新火种
2023-10-30
新火种
2023-10-30 


AAAI2022大奖出炉!中科院德州扑克程序AlphaHoldem获卓越论文奖

作者 | 西西、王晔
编辑丨陈彩娴
近日,人工智能国际顶会 AAAI 2022 正在召开,大会论文奖也陆续公布。AI科技评论获知,中国科学院自动化所的兴军亮教授团队获得 AAAI 2022 的卓越论文奖(Distinguished Paper)!
AAAI 的英文全称是“Association for the Advance of Artificial Intelligence”(美国人工智能协会)。该协会是人工智能领域的主要学术组织之一,具有一定的学术权威性。
兴军亮团队此次获奖的工作是他们所开发的轻量型德州扑克 AI 程序——AlphaHoldem。据介绍,该系统的决策速度较 DeepStack 的速度提升超1000倍,与高水平德州扑克选手对抗的结果表明其已经达到了人类专业玩家水平。
论文名称:《AlphaHoldem: High-Performance Artificial Intelligence for Heads-Up No-Limit Poker via End-to-End Reinforcement Learning》
作者团队:赵恩民,闫仁业,李金秋,李凯,兴军亮
德州扑克AI的意义
与围棋任务相比,德州扑克是一项更能考验基于信息不完备导致对手不确定的智能博弈技术。
德州扑克是国际上最为流行的扑克游戏,由于最早起源于20世纪初美国德克萨斯州而得名。
德州扑克的规则是使用去掉王牌的一副扑克牌,共52张牌,至少2人参与,至多22人,一般参与人数为两人和十人之间。
游戏开始时,首先为每个玩家发两张私有牌作为各自的“底牌”,随后将五张公共牌依次按三张、一张、一张朝上发出。在发完两张私有牌、三张共有牌、第四张公共牌、第五张公共牌后玩家都可以多次无限制押注,这四轮押注分别称为“翻牌前”、“翻牌”、“转牌”、“河牌”。图1展示了一场德州扑克游戏的完整流程示意。
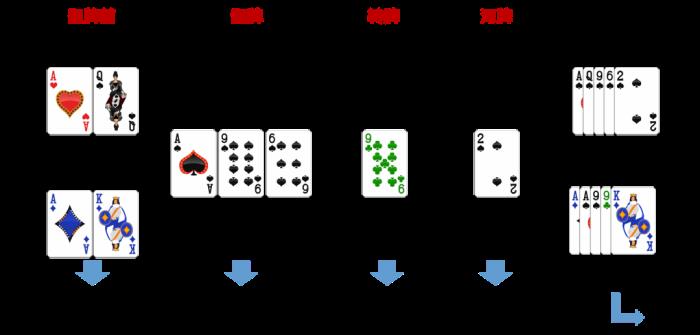
图1:两人无限注德州扑克一次游戏过程示意
经过四轮押注之后,若仍不能分出胜负,游戏进入“摊牌”阶段,所有玩家亮出各自底牌并与公共牌组合成五张牌,成牌最大者获胜。图2给出了德州扑克不同组合的牌型解释和大小。

图2:德州扑克不同牌型大小说明和比较
德州扑克博弈的问题复杂度很大,两人无限注德州扑克的决策空间复杂度超过10的161次方;其次,德州扑克博弈过程属于典型的回合制动态博弈过程,游戏参与者每一步决策都依赖于上一步的决策结果,同时对后面的决策步骤产生影响;另外,德州扑克博弈属于典型的不完美信息博弈,博弈过程中玩家各自底牌信息不公开使得每个玩家信息都不完备,玩家在每一步决策时都要充分考虑对手的各种可能情况,这就涉及到对手行为与心理建模、欺诈与反欺诈等诸多问题。
研究者认为,由于德州扑克游戏规则又非常简单且边界确定,特别适合作为一个虚拟实验环境对博弈的相关基础理论方法和核心技术算法进行深入探究。
近年来,国际研究者在德州扑克这一大规模不完美信息博弈问题的优化求解中也取得了长足进步。
比如,之前加拿大阿尔伯特大学和美国卡内基梅隆大学的研究者就设计出 AI 程序 DeepStack 和 Libratus,并先后在两人无限注德州扑克中均战胜了人类专业选手,随后卡内基梅隆大学设计的 Pluribus 又在六人无限注德州扑克中战胜了人类专业选手。
但目前主流德州扑克AI背后的核心思想是利用反事实遗憾最小化(Counterfactual Regret Minimization, CFR)算法逼近纳什均衡策略。
具体来说,首先利用抽象(Abstraction)技术[3][7]压缩德扑的状态和动作空间,从而减小博弈树的规模,然后在缩减过的博弈树上进行CFR算法迭代。
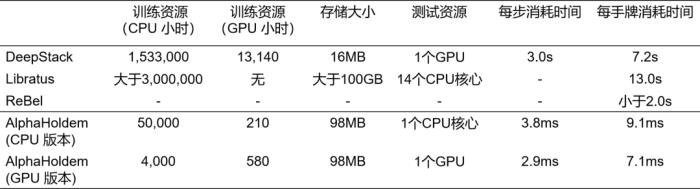
这些方法严重依赖于人类专家知识进行博弈树抽象,并且CFR算法需要对博弈树的状态结点进行不断地采样遍历和迭代优化,即使经过模型缩减后仍需要耗费大量的计算和存储资源。例如,DeepStack使用了153万的CPU时以及1.3万的GPU时训练最终AI,在对局阶段需要一个GPU进行1000次CFR的迭代过程,平均每个动作的计算需耗时3秒。Libratus消耗了大于300万的CPU时生成初始策略,每次决策需要搜索4秒以上。
这样大量的计算和存储资源的消耗严重阻碍了德扑AI的进一步研究和发展;同时,CFR框架很难直接拓展到多人德扑环境中,增加玩家数量将导致博弈树规模呈指数增长。另外,博弈树抽象不仅需要大量的领域知识而且会不可避免地丢失一些对决策起到至关作用的信息。
AlphaHoldem是何方神圣?
这个问题也吸引了很多中国研究者,中科院自动化所的兴军亮教授团队便是其中之一。去年12月,他领导的博弈学习研究组针对德州扑克任务,提出了一种高水平、轻量化的两人无限注德州扑克AI程序——AlphaHoldem。
不同于已有的基于CFR算法的德州扑克AI,中科院博弈学习研究组所提出的架构是基于端到端的深度强化学习算法(如图4所示)。
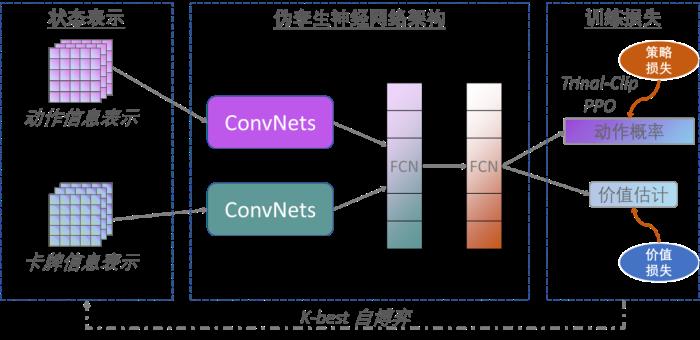
图4:端到端学习德州扑克AI学习框架
根据团队介绍,AlphaHoldem采用Actor-Critic学习框架,其输入是卡牌和动作的编码,然后通过伪孪生网络(结构相同参数不共享)提取特征,并将一种改进的深度强化学习算法与一种新型的自博弈学习算法相结合,在不借助任何领域知识的情况下,直接从牌面信息端到端地学习候选动作进行决策。
他们还指出,AlphaHoldem的成功得益于其采用了一种高效的状态编码来完整地描述当前及历史状态信息、一种基于Trinal-Clip PPO损失的深度强化学习算法来大幅提高训练过程的稳定性和收敛速度、以及一种新型的Best-K自博弈方式来有效地缓解德扑博弈中存在的策略克制问题。
AlphaHoldem 使用了1台包含8块GPU卡的服务器,经过三天的自博弈学习后,战胜了Slumbot和DeepStack。每次决策时,AlphaHoldem都仅用了不到3毫秒,比DeepStack速度提升超过了1000倍。同时,AlphaHoldem与四位高水平德州扑克选手对抗1万局的结果表明其已经达到了人类专业玩家水平。
团队部分成员介绍


兴军亮,中国科学院自动化研究所研究员、博士生导师、特聘青年骨干,中国科学院大学岗位教授,中国科学院人工智能创新研究院创新专家组专家。兴教授2012年毕业于清华大学计算机科学与技术系,获工学博士学位。
此外,他还是美国电器与电子工程学会(IEEE)高级会员、美国《科学》杂志中国官方公众号特邀评论员、中国计算机学会(CCF)高级会员、计算机视觉专委会委员。
他的主要研究领域为计算机视觉和计算机博弈。目前已在包括顶级国际期刊如TPAMI、IJCV、AI以及顶级国际会议上如ICCV、CVPR、AAAI、IJCAI上发表论文100多篇,谷歌学术引用超过10000次,出版计算机视觉译著2部,参与撰写深度学习领域著作1部、人工智能领域著作1部。
曾获清华大学计算机系“学术新秀”、“谷歌学者”、多次顶级国际和国内会议最佳论文奖等荣誉和奖励,以及十余次在人脸识别、车辆识别、视频识别等国际和国内挑战赛中获奖。
目前作为项目和课题负责人承担多项国家重点项目,研发的视觉感知相关技术在国家广电总局、华为、微软等得到了多次验证应用和落地推广,取得了良好的经济效益和社会价值。
近年来主要围绕深度强化学习相关的智能感知和决策问题,研发了多款针对不同游戏的博弈决策AI,其中研发的星际争霸AI曾获2017年IEEE CIG星际争霸AI第2名,研发的德州扑克AI程序AlphaHoldem胜率超过了目前公开的最好德州扑克AI程序DeepStack,速度提升超过1000倍。开放了学界首个大规模不完美信息博弈平台OpenHoldem。
AAAI 2022其他获奖工作
杰出论文奖:
论文名称:Online Certification of Preference-Based Fairness for Personalized Recommender Systems
作者团队:Virginie Do,Sam Corbett-Davies,Jamal Atif, Nicolas Usunier
杰出学生论文奖:
论文名称:InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
作者团队:Pierre Colombo,Chloé Clavel,Pablo Piantanida
卓越论文奖:
除了中科院兴军亮团队的 AlphaHoldem,还有 5 篇工作获得 AAAI 2022 “卓越论文奖”。分别如下
论文名称:Certified Symmetry and Dominance Breaking for Combinatorial Optimisation
作者团队:Bart Bogaerts,Stephan Gocht,Ciaran McCreesh,Jakob Nordström
论文名称:Online Elicitation of Necessarily Optimal Matchings
作者团队:Jannik Peters
论文名称:Sampling-Based Robust Control of Autonomous Systems with Non-Gaussian Noise
作者团队:Thom S. Badings, Alessandro Abate,Nils Jansen,David Parker,Hasan A. Poonawala,Marielle Stoelinga
论文名称:Subset Approximation of Pareto Regions with Bi-objective A
作者团队:Jorge A. Baier,Carlos Hernández,Nicolás Rivera
论文名称:The SoftCumulative Constrain with Quadratic Penalty
作者团队:Yanick Ouellet,Claude-Guy Quimper
参考链接:
1.https://twitter.com/rao2z/status/1496866889921822721
2.https://mp.weixin.qq.com/s/OBRybZ-NwcNW-S9TCObaLA


相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章