

 新火种
2023-09-19
新火种
2023-09-19 


国内7家大模型测评:生成内容标识较完备,信息披露仍不足
9月13日,阿里云宣布通义千问大模型已首批通过备案,并正式向公众开放。8月31日,11家大模型正式通过备案。目前已有包括百度文心一言、智谱AI智谱清言、科大讯飞星火大模型、商汤商量、百川大模型(53B)、MINIMAX、360智脑以及抖音豆包等多款大模型,开放用户服务。
为了评估这些产品的信息披露透明度,日前象信AI对上述除360智脑、通义千问的七家国内厂商公开披露的信息进行了详细分析,并与国外厂商OpenAI进行了比较。该评估覆盖了5个主要维度和12个具体测评项。这些维度和测评项包括:用户权益保护,数据处理,模型运作,部署方式以及算力。
根据测评结果,相比起OpenAI,国内大模型对安全、算力、能耗、数据的信息披露比较差,这表明大模型厂商还有待改进。
具体而言,此次信息披露透明度的测评方法内容主要来自各个大模型的用户协议,测评依据参考了《生成式人工智能服务管理暂行办法》,《中华人民共和国个人信息保护法》,欧盟《人工智能法案》草案,Stanford CRFM,《互联网信息服务深度合成管理规定》。
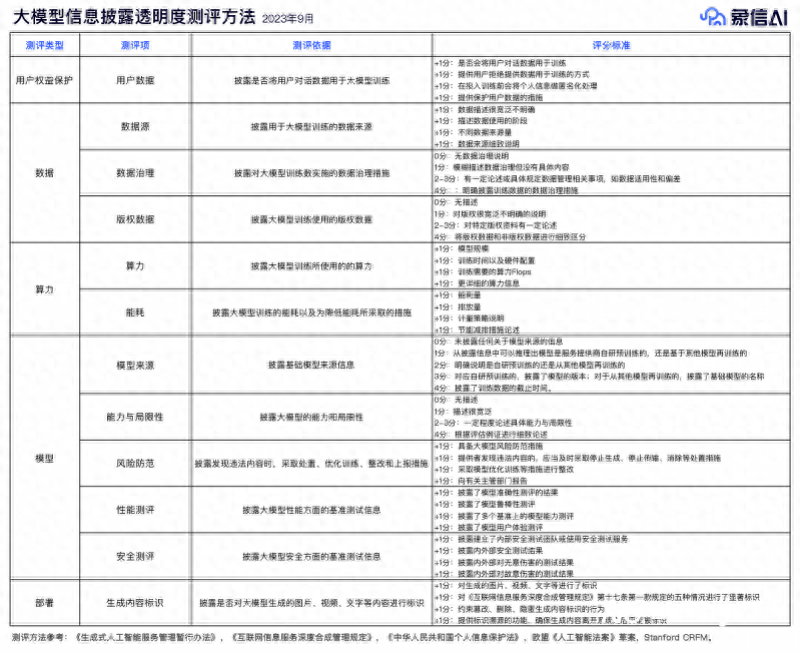
在测评中,重点考察了大模型是否披露将用户对话数据用于大模型训练;数据来源;发现违法内容时的处理措施和整改过程;是否对大模型生成的内容进行标识等问题。
象信AI横向对比了国内外多家大模型厂商。根据测评结果,在总体得分中,GPT-4的得分最高,总分48分取得了28分。文心一言、智博清言的得分次之,分别取得了15分。
此外,在具体的测评项目上,国内外大模型在用户数据、生成内容标识两方面均做得较好。国产大模型在生成内容标识方面的披露优于GPT-4。然而,国内大模型厂商在训练数据治理方面的披露严重落后于GPT-4,在信息披露方面还存在较多提升的空间——尤其在数据治理、模型来源、能力与局限性、风险防范、性能测评、安全测评等测评项中。这些测评项目里存在对用户隐私、数据质量、性能可信度以及安全等多方面的担心。因此,提供更全面、清晰和透明的信息披露将有助于用户更好地了解和信任大模型。
在本次评估过程中,观察到所有国内大型模型厂商均会利用用户对话数据进行模型训练。然而,这些厂商未提供任何机制,以允许用户拒绝其数据被用于训练目的。例如,某国内大模型厂商的用户协议中的披露:
你理解并同意,对于你通过本软件及相关服务输入、生成、发布、传播的信息内容之全部或部分(合称信息内容),你授予公司和/或关联方一项免费的、全球范围内的、永久的许可,允许公司和/或关联方可以使用你提供的信息内容来优化模型和服务。上述许可是可以转让的,也是可以进行分许可或再许可的。
但在OpenAI的隐私政策中,不但明确指出会使用用户对话数据用于训练模型,还提供用户拒绝其数据被用于训练目的的方式。
如上所述,我们可能会使用您提供给我们的内容来改进我们的服务,例如训练ChatGPT的模型。有关如何选择不使用您的内容来训练我们的模型的说明,请参阅此处。

最后,本次测评全部大模型厂商在版权数据、能耗方面总分是0。不提供版权数据的信息可能导致不合规的情况,特别是涉及知识产权的合规性。在数据中心的能耗持续攀升的背景下,认知和改善大模型的能源消耗变得至关重要,而缺乏能源消耗数据的信息披露,这可能导致模型的可持续性和环境影响问题。
采写:南都记者 胡耕硕
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









