

 新火种
2023-11-01
新火种
2023-11-01 


加州大学17岁博士生“直言”:解决机器学习“新”问题,需要系统研究“老”方法
 作者 |Kabir Nagrecha编译 | 王晔校对 | 维克多
作者 |Kabir Nagrecha编译 | 王晔校对 | 维克多过去十年中,机器学习(ML)已经让无数应用和服务发生了天翻地覆的变化。随着其在实际应用中的重要性日益增强,这使人们意识到需要从机器学习系统(MLOps)视角考察机器学习遇到的新挑战。
那么这些新挑战是什么呢?
近日,加州大学一位年仅17岁的博士生,在一篇博文中指出:
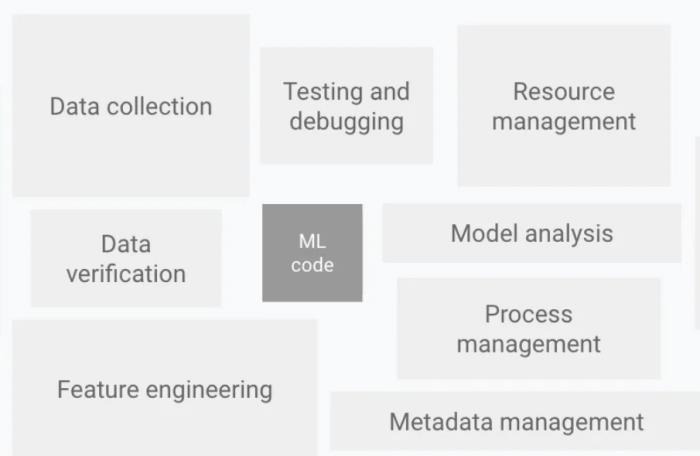
机器学习系统是ML在实践中的新领域,该领域在计算机系统和机器学习之间发挥着桥梁性的作用。所以,应从传统系统的思维中考察数据收集、验证以及模型训练等环节的“新情况”。
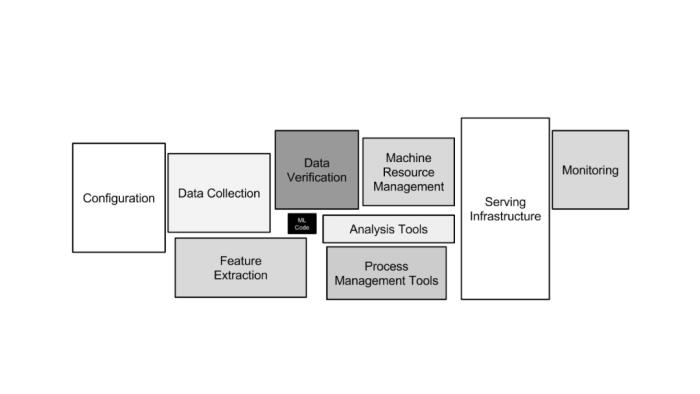
图注:机器学习系统架构
以下是原文,AI科技科技评论做了不改变愿意的编译和删减
1
数据收集
虽然研究人员偏向于使用现成的数据集,例如CIFAR或SQuAD,但从模型训练的角度来看,从业者往往需要手动标记和生成自定义数据集。但是,创建这样的数据集非常昂贵,尤其是在需要领域专业知识的情况下。
因此,数据收集是对系统开发者来说是机器学习中的一项主要挑战。
当前,对这个挑战最成功的解决方案之一借用了系统和机器学习的研究。例如SnorkelAI采用了 "弱监督数据编程 "(weakly-supervised data programming)的方法,将数据管理技术与自我监督学习的工作结合了起来。
具体操作是:SnorkelAI将数据集的创建重新构想为编程问题,用户可以指定弱监督标签的函数,然后将其合并和加权以生成高质量的标签。专家标记的数据(高质量)和自动标记的数据(低质量)可以被合并和跟踪,这样能够考虑到不同水平的标签质量,以确保模型训练被准确加权。
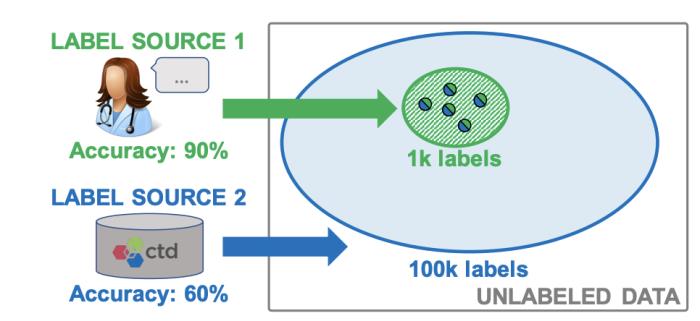
图注:SnorkelAI结合了不同来源的标签,使模型能够大限度聚集和改进混合质量的标签。
这一技术让人联想到数据库管理系统中的数据融合,通过识别系统和ML的共同问题(组合数据来源),我们可以将传统的系统技术应用于机器学习。
2
Data Verification数据验证
数据验证是数据收集的后续工作。数据质量是机器学习的关键问题,用一句俗话来说,就是 "垃圾进,垃圾出(garbage in, garbage out)"。因此,要想系统产生高质量的模型,必须确保输入的数据也是高质量的。
解决这个问题,所需要的不仅是调整机器学习方法,更需要有调整系统的思维。幸运的是,虽然对ML来说数据验证是一个新问题,但数据验证在业界早已有讨论:
引用TensorFlow数据验证(TFDV)的论文:
基于游戏开“Data validation is neither a new problem nor unique to ML, and so we borrow solutions from related fields (e.g., database systems). However, we argue that the problem acquires unique challenges in the context of ML and hence we need to rethink existing solutions”"数据验证既不是一个新问题,也不是ML独有的问题,因此可以我们借鉴相关领域(如数据库系统)的解决方案。然而,我们认为,在ML的背景下,这个问题具有特殊的挑战,因此我们需要重新思考现有的解决方案"TFDV的解决方案采用来自数据管理系统的 "战斗考验 (battle-tested)"解决方案——模式化。数据库强制执行属性,以确保数据输入和更新符合特定的格式。同样,TFDV的数据模式也对输入到模型中的数据执行规则。
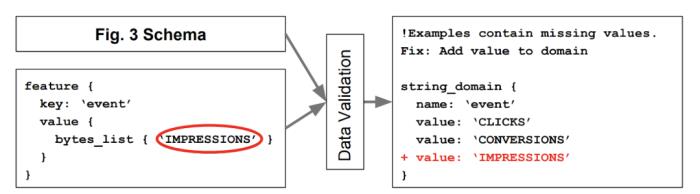
图注:TensorFlow数据验证的基于模式的ML数据验证系统使用户能够防止生产系统中的数据输入出现异常。
当然,也有一些差异,反映了机器学习系统与传统模式的不同。考虑到数据分布的变化,ML模式需要随着时间的推移而演变和调整,还需要考虑在系统的生命周期内可能对模型本身做出的改变。
很明显,机器学习带来了一种新型的系统挑战。但是,这些系统带来了很多旧东西的同时也带来了新的东西。在我们寻求重塑车轮之前,我们应该利用已有的东西。
3
模型训练
ML从业者可能会惊讶于将模型训练作为系统优化的一个领域。毕竟,如果说机器学习应用中有一个领域真正依赖于ML技术,那就是训练。但即便是这样,系统研究也要发挥作用。
以模型并行化为例。随着Transformers的兴起,ML模型的规模都有了极大的增加。几年前,BERT-Large仅仅只超过了345M的参数,而现在Megatron-LM拥有超过万亿的参数。
这些模型的绝对内存成本可以达到数百GB,且单一的GPU已经承受不住。传统的解决方案,即模型并行化,采取了一个相对简单的方法:为了分配内存成本,将模型划分到不同的设备。
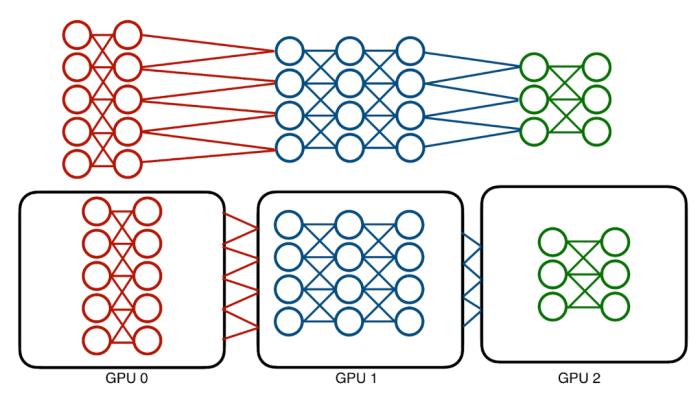
传统的模型并行化会受到神经网络架构顺序的影响。高效并行计算的机会是有限的。
但这种技术是有问题的:模型本质是顺序的,训练它需要在各层中前后传递数据。一次只能使用一个层,也只能使用一个设备。这意味着会导致设备利用率不足。
系统研究如何提供帮助?
考虑一个深度神经网络。将其分解为最基本的组件,可以将它看作一系列转换数据的运算器。训练仅指我们通过运算器传递数据,产生梯度,并通过运算器反馈梯度,然后不断更新的过程。
在这一级别上,该模型开始进行类似于其他阶段的操作——例如,CPU的指令流水线(instruction pipeline)。有两个系统,GPipe和Hydra,试图利用这种并行的方式来应用系统优化的可扩展性和并行性。
GPipe采用CPU指令并行的方式,将模型训练变成一个流水线问题。模型的每个分区都被认为是流水线的不同阶段,分阶段进行小型批次通过分区,以最大限度地提高利用率。
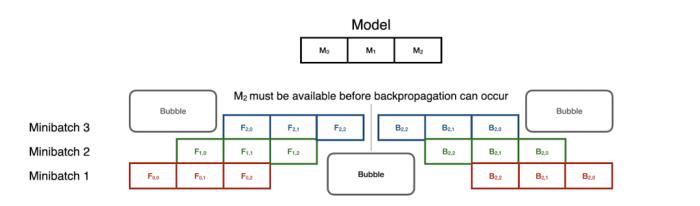
流水线并行是顺序模型并行中最先进的技术,它使训练在小型批次中并行。但同步开销可能很昂贵,特别是在前向和后向的转换中。
然而,请注意,在反向传播中,阶段是以相反的顺序重复使用的。这意味着,在前向流水线完全畅通之前,反向传播不能开始。尽管如此,这种技术可以在很大程度上加快模型的并行训练:8个GPU可以加速5倍!
Hydra采取了另一种方法,将可扩展性和并行性分离成两个不同的步骤。数据库管理系统中的一个常见概念是 "溢出",即将多余的数据发送到内存层次的较低的级别。Hydra利用了模型并行中的顺序计算,并提出不活跃的模型分区不需要在GPU上。相反,它将不需要的数据交给DRAM,将模型分区在GPU上交换,从而模拟传统模型并执行。
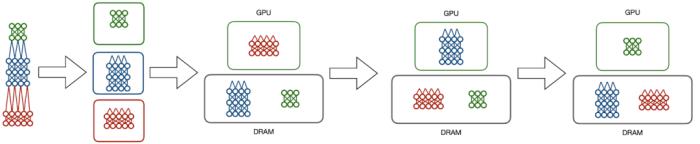
Hydra的模型溢出技术(Hydra’s model spilling technique )将深度学习训练的成本分给DRAM而不是GPU内存,同时保持了GPU执行的加速优势。
这使我们可以一次只使用一个GPU进行训练模型。那么,在此基础上引入一定程度的任务并行性是微不足道的。每个模型,无论其大小,一次只需要一个GPU,所以系统可以同时充分利用每个GPU。其结果是在8个GPU的情况下,速度提高了7.4倍以上,接近最佳状态。
但模型并行化只是系统研究帮助模型训练的开始。其他有前景的贡献包括数据并行(如PyTorch DDP)、模型选择(如Cerebro或模型选择管理系统)、分布式框架(Spark或Ray)等等。因此,模型训练是一个可以通过系统研究进行优化的领域。
4
Model Serving模型服务
说到底,构建机器学习模型是为了使用。模型服务和预测是机器学习实践中最关键的方面之一,也是系统研究影响最大的空间之一。
预测分为两个主要设定:离线部署和在线部署。离线部署相对简单,它涉及不定期运行单一且大批量预测工作。常见的设定包括商业智能、保险评估和医疗保健分析。在线部署属于网络应用,在这种应用中,需要快速、低延迟的预测,以满足用户查询的快速响应。
这两种设定都有各自的需求和要求。一般来说,离线部署需要高吞吐量的训练程序来快速处理大量样本。另一方面,在线部署一般需要在单个预测上有极快的周转时间,而不是同时有许多预测。
系统研究改变了我们处理这两项任务的方式。以Krypton为例,它把视频分析重新想象为 "多查询优化"(MQO)任务的工具。
MQO并不是一个新领域——几十年来它一直是关系型数据库设计的一部分。总体思路很简单:不同的查询可以共享相关的组件,然后这些组件可以被保存和重复使用。Krypton指出,CNN的推论通常是在成批量的相关图像上进行的,例如视频分析。
通常情况下,视频的特征是高帧率,这意味着连续帧往往是比较相似的。帧1中的大部分信息在帧2中仍然存在。这里与MQO有一个明显的平行关系:我们有一系列任务,它们之间有共享的信息。
Krypton在第1帧上运行一个常规推理,然后将CNN在预测时产生的中间数据具体化,或保存起来。随后的图像与第1帧进行比较,以确定图像的哪些地方发生了大的变化,哪些需要重新计算。一旦确定了补丁程序,Krypton就会通过CNN计算补丁的 "变化域",从而确定在模型的整个状态下,哪些神经元输出发生了变化。这些神经元会随着变化后的数据重新运行。其余的数据则只从基本帧中重复使用!
结果是:端到端训练提速超过4倍,数据滞后造成的精度损失很小。这种运行时间的改进对于需要长期运行的流媒体应用至关重要。
Krypton在关注模型推理方面并不是唯一的。其他作品,如Clipper和TensorFlow Extended,通过利用系统优化和模型管理技术,提供高效和健全的预测,解决了同样的高效预测服务问题。
5
结论
机器学习已经彻底改变了我们使用数据和与数据互动的方式。它提高了企业的效率,从根本上改变了某些行业的前景。但是,为了使机器学习继续扩大其影响范围,某些流程必须得到改善。系统研究通过将数据库系统、分布式计算和应用部署领域的数十年工作引入机器学习领域,能够提高机器学习的表现。
虽然机器学习非常新颖和令人兴奋,但它的许多问题却不是。通过识别相似之处和改善旧的解决方案,我们可以使用系统来重新设计ML。
作者简介
Kabir Nagrecha是加州大学圣地亚哥分校的博士生,由Arun Kumar指导。
13岁时,通过提前入学计划进入大学。从那时起,就一直在工业界和学术界从事机器学习领域的研究。
曾获得加州大学圣地亚哥分校卓越研究奖、CRA杰出本科生研究员等荣誉。目前正在苹果的Siri小组实习。他的研究侧重于通过使用系统技术实现深度学习的可扩展性。
原文链接:https://thegradient.pub/systems-for-machine-learning/
雷锋网雷锋网雷锋网

相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










