

 新火种
2023-11-14
新火种
2023-11-14 


破解自注意力推理缺陷的奥秘,蚂蚁自研新一代Transformer或实现无损外推
随着大语言模型的快速发展,其长度外推能力(length extrapolating)正日益受到研究者的关注。尽管这在 Transformer 诞生之初,被视为天然具备的能力,但随着相关研究的深入,现实远非如此。传统的 Transformer 架构在训练长度之外无一例外表现出糟糕的推理性能。研究人员逐渐意识到这一缺陷可能与位置编码(position encoding)有关,由此展开了绝对位置编码到相对位置编码的过渡,并产生了一系列相关的优化工作,其中较为代表性的,例如:旋转位置编码(RoPE)(Su et al., 2021)、Alibi (Press et al., 2021)、Xpos (Sun et al., 2022) 等,以及近期 meta 研发的位置插值(PI)(Chen et al., 2023),reddit 网友给出的 NTK-aware Scaled RoPE (bloc97, 2023),都在试图让模型真正具备理想中的外推能力。然而,当研究人员全力将目光放在位置编码这一众矢之的上时,却忽视了 Transformer 中另一个重量级角色 --self-attention 本身。蚂蚁人工智能团队最新研究表明,这一被忽视的角色,极有可能成为扭转局势的关键。Transformer 糟糕的外推性能,除了位置编码外,self-attention 本身仍有诸多未解之谜。基于此发现,蚂蚁人工智能团队自研了新一代注意力机制,在实现长度外推的同时,模型在具体任务上的表现同样出色。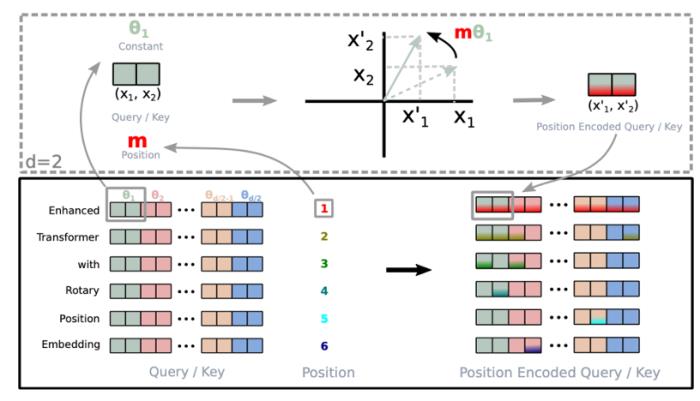
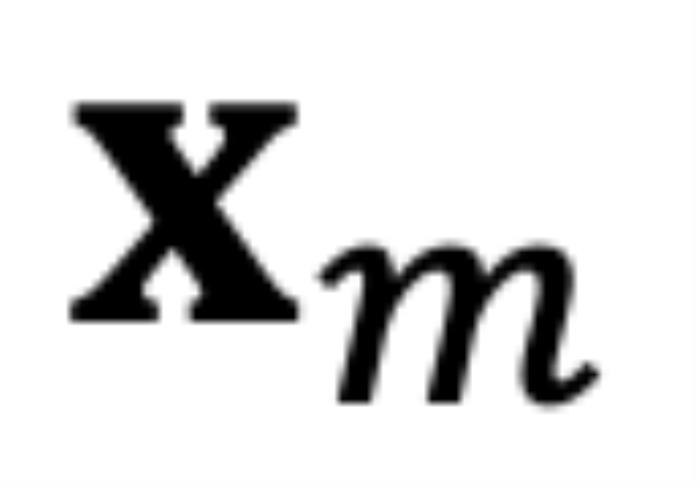 和
和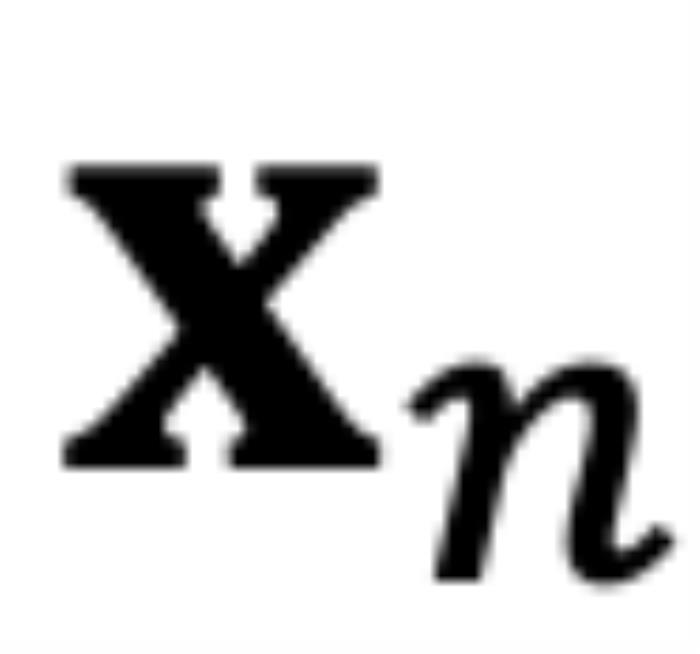 ,分别代表输入序列中的m个和第n个位置索引对应的 token,其 query 和 key 分别为
,分别代表输入序列中的m个和第n个位置索引对应的 token,其 query 和 key 分别为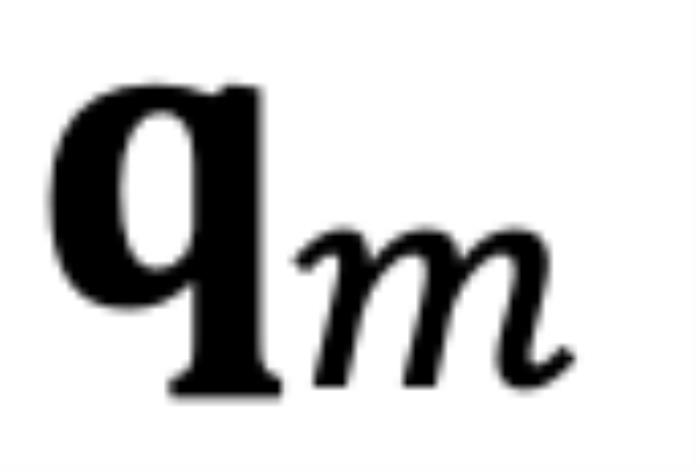 和
和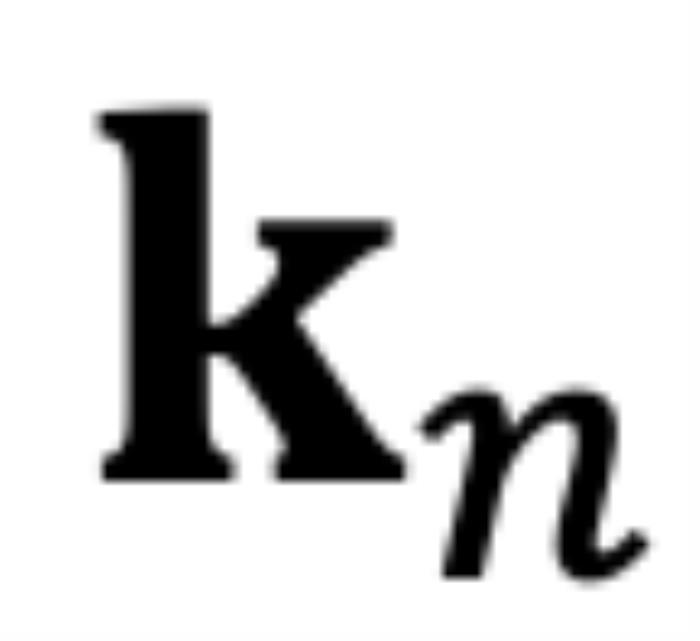 。它们之间的注意力可以表示为一个函数
。它们之间的注意力可以表示为一个函数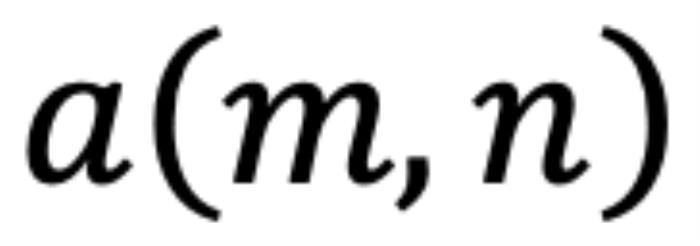 ,如果应用 RoPE,则可以进一步简化为仅依赖于m和n相对位置的函数
,如果应用 RoPE,则可以进一步简化为仅依赖于m和n相对位置的函数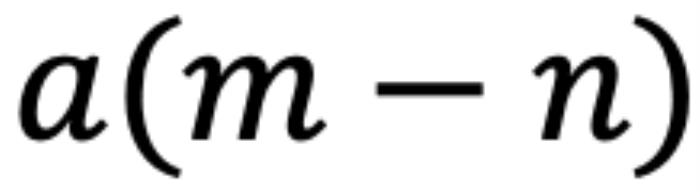 。从数学角度看,
。从数学角度看,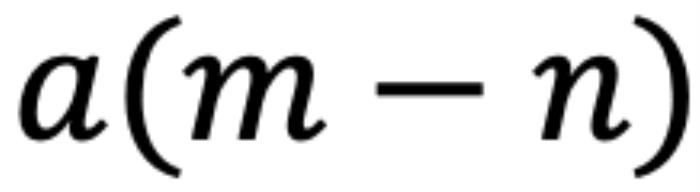 可以解释为
可以解释为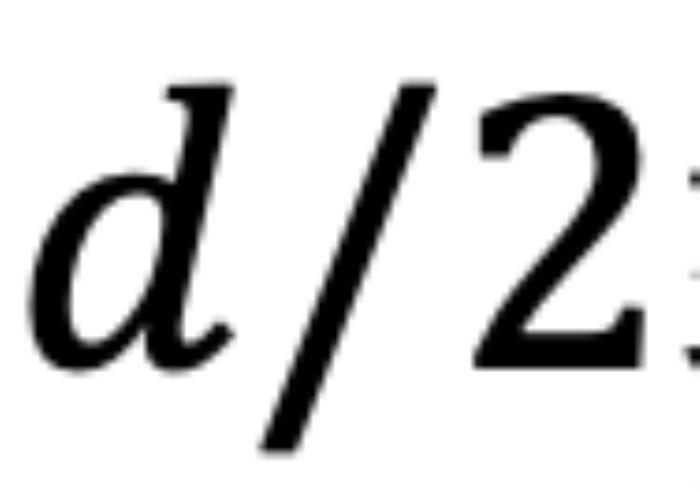 组复数(
组复数(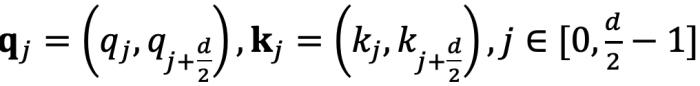 ,其中d为 hidden dimension 维度,省略位置索引m,n)经过旋转后的内积之和。这在直觉上是有意义的,因为位置距离可以建模为一种序,并且两个复数的内积随着旋转角度
,其中d为 hidden dimension 维度,省略位置索引m,n)经过旋转后的内积之和。这在直觉上是有意义的,因为位置距离可以建模为一种序,并且两个复数的内积随着旋转角度 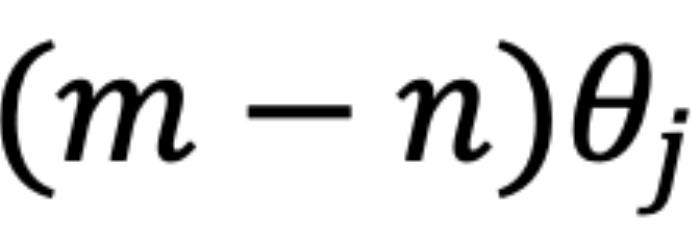 的变化而变化,以图 5 为例,其中
的变化而变化,以图 5 为例,其中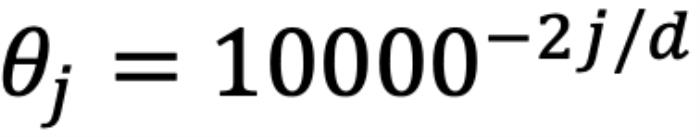 ,
,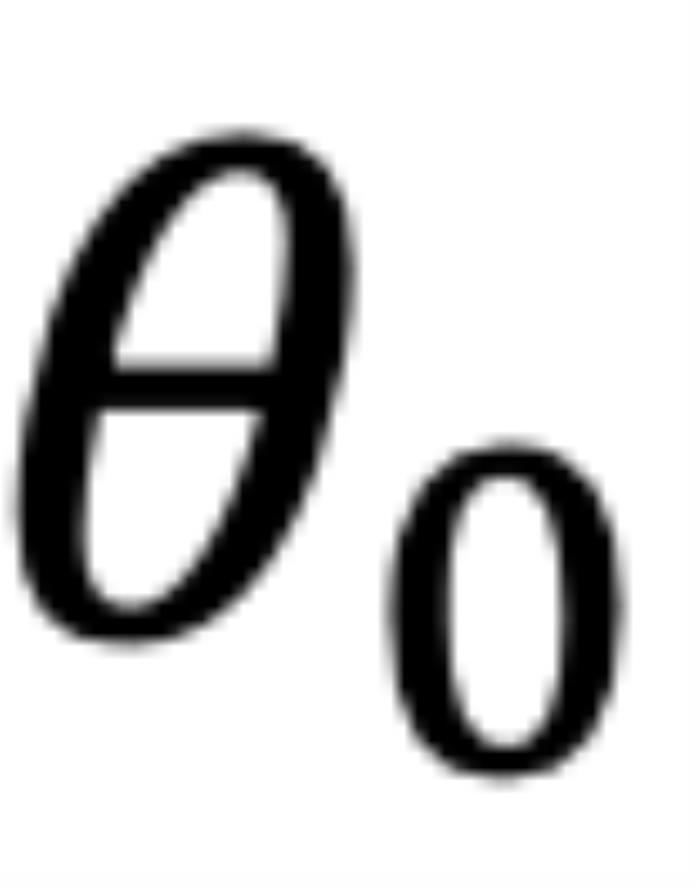 为
为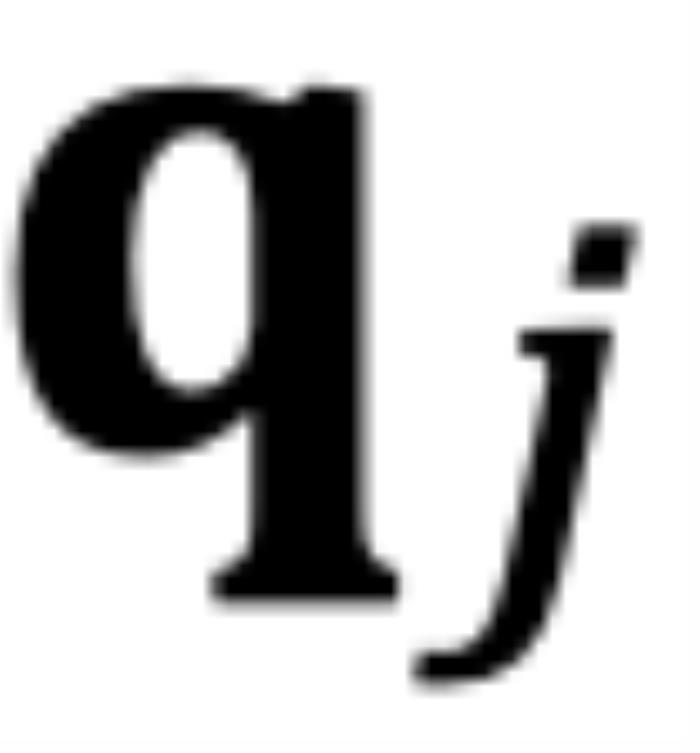 和
和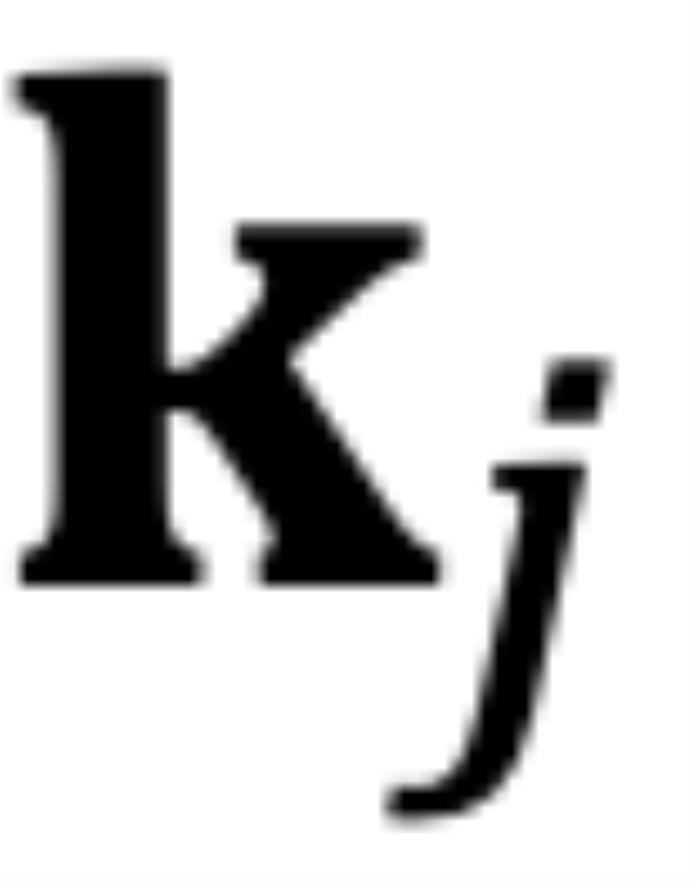 的初始夹角。然而,它隐藏着一个此前一直被忽略的技术缺陷。为了便于理解,我们首先考虑双向注意力模型,例如 Bert (Devlin et al., 2019) 和 GLM (Du et al., 2021) 等。如图 5 所示,对于
的初始夹角。然而,它隐藏着一个此前一直被忽略的技术缺陷。为了便于理解,我们首先考虑双向注意力模型,例如 Bert (Devlin et al., 2019) 和 GLM (Du et al., 2021) 等。如图 5 所示,对于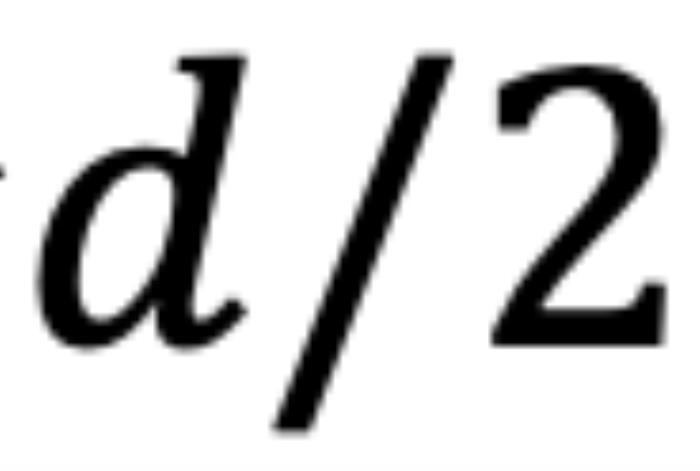 组复数中的任意一组
组复数中的任意一组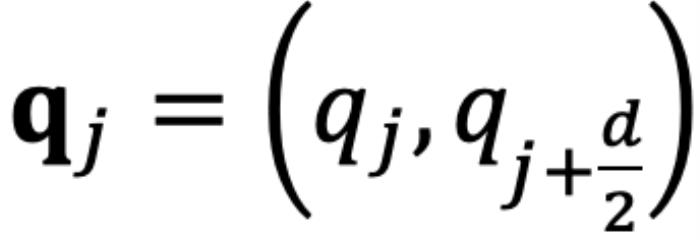 ,
,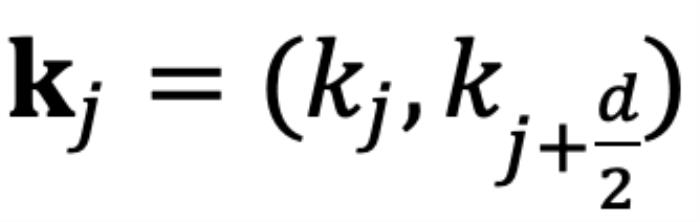 ,它们分别具有位置索引m和n。不失一般性,我们假设复平面上有一个小于
,它们分别具有位置索引m和n。不失一般性,我们假设复平面上有一个小于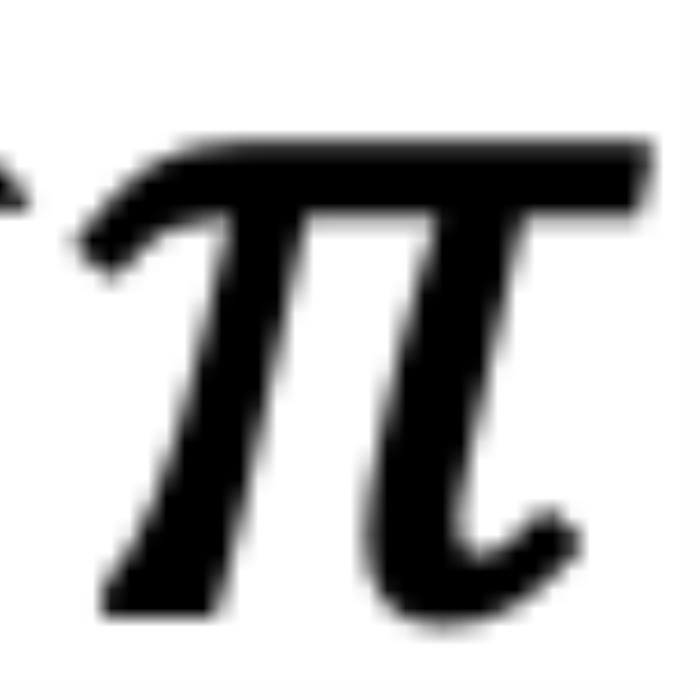 的角度
的角度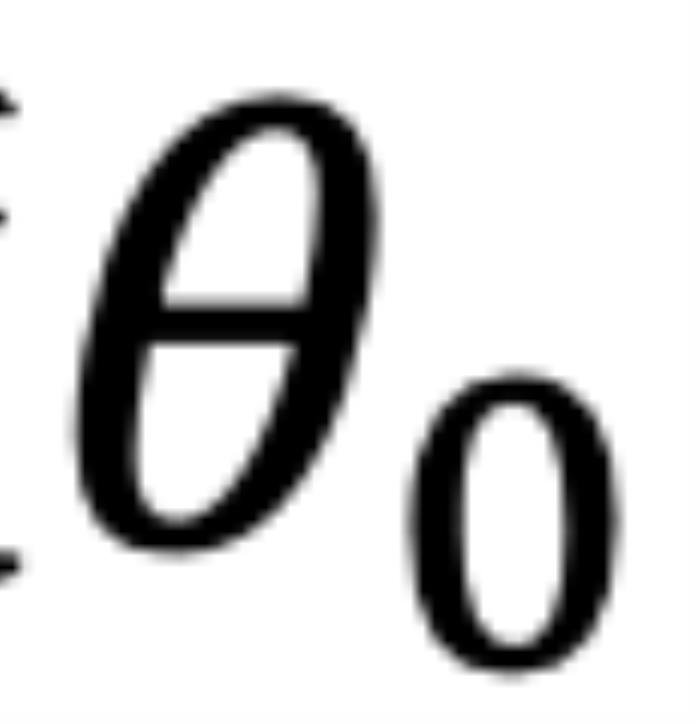 逆时针从
逆时针从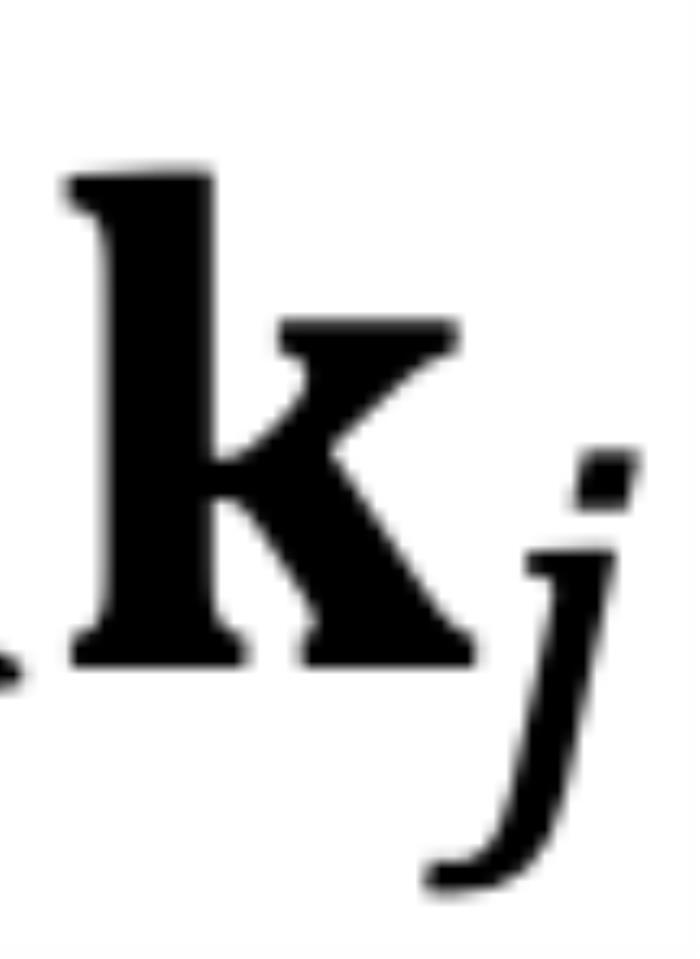 旋转到
旋转到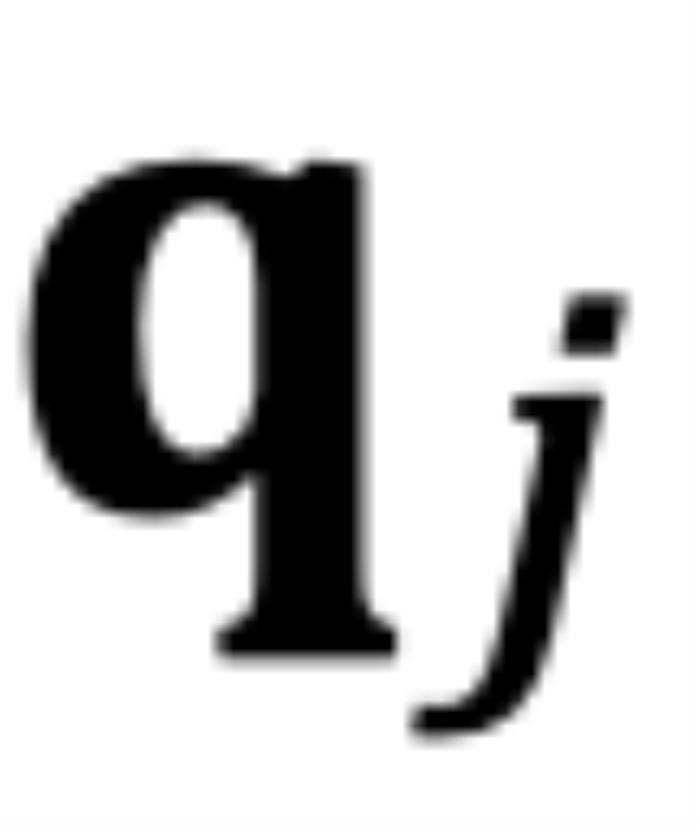 ,那么它们的位置关系有两种可能的情况(不考虑 =,因为它是平凡的)。正常保序关系:当
,那么它们的位置关系有两种可能的情况(不考虑 =,因为它是平凡的)。正常保序关系:当 时,如图 5 右侧所示。注意力分数随着位置距离的增加而降低(直到它们相对角度超出
时,如图 5 右侧所示。注意力分数随着位置距离的增加而降低(直到它们相对角度超出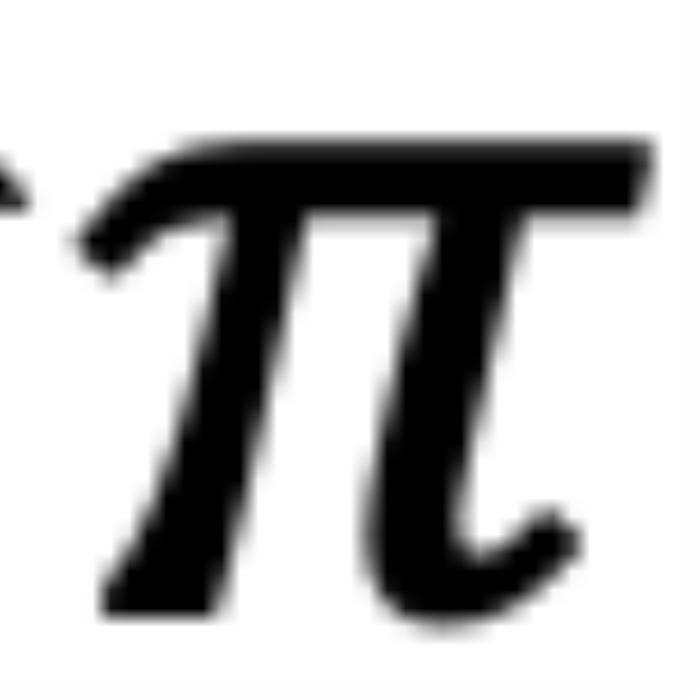 ,超出
,超出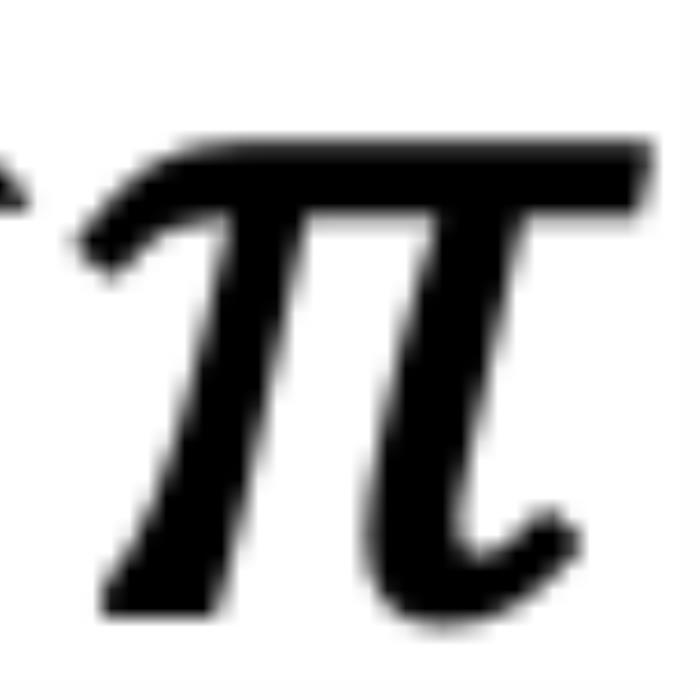 的这部分在原论文附录中进行了讨论 (Zhu et al., 2023))。异常行为:然而,当
的这部分在原论文附录中进行了讨论 (Zhu et al., 2023))。异常行为:然而,当 时,如图 5 左侧所示,异常行为打乱了
时,如图 5 左侧所示,异常行为打乱了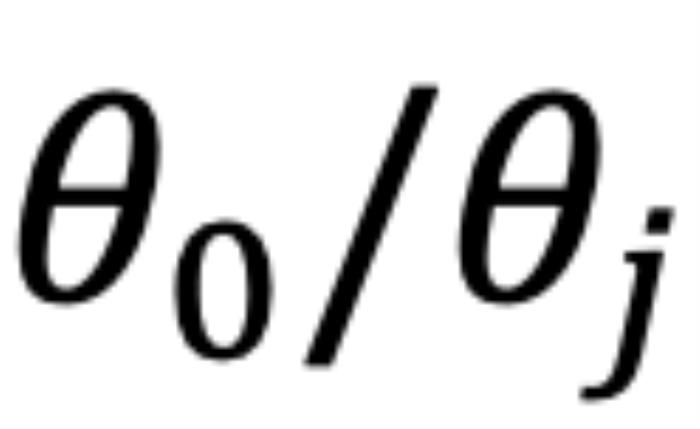 个最邻近的 token 的序。当
个最邻近的 token 的序。当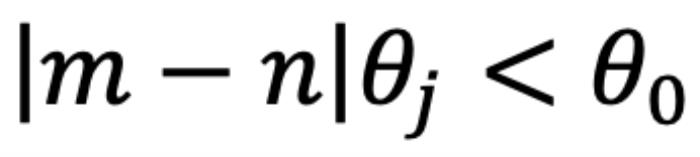 时,
时,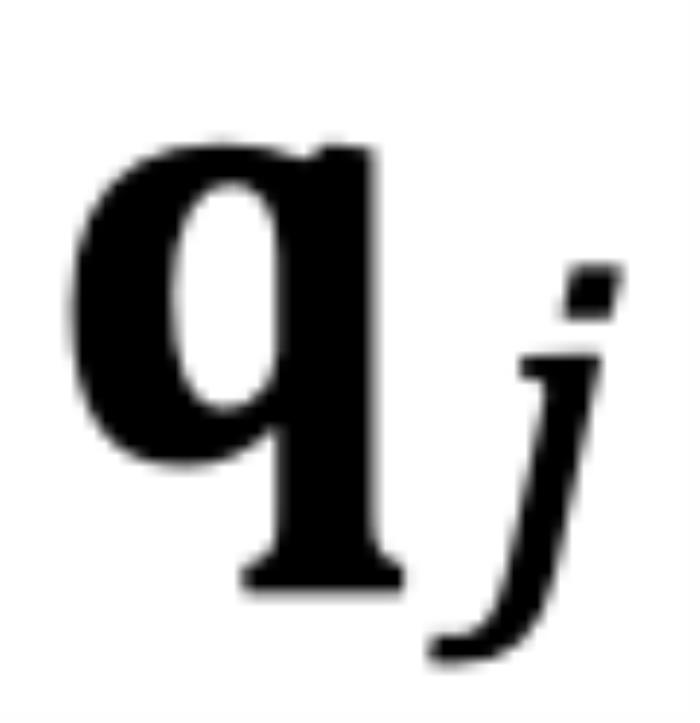 和
和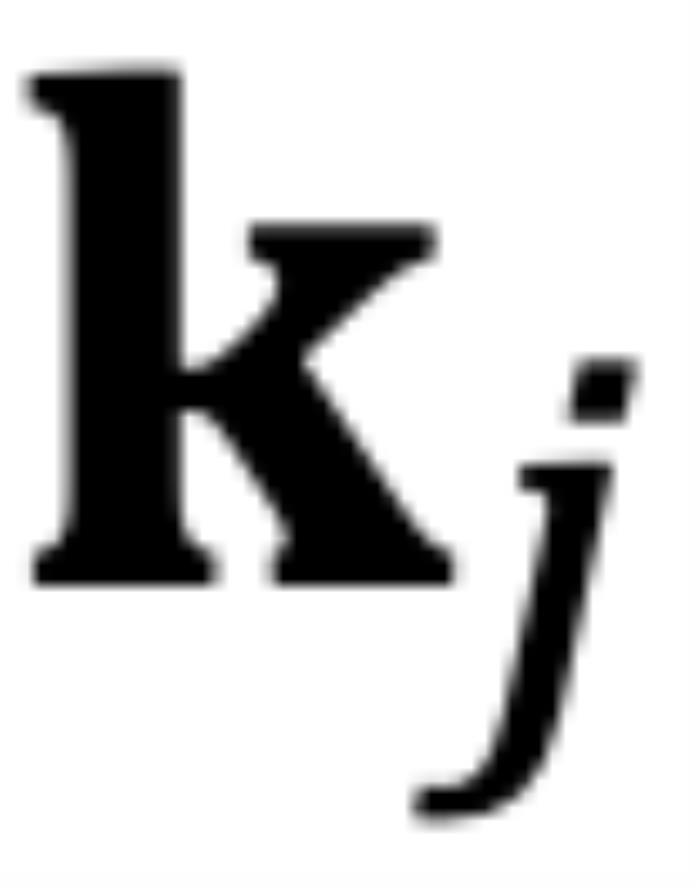 之间的相对角度将随着
之间的相对角度将随着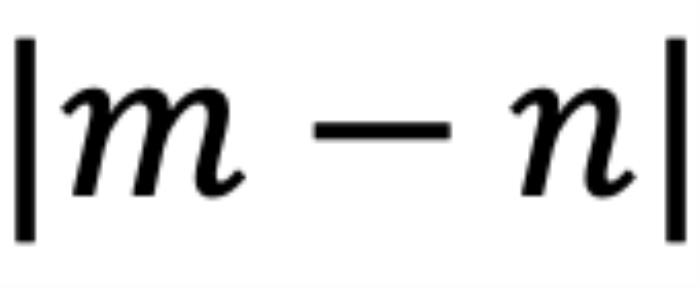 的增大而减小,这意味着最接近的 token 可能会获得较小的注意力分数。(我们在这里使用 “可能”,因为注意力分数是
的增大而减小,这意味着最接近的 token 可能会获得较小的注意力分数。(我们在这里使用 “可能”,因为注意力分数是 个内积的总和,也许其中一个是微不足道的。但是,后续实验证实了这一重要性。)并且,无论应用 PI 还是 NTK-aware Scaled RoPE,均无法消除这一影响。
个内积的总和,也许其中一个是微不足道的。但是,后续实验证实了这一重要性。)并且,无论应用 PI 还是 NTK-aware Scaled RoPE,均无法消除这一影响。 的角度
的角度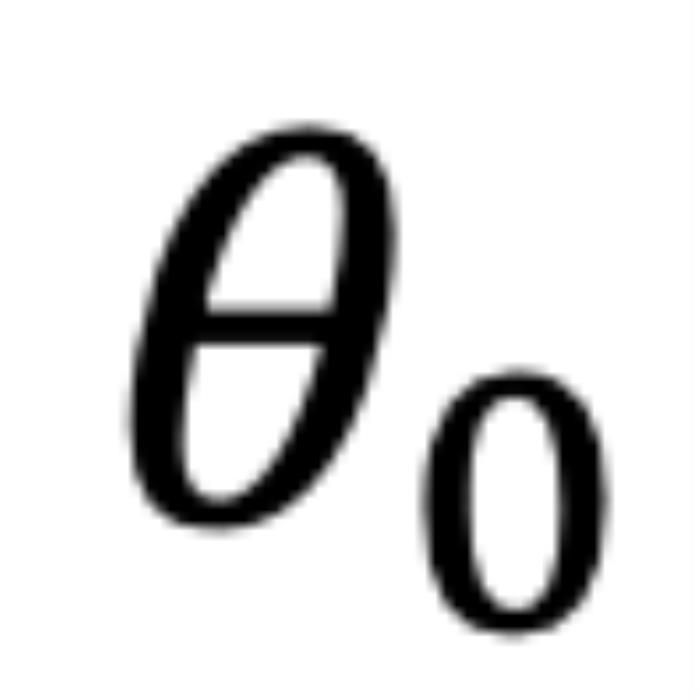 从
从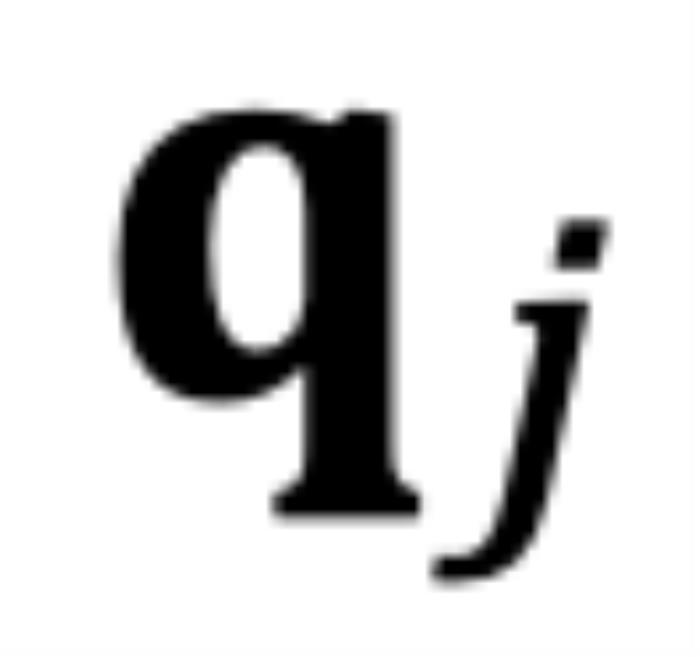 逆时针旋转到
逆时针旋转到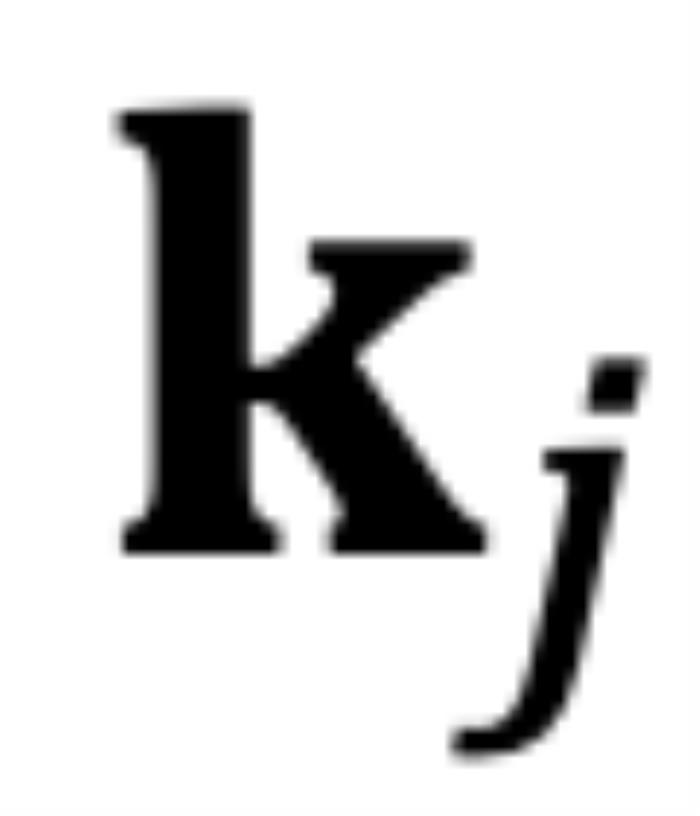 时,而不是从
时,而不是从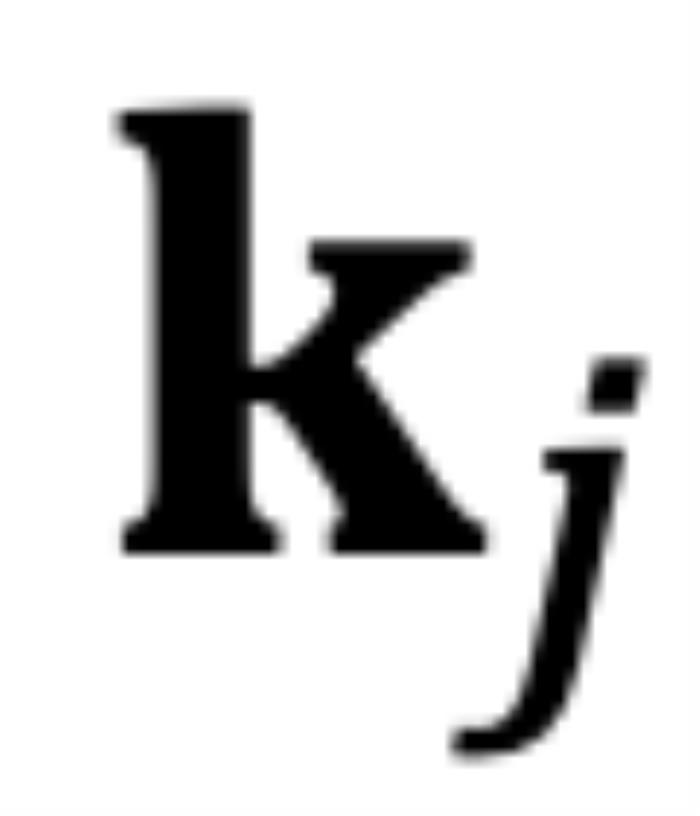 到
到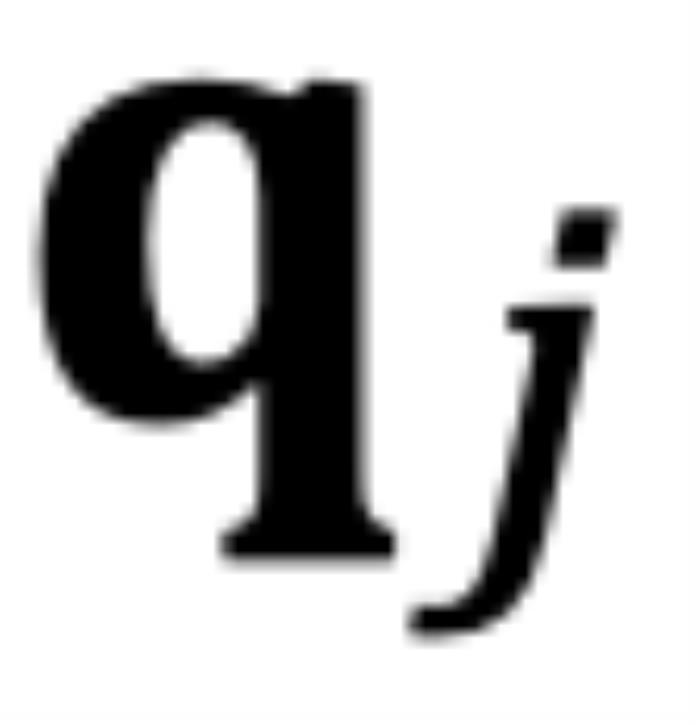 。
。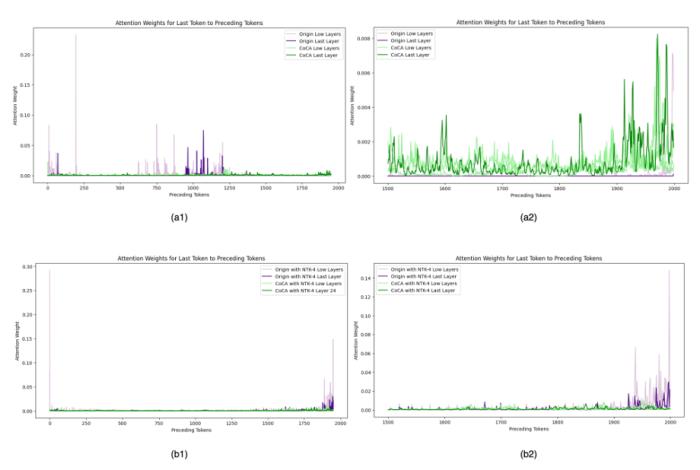 图11. 外推中的注意力得分,引自(Zhu et al., 2023)Human Eval在论文之外,我们使用相同的数据(120B token),相同的模型规模(1.3B),相同训练配置,基于 CoCA 和 Origin 模型进一步评测了 human eval 上的表现,与 Origin 模型对比如下:跟 Origin 模型比起来,两者水平相当,CoCA 并没有因为外推能力而导致模型表达能力产生损失。Origin 模型在 python、java 的表现比其他语言好很多,在 go 上表现较差,CoCA 的表现相对平衡,这与训练语料中 go 的语料较少有关,说明 CoCA 可能有潜在的小样本学习能力。
图11. 外推中的注意力得分,引自(Zhu et al., 2023)Human Eval在论文之外,我们使用相同的数据(120B token),相同的模型规模(1.3B),相同训练配置,基于 CoCA 和 Origin 模型进一步评测了 human eval 上的表现,与 Origin 模型对比如下:跟 Origin 模型比起来,两者水平相当,CoCA 并没有因为外推能力而导致模型表达能力产生损失。Origin 模型在 python、java 的表现比其他语言好很多,在 go 上表现较差,CoCA 的表现相对平衡,这与训练语料中 go 的语料较少有关,说明 CoCA 可能有潜在的小样本学习能力。

HuggingFace:敬请期待
背景知识在深入探讨之前,我们快速回顾一些核心的背景知识。长度外推 (Length Extrapolating)长度外推是指大语言模型在处理比其训练数据中更长的文本时的能力。在训练大型语言模型时,通常有一个最大的序列长度,超过这个长度的文本需要被截断或分割。但在实际应用中,用户可能会给模型提供比训练时更长的文本作为输入,如果模型欠缺长度外推能力或者外推能力不佳,这将导致模型产生无法预期的输出,进而影响模型实际应用效果。自注意力 (Self-Attention)(Vaswani et al., 2017) 于 2017 年提出的 multi-head self-attention,作为如今大语言模型的内核,对于推动人工智能领域的发展起到了举足轻重的作用。这里以下图 1 给出形象化的描述,这项工作本身已经被广泛认可,这里不再进行赘述。初次接触大语言模型,对这项工作不甚了解的读者可以前往原论文获取更多细节 (Vaswani et al., 2017)。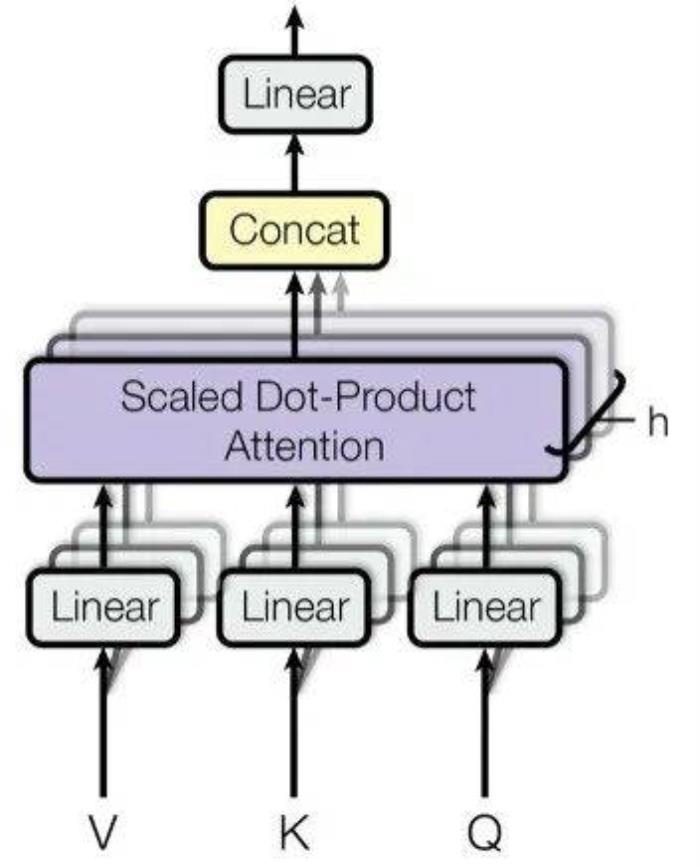
图1. 多头注意力机制示意图,引自(Vaswani, et al., 2017)。
位置编码 (Position encoding)由于 self-attention 机制本身并不直接处理序列中的位置信息,因此引入位置编码成为必要。由于传统的 Transformer 中的位置编码方式由于其外推能力不佳,如今已经很少使用,本文不再深入探讨传统的 Transformer 中的编码方法,对于需要了解更多相关知识的读者,可以前往原论文查阅详情 (Vaswani et al., 2017)。在这里,我们将重点介绍目前非常流行的旋转位置编码(RoPE)(Su et al., 2021),值得一提的是,Meta 的 LLaMa 系列模型 (Touvron et al., 2023a) 均采用了此种编码方式。RoPE 从建模美学的角度来说,是一种十分优雅的结构,通过将位置信息融入 query 和 key 的旋转之中,来实现相对位置的表达。图2. 旋转位置编码结构,引自(Su et al., 2021)。
位置插值 (Position Interpolation)尽管 RoPE 相比绝对位置编码的外推性能要优秀不少,但仍然无法达到日新月异的应用需求。为此研究人员相继提出了各种改进措施,以 PI (Chen et al., 2023) 和 NTK-aware Scaled RoPE (bloc97, 2023) 为典型代表。但要想取得理想效果,位置插值仍然离不开微调,实验表明,即使是宣称无需微调便可外推的 NTK-aware Scaled RoPE,在传统 attention 架构下,至多只能达到 4~8 倍的外推长度,且很难保障良好的语言建模性能和长程依赖能力。
图3. 位置插值示意图,引自(Chen et al., 2023)。
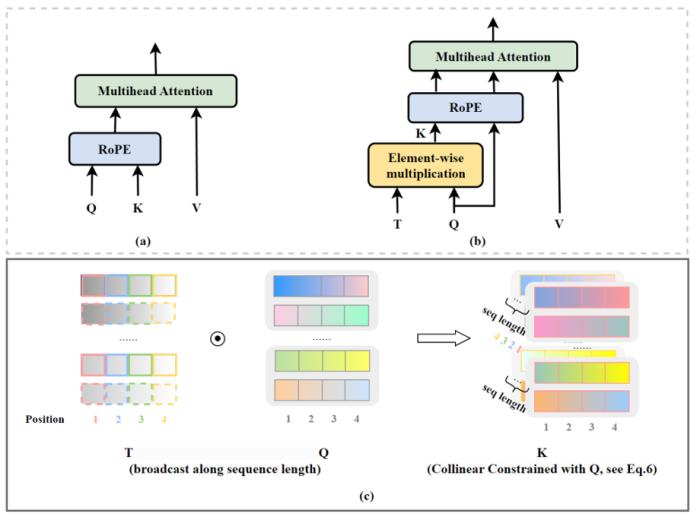
CoCA过去的研究主要集中在位置编码上,所有相关研究工作均默认 self-attention 机制已经被完美实现。然而,蚂蚁人工智能团队近期发现了一个久被忽视的关键:要从根本上解决 Transformer 模型的外推性能问题,self-attention 机制同样需要重新考量。图4. CoCA 模型架构,引自(Zhu et al., 2023)。
RoPE 与 self-attention 的异常行为在 Transformer 模型中,self-attention 的核心思想是计算 query(q)和 key(k)之间的关系。注意力机制使用这些关系来决定模型应该 “关注” 输入序列中的哪些部分。考虑输入和,分别代表输入序列中的m个和第n个位置索引对应的 token,其 query 和 key 分别为和。它们之间的注意力可以表示为一个函数,如果应用 RoPE,则可以进一步简化为仅依赖于m和n相对位置的函数。从数学角度看,可以解释为组复数(,其中d为 hidden dimension 维度,省略位置索引m,n)经过旋转后的内积之和。这在直觉上是有意义的,因为位置距离可以建模为一种序,并且两个复数的内积随着旋转角度 的变化而变化,以图 5 为例,其中,为和的初始夹角。然而,它隐藏着一个此前一直被忽略的技术缺陷。为了便于理解,我们首先考虑双向注意力模型,例如 Bert (Devlin et al., 2019) 和 GLM (Du et al., 2021) 等。如图 5 所示,对于组复数中的任意一组,,它们分别具有位置索引m和n。不失一般性,我们假设复平面上有一个小于的角度逆时针从旋转到,那么它们的位置关系有两种可能的情况(不考虑 =,因为它是平凡的)。正常保序关系:当时,如图 5 右侧所示。注意力分数随着位置距离的增加而降低(直到它们相对角度超出,超出的这部分在原论文附录中进行了讨论 (Zhu et al., 2023))。异常行为:然而,当时,如图 5 左侧所示,异常行为打乱了个最邻近的 token 的序。当时,和之间的相对角度将随着的增大而减小,这意味着最接近的 token 可能会获得较小的注意力分数。(我们在这里使用 “可能”,因为注意力分数是个内积的总和,也许其中一个是微不足道的。但是,后续实验证实了这一重要性。)并且,无论应用 PI 还是 NTK-aware Scaled RoPE,均无法消除这一影响。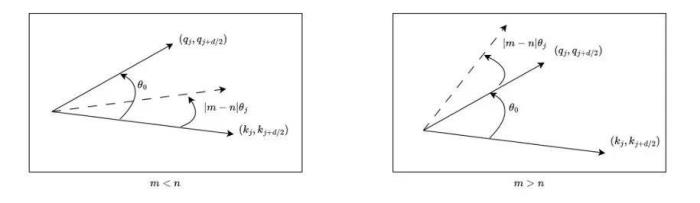
图5.双向模型中的序被破坏,引自(Zhu et al., 2023)。
对于因果模型来说,虽然m总是大于n,但问题同样存在。如图 6 所示,对于某些j,当存在小于的角度从逆时针旋转到时,而不是从到。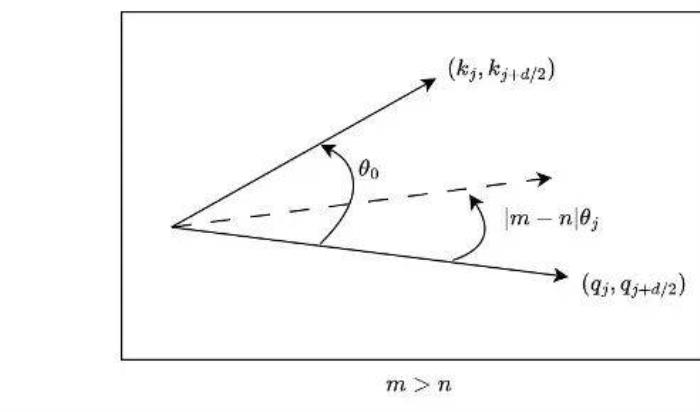
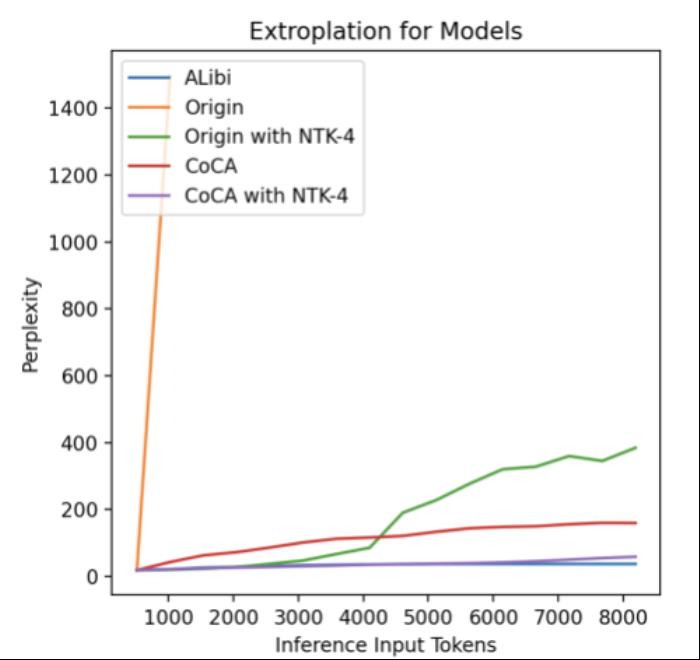
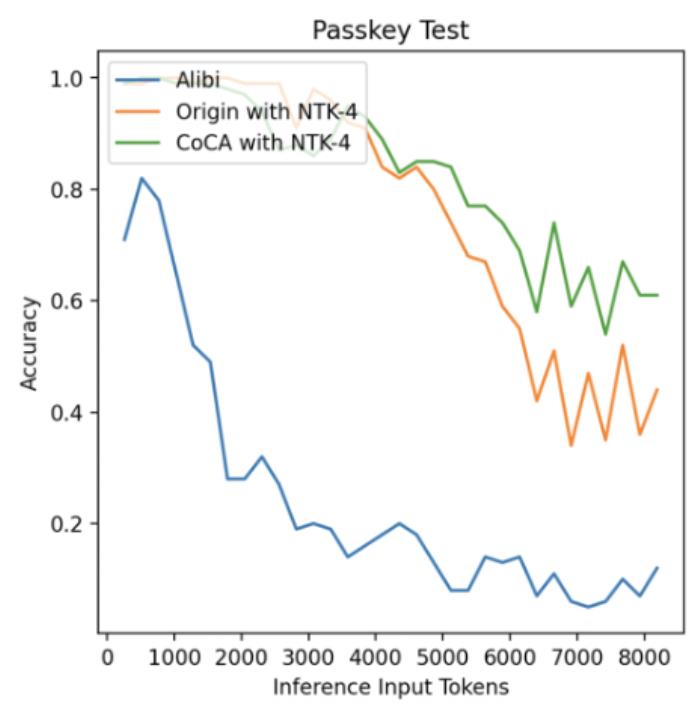
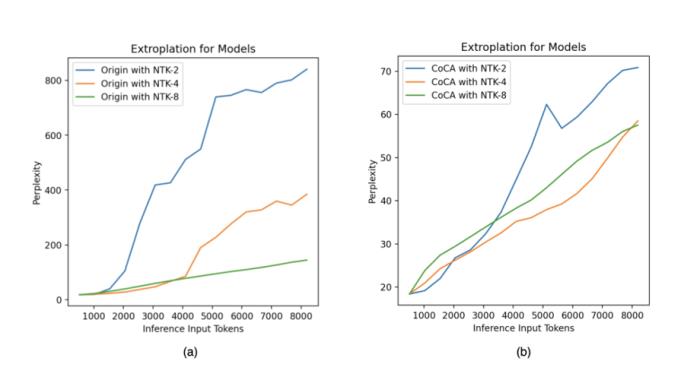
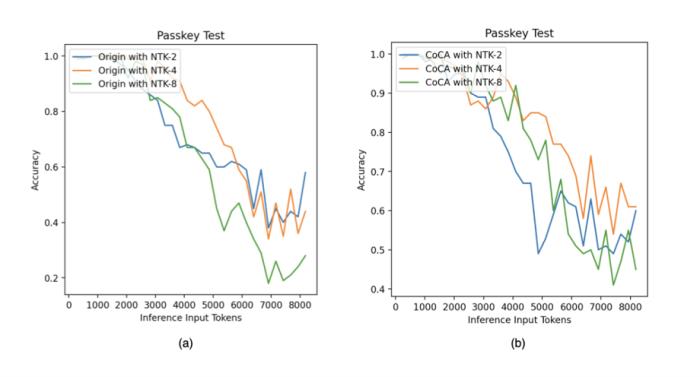
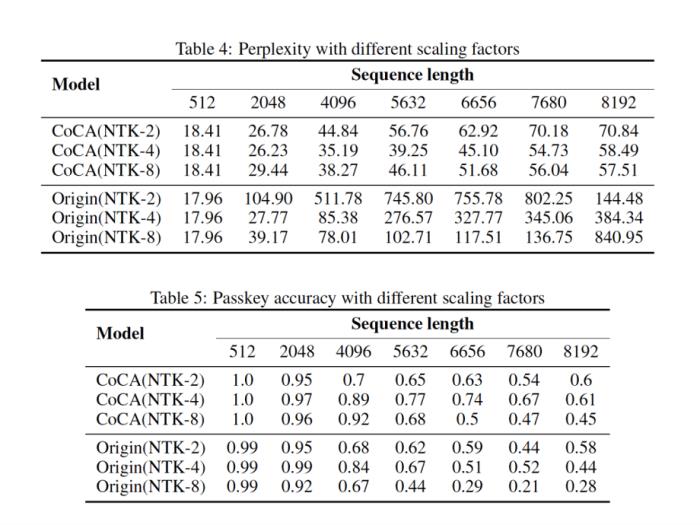
图11. 外推中的注意力得分,引自(Zhu et al., 2023)Human Eval在论文之外,我们使用相同的数据(120B token),相同的模型规模(1.3B),相同训练配置,基于 CoCA 和 Origin 模型进一步评测了 human eval 上的表现,与 Origin 模型对比如下:跟 Origin 模型比起来,两者水平相当,CoCA 并没有因为外推能力而导致模型表达能力产生损失。Origin 模型在 python、java 的表现比其他语言好很多,在 go 上表现较差,CoCA 的表现相对平衡,这与训练语料中 go 的语料较少有关,说明 CoCA 可能有潜在的小样本学习能力。python
java
cpp
js
go
AVG
CoCA
6.71%
6.1%
3.66%
4.27%
6.1%
5.37%
Origin
7.32%
5.49%
5.49%
5.49%
1.83%
5.12%
总结在这项工作中,蚂蚁人工智能团队发现了 RoPE 和注意力矩阵之间的某种异常行为,该异常导致注意力机制与位置编码的相互作用产生紊乱,特别是在包含关键信息的最近位置的 token。为了从根本上解决这个问题,论文引入了一种新的自注意力框架,称为共线约束注意力(CoCA)。论文提供的数学证据展示了该方法的优越特性,例如更强的远程衰减形式,以及实际应用的计算和空间效率。实验结果证实,CoCA 在长文本语言建模和长程依赖捕获方面都具有出色的性能。此外,CoCA 能够与现有的外推、插值技术以及其他为传统 Transformer 模型设计的优化方法无缝集成。这种适应性表明 CoCA 有潜力演变成 Transformer 模型的增强版本。
关于 DevOpsGPTDevOpsGPT 是我们发起的一个针对 DevOps 领域大模型相关的开源项目,主要分为三个模块。本文介绍的 DevOps-Eval 是其中的评测模块,其目标是构建 DevOps 领域 LLM 行业标准评测。此外,还有 DevOps-Model、DevOps-ChatBot 两个模块,分别为 DevOps 领域专属大模型和 DevOps 领域智能助手。我们的目标是在 DevOps 领域,包含开发、测试、运维、监控等场景,真正地结合大模型来提升效率、成本节约。我们期望相关从业者一起贡献自己的才智,来让 “天下没有难做的 coder”,我们也会定期分享对于 LLM4DevOps 领域的经验 & 尝试。欢迎使用 & 讨论 & 共建
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










