息。主流的预训练阶段步骤基本都是近似的,其中最重要的就是数据,需要收集大量的无标注数据,例如互联网上的文本、新闻、博客、论坛等等。这些数据可以是多种语言的,并且需要经过一定的清洗和处理,以去除噪音,无关信息以及个人隐私相关的,最后会以tokenizer粒度输入到上文提到的语言模型中。这些数据经过清洗和处理后,用于训练和优化语言模型。预训练过程中,模型会学习词汇、句法和语义的规律,以及上下文之间的关系。OpenAI的ChatGPT4能有如此惊人的效果,主要的一个原因就是他们训练数据源比较优质。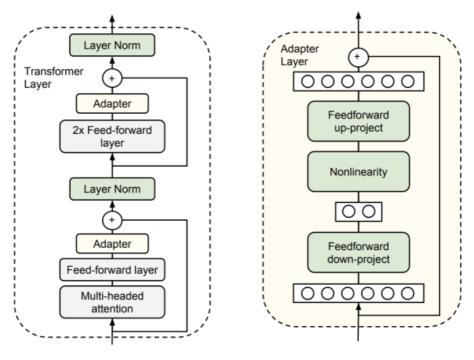
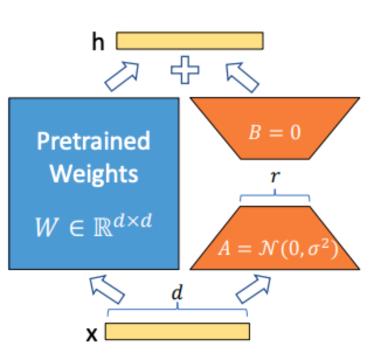 LoRA技术的引入使得在大规模预训练模型上进行微调更加高效和可行,为实际应用提供了更多可能性。
LoRA技术的引入使得在大规模预训练模型上进行微调更加高效和可行,为实际应用提供了更多可能性。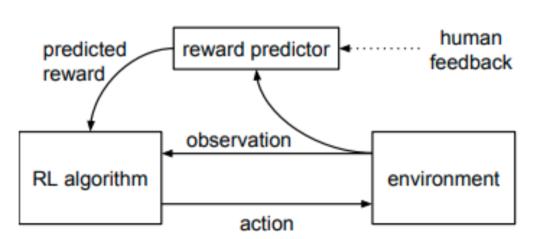 先收集一个提示词集合,并要求标注人员写出高质量的回复,然后使用该数据集以监督的方式微调预训练的基础模型。
先收集一个提示词集合,并要求标注人员写出高质量的回复,然后使用该数据集以监督的方式微调预训练的基础模型。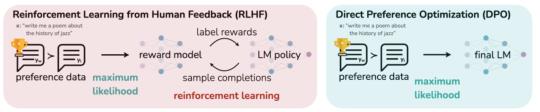
 Prompt
Prompt
 大模型应用
大模型应用 5)公司业务定制化大模型:大模型具有通用性能力,但是在很多零样本的场景的表现依然比不上那个领域正在使用的产品,例如在某些垂直领域,包括工业领域,医药领域,管理领域等场景下进行专业问题,研究型问题的使用依然需要特定场景的数据进行微调,这种定制化的服务也能给企业带来巨大的效率提升和节省成本的收益,属于比较有前景的业务。
5)公司业务定制化大模型:大模型具有通用性能力,但是在很多零样本的场景的表现依然比不上那个领域正在使用的产品,例如在某些垂直领域,包括工业领域,医药领域,管理领域等场景下进行专业问题,研究型问题的使用依然需要特定场景的数据进行微调,这种定制化的服务也能给企业带来巨大的效率提升和节省成本的收益,属于比较有前景的业务。 大模型也存在一些现实挑战:
大模型也存在一些现实挑战:相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










