新火种
2023-11-17
新火种
2023-11-17 


斯坦福马腾宇创业,大模型方向,Manning、ChristopherRé是顾问
机器之能报道
编辑:吴昕
10月31日,清华大学 2012 届姚班校友,现任斯坦福大学助理教授马腾宇在社交媒体上宣布创业消息,成立 Voyage AI ——一家致力于构建嵌入/矢量化模型,帮助大型语言模型( LLM )获得更好检索质量的初创。
Voyage AI 联合创始人兼 CEO 马腾宇介绍道,Voyage 团队由一群才华横溢的人工智能研究人员组成,包括斯坦福大学教授以及来自斯坦福大学、MIT的博士。公司希望赋能客户构建更好的 RAG 应用程序,也提供定制化服务,将客户LLM产品准确率提升「10-20% 。」检索增强生成,通常称为 RAG,是一种强大的聊天机器人的设计模式,其中,检索系统实时获取与查询相关的经过验证的源/文档,并将其输入生成模型(例如 GPT-4 )以生成响应。我们知道,聊天机器人的有效性取决于它提取的文档的准确性和相关性。如果它检索到的内容,除了确切信息还包括其他不相关信息,LLM 就可能会产生幻觉。嵌入,作为文档和查询的表示或「索引」,它们负责确保检索到的文档包含与查询相关的信息,也直接影响 RAG 的质量。有了高质量的检索数据,RAG 可以确保生成的响应不仅是智能的,而且在上下文中是准确和知情的。
官宣当天,Voyage AI 还发布了一种新的最先进的嵌入模型和 API(比OpenAI 更优)。
官网显示,公司学术顾问包括斯坦福大学教授 Christopher Manning、斯坦福大学副教授 Christopher Ré 以及斯坦福大学首位红杉讲席教授李飞飞。
 斯坦福大学首位红杉讲席教授李飞飞对公司成立表示祝福。
斯坦福大学首位红杉讲席教授李飞飞对公司成立表示祝福。
 马腾宇在普林斯顿大学读博时的导师Sanjeev Arora教授对公司的成立表示祝贺。一、被低估的嵌入模型探索尽管生成式人工智能最近取得了显著进步,但是,嵌入模型相对不受重视和探索。Voyage AI 正在尝试解决这个问题。公司团队在斯坦福人工智能实验室和麻省理工学院 NLP 小组就训练嵌入模型进行了 5 年多的前沿研究。他们获得了一个 SOTA 模型——比任何其他公开可用的模型具有更高的检索精度,更长的上下文窗口、更低延迟和以更实惠的价格进行高效推理。在大量文本嵌入基准测试 MTEB 上,公司通用嵌入模型 voyage-01 优于 OpenAI 最新的文本嵌入模型 5 个点以上!(见下左图。)
马腾宇在普林斯顿大学读博时的导师Sanjeev Arora教授对公司的成立表示祝贺。一、被低估的嵌入模型探索尽管生成式人工智能最近取得了显著进步,但是,嵌入模型相对不受重视和探索。Voyage AI 正在尝试解决这个问题。公司团队在斯坦福人工智能实验室和麻省理工学院 NLP 小组就训练嵌入模型进行了 5 年多的前沿研究。他们获得了一个 SOTA 模型——比任何其他公开可用的模型具有更高的检索精度,更长的上下文窗口、更低延迟和以更实惠的价格进行高效推理。在大量文本嵌入基准测试 MTEB 上,公司通用嵌入模型 voyage-01 优于 OpenAI 最新的文本嵌入模型 5 个点以上!(见下左图。)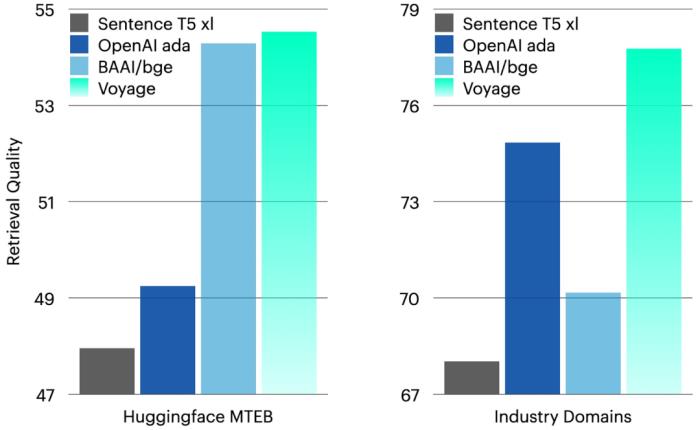 公司通用嵌入模型 voyage-01 优于 OpenAI 最新的文本嵌入模型 5 个点以上(左)。其模型也将在未来几个月内迅速改进。在自建的另外几个数据集 RWID 上,表现依然领先(右)。不过,Voyage AI 认为 MTEB 现在有点过度使用,因为人们有时会在这些数据集上训练基础嵌入(尽管他们不这样做)。为了进行更全面的评估,他们另外构建了 9 个数据集 ,称作 RWID(real-world industry domains),范围覆盖从技术文档到餐厅评论和新闻。结果发现,公司的基本模型表现比 OpenAI 的嵌入和所有其他流行的开源模型都要好。
公司通用嵌入模型 voyage-01 优于 OpenAI 最新的文本嵌入模型 5 个点以上(左)。其模型也将在未来几个月内迅速改进。在自建的另外几个数据集 RWID 上,表现依然领先(右)。不过,Voyage AI 认为 MTEB 现在有点过度使用,因为人们有时会在这些数据集上训练基础嵌入(尽管他们不这样做)。为了进行更全面的评估,他们另外构建了 9 个数据集 ,称作 RWID(real-world industry domains),范围覆盖从技术文档到餐厅评论和新闻。结果发现,公司的基本模型表现比 OpenAI 的嵌入和所有其他流行的开源模型都要好。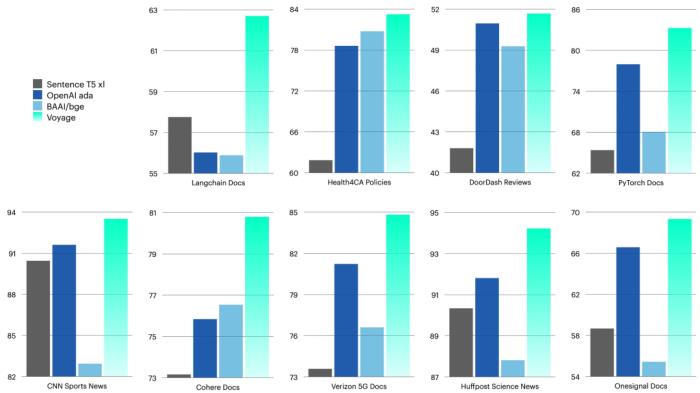 Voyage AI 构建了 9 个额外的数据集 RWID(real-world industry domains),范围从技术文档到餐厅评论和新闻。结果发现,基本模型的表现比 OpenAI 的嵌入和所有其他流行的开源模型都要好。在大模型时代,采用 RAG 架构的 LLM 应用,不仅能尽量减少大模型幻觉,也是破解决知识时效、超长文本等大模型本身制约和不足的必要技术。
Voyage AI 构建了 9 个额外的数据集 RWID(real-world industry domains),范围从技术文档到餐厅评论和新闻。结果发现,基本模型的表现比 OpenAI 的嵌入和所有其他流行的开源模型都要好。在大模型时代,采用 RAG 架构的 LLM 应用,不仅能尽量减少大模型幻觉,也是破解决知识时效、超长文本等大模型本身制约和不足的必要技术。
6月,红杉资本发布了一篇关于大语言模型技术栈的文章 The New Language Model Stack,采访了 33 家公司——从种子阶段的初创公司到大型上市企业。有 88% 受访者表示,检索机制(如向量数据库)仍将是其堆栈的关键部分。
检索模型的相关上下文以进行推理有助于提高结果质量,减少「幻觉」(不准确),并解决数据新鲜度问题。有些使用专门构建的矢量数据库(Pinecone、Weaviate、Chroma、Qdrant、Milvus 等),而另一些则使用 pgvector 或 AWS 产品。
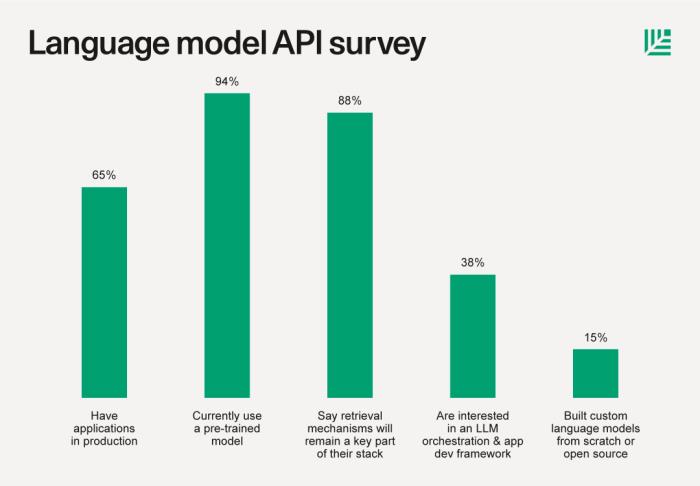 88% 受访者表示,检索机制(如向量数据库)仍将是其堆栈的关键部分。同样在 6 月,著名硅谷风险投资机构 A16Z 在 Emerging Architectures for LLM Applications一文中梳理了新兴的 LLM 应用堆栈的架构。
88% 受访者表示,检索机制(如向量数据库)仍将是其堆栈的关键部分。同样在 6 月,著名硅谷风险投资机构 A16Z 在 Emerging Architectures for LLM Applications一文中梳理了新兴的 LLM 应用堆栈的架构。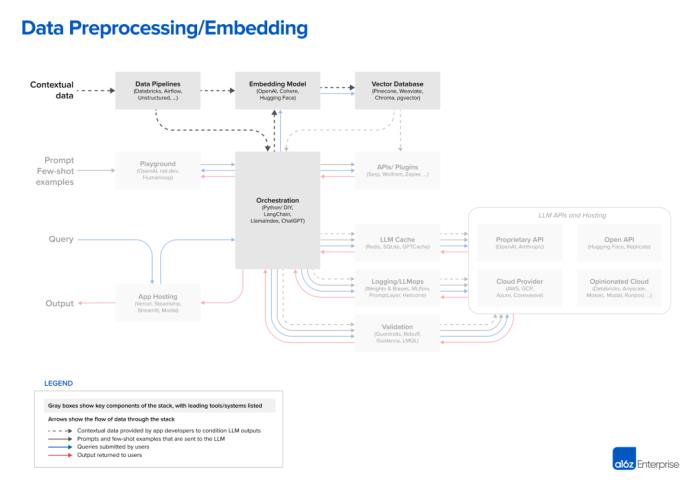
其中针对数据预处理/嵌入环节,文章写道,「对于嵌入,大多数开发人员使用 OpenAI API,特别是 text-embedding-ada-002 模型。它易于使用(特别是如果您已经在使用其他 OpenAI API),提供相当不错的结果,并且变得越来越便宜。一些大型企业也在探索 Cohere,它更专注于产品工作,更专注于嵌入,并且在某些场景下具有更好的性能。对于喜欢开源的开发人员来说,Hugging Face 的 Sentence Transformer 库是一个标准。还可以针对不同的用例创建不同类型的嵌入;这在今天是一个利基实践,但是一个很有前途的研究领域。」其实更早之前,OpenAI 研究科学家 Andrej Karpathy 就在微软 Build 2023 大会主题演讲中谈到了通过一些工具和插件为 LLM 提供额外的功能或资源,以提高其性能。他也提到未来对更通用技术的探索,包括开发检索增强模型。不过,现实世界的场景总是比学术更具挑战性,毕竟每个行业都有其独特的术语和知识库。目前, Voyage 也提供为编程和金融领域量身定制的嵌入模型,接下来将服务更多行业。Voyage AI 表示,还可以微调小型、未标记的公司特定数据集上的嵌入,为 LangChain、OneSignal、Druva 和 Galpha 等试点客户提升 10-20% 准确率。
 马腾宇表示,已经将价格降低到与 OpenAI ada 相同,还将免费试用从 5K 文档增加到至少 5000 万 tokens 。二、关于马腾宇清华大学 2012 届姚班校友,现任斯坦福大学助理教授,博士曾就读于普林斯顿大学,师从 Sanjeev Arora 教授,其主要研究兴趣为机器学习和算法方面的研究,课题包括非凸优化、深度学习及其理论、强化学习、表示学习、分布式优化、凸松弛、高维统计等。2021年,马腾宇获斯隆研究奖(Sloan Research Fellowships),该奖项素有诺奖风向标的美誉,旨在奖励职业生涯早期的杰出青年学者。2018 年,马腾宇与人合作的论文 Algorithmic Regularization in Over-parameterized Matrix Sensing and Neural Networks with Quadratic Activations 发表在 COLT,并获得最佳论文奖。同一年,马腾宇获 2018 ACM 博士论文奖荣誉奖( Honorable Mentions )。其博士论文 Non-convex Optimization for Machine Learning: Design, Analysis, and Understanding 试图理解为什么 non-convex optimization 可以解决机器学习问题,而在此之前几乎没有这方面的研究。其实,早在2012 - 2013年马腾宇开始读博士时,深度学习浪潮兴起,他逐渐意识到深度学习会是下一个大趋势。而理解深度学习算法原理挑战之一就是如何优化损失函数 (Loss Function),使其变得非凸。马腾宇也因此成为最早一批专注解决这一挑战的科研人员之一。「我目前的研究重点是机器学习理论,尤其是深度学习理论,并致力于将理论知识转化为实际应用。」2020年初,马腾宇在接受 Robin.ly 主持人 Margaret Laffan 专访时谈道。在专注技术突破的同时也必须确保所有的算法在实际应用中都是安全、可靠、可解释的。Voyage AI 表示很快还会推出更多模型。现在,大家即可访问 voyage-01。
马腾宇表示,已经将价格降低到与 OpenAI ada 相同,还将免费试用从 5K 文档增加到至少 5000 万 tokens 。二、关于马腾宇清华大学 2012 届姚班校友,现任斯坦福大学助理教授,博士曾就读于普林斯顿大学,师从 Sanjeev Arora 教授,其主要研究兴趣为机器学习和算法方面的研究,课题包括非凸优化、深度学习及其理论、强化学习、表示学习、分布式优化、凸松弛、高维统计等。2021年,马腾宇获斯隆研究奖(Sloan Research Fellowships),该奖项素有诺奖风向标的美誉,旨在奖励职业生涯早期的杰出青年学者。2018 年,马腾宇与人合作的论文 Algorithmic Regularization in Over-parameterized Matrix Sensing and Neural Networks with Quadratic Activations 发表在 COLT,并获得最佳论文奖。同一年,马腾宇获 2018 ACM 博士论文奖荣誉奖( Honorable Mentions )。其博士论文 Non-convex Optimization for Machine Learning: Design, Analysis, and Understanding 试图理解为什么 non-convex optimization 可以解决机器学习问题,而在此之前几乎没有这方面的研究。其实,早在2012 - 2013年马腾宇开始读博士时,深度学习浪潮兴起,他逐渐意识到深度学习会是下一个大趋势。而理解深度学习算法原理挑战之一就是如何优化损失函数 (Loss Function),使其变得非凸。马腾宇也因此成为最早一批专注解决这一挑战的科研人员之一。「我目前的研究重点是机器学习理论,尤其是深度学习理论,并致力于将理论知识转化为实际应用。」2020年初,马腾宇在接受 Robin.ly 主持人 Margaret Laffan 专访时谈道。在专注技术突破的同时也必须确保所有的算法在实际应用中都是安全、可靠、可解释的。Voyage AI 表示很快还会推出更多模型。现在,大家即可访问 voyage-01。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。