

 新火种
2023-11-11
新火种
2023-11-11 


GPU推理提速4倍!FlashDecoding++技术加速大模型推理
要点:
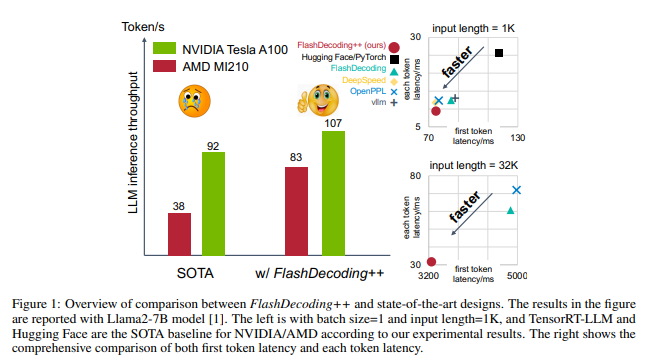
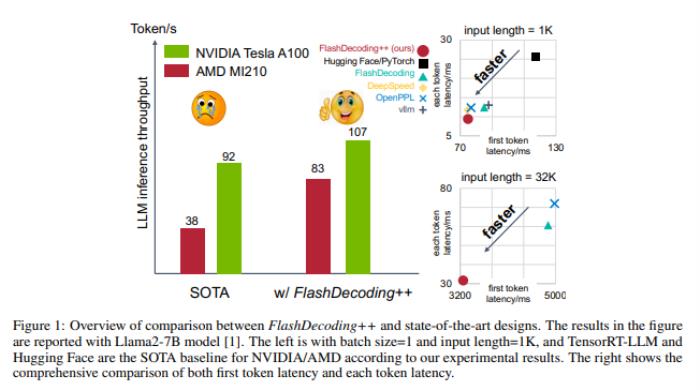
1. FlashDecoding++ 是一种用于加速大模型(LLM)推理任务的新方法,可以将GPU推理提速2-4倍,同时支持NVIDIA和AMD的GPU。
2. FlashDecoding++ 的核心思想包括异步方法实现注意力计算的真正并行以及优化"矮胖"矩阵乘计算,以降低LLM的推理成本并提高推理速度。
3. 无问芯穹是一家创立于2023年5月的公司,旨在打造大模型软硬件一体化解决方案,他们已经将FlashDecoding++集成到其大模型计算引擎"Infini-ACC"中,实现了256K上下文的处理能力。
站长之家(ChinaZ.com)11月6日 消息:推理大模型(LLM)是AI服务提供商面临的巨大经济挑战之一,因为运营这些模型的成本非常高。FlashDecoding++ 是一种新的技术,旨在解决这一问题,它通过提高LLM推理速度和降低成本,为使用大模型赚钱提供了新的可能性。
论文地址:https://arxiv.org/pdf/2311.01282.pdf
FlashDecoding++的核心思想包括异步方法实现注意力计算的真正并行以及优化"矮胖"矩阵乘计算。这些技术可以将GPU推理提速2-4倍,同时支持NVIDIA和AMD的GPU。这意味着LLM的推理任务将更加高效,可以在更短的时间内完成。
无问芯穹是FlashDecoding++的背后力量,他们是一家创立于2023年5月的公司,旨在打造大模型软硬件一体化解决方案。他们已经将FlashDecoding++集成到其大模型计算引擎"Infini-ACC"中,实现了256K上下文的处理能力,这是目前全球最长的文本长度。
FlashDecoding++的出现为使用大模型赚钱提供了更好的机会,因为它可以降低运营成本,提高效率,同时支持多种GPU后端。这对AI服务提供商和大模型创业公司都是一个重要的突破。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










