新火种
2023-09-19
新火种
2023-09-19 


大模型不受控地变聪明?千组实验证明:“智能涌现”并不频发
ChatGPT的大火,国产大模型的激烈竞争,都使得“智能涌现”这个概念逐渐走进了大众眼中。
所谓“智能涌现”,是指大型语言模型在没有经过针对性训练的任务,包括那些需要复杂推理能力的任务中,同样表现出了卓越的性能。有科学家将这种“涌现”能力定义为“系统的量变导致行为的质变”。
也因此,智能涌现通常被认为不存在于小模型中,而只会在较大型的语言模型中出现。这就使得“智能涌现”的出现具有突发性、不可预测性,不可控性,进而使不少学者对大型语言模型的安全性提出了质疑——毕竟,AI不受控制地变得更加聪明,看上去似乎的确存在潜在的危险性。
对此,德国达姆施塔特工业大学和英格兰巴斯大学的研究者们在9月4日发表一篇论文通过上千组实验证明,大语言模型中所谓“智能涌现”并不频繁出现,也没有展现出复杂的“推理”能力。

论文在开头就表示,现在很多对大语言模型“涌现”出的能力的界定,往往会被模型中通过其他提示技术所混淆,比如利用上下文信息来提高预测和分类的准确性和有效性的上下文学习(in context learning)算法。因此作者提出问题:
到底模型是真正“涌现”出了能力,还是说通过细微的调参或其他指令调整,使其能够更有效、更高效地进行上下文学习?
为了全面考察这些“涌现”出的能力,研究者对包括GPT-2、GPT-3、LLaMA在内的18个模型进行了测试,参数范围从6000万到1750亿个参数。
用以测试的任务共有22项,其中有14项是此前在大语言模型GPT-3中出现,并被认为是“涌现”的能力,有7项是在统一数据集中随机选择作为对照组的任务(大语言模型有能力解决,但并非“涌现”出的“智能”),还有由小学数学问题组成的数据集GSM8K。
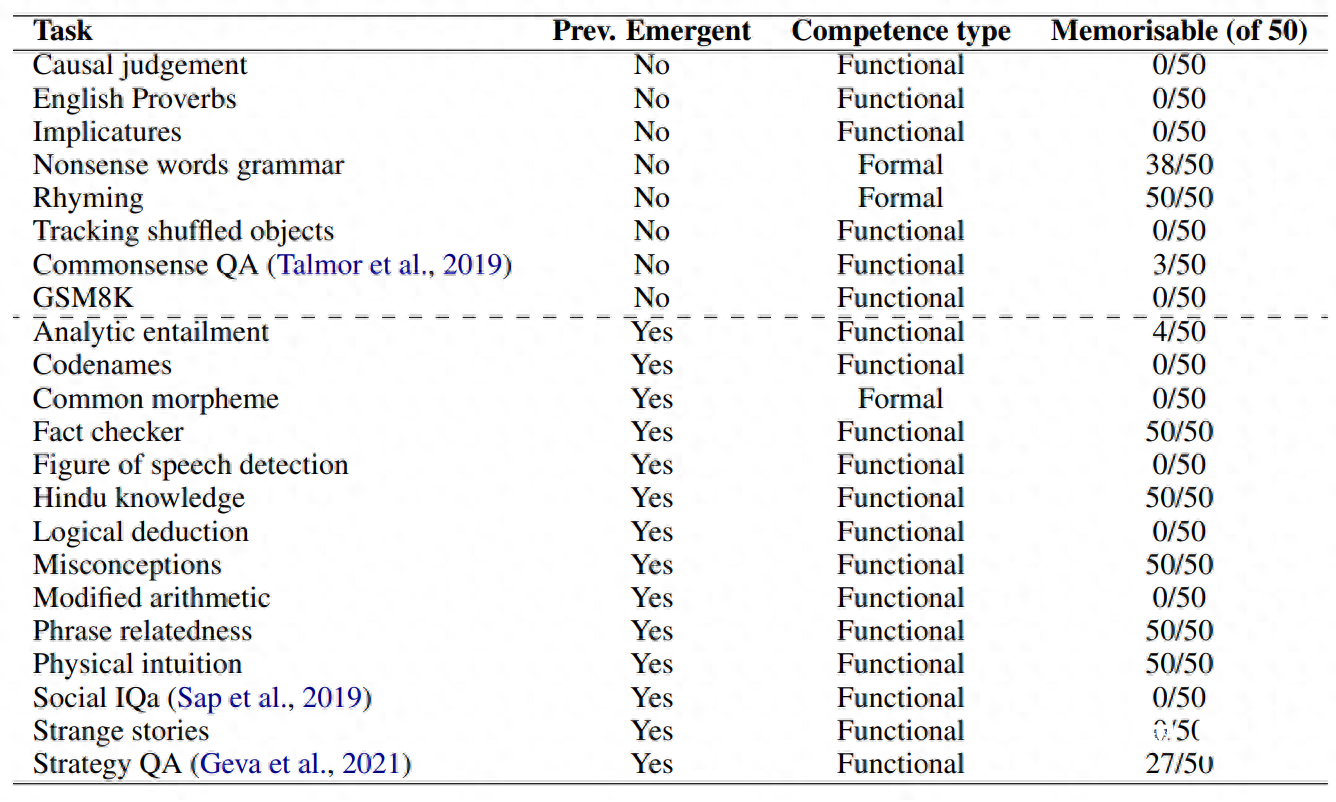
基于上述大语言模型和任务,研究人员在上下文学习、指令调整、少样本学习、零样本学习等多个条件下进行了超过1000次的实验,并发现,在上述选出的14项被认为是“涌现”出的任务中,大多数的模型都只在其中两项任务中显示出了“涌现性”。
这两项任务中,其中一个代表了正式的语言能力,另一个则代表了记忆能力。此外,也没有发现被视为“智能涌现”的典型特性——推理能力出现的证据。
在论文最后,研究者提出,现在很多大语言模型“涌现”出的能力主要来自于上下文学习。因此,对于“智能涌现”所导致的大语言模型安全性的问题,可以不用太过担忧。
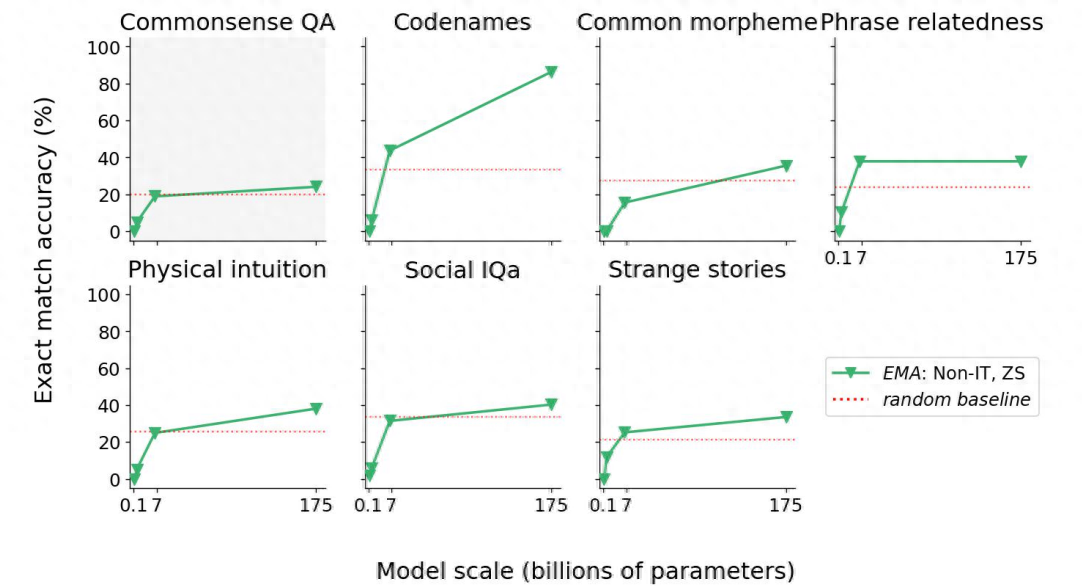
随着模型变大,其在填字推理游戏、相关性短语相关性、奇怪故事上的表现是可预测的,因此并非“智能涌现”。
采写:南都记者 杨博雯
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章