新火种
2023-10-29
新火种
2023-10-29 


在大模型数量全国领先的北京,昇腾AI“点燃”首个普惠算力底座
大模型在抹平 AI 模型底层架构多样性的同时,也在悄然抹去城区之间的差异。
站在北京石龙经济开发区 20 号院,很难将这里与京西地区百年钢铁史、千年采煤史联系起来。曾是一代又一代人集体记忆的铁花飞溅、机械轰鸣,如今已化作蔚然成风的「京西智谷」。
2 月,大模型「炼丹炉」—北京市门头沟区与中关村发展集团、华为技术有限公司共建的北京昇腾人工智能计算中心(以下简称计算中心)在 20 号院内正式点亮。6 月,首批上线运营人工智能训练算力规模 100P。
在今年企业争抢算力大背景下,在坐拥全国近三分之一人工智能企业、打响大模型创业「第一枪」的北京,它是第一个面向中小企业提供普惠算力的人工智能训练算力平台。
7 月,计算中心又成为北京第一个拿到「国智牌照」的「新一代人工智能公共算力开发创新平台」,跻身国家人工智能算力发展战略体系。
夯实的基座:算力「大」且「稳」
走进一楼计算中心机房,原以为巨大房间里会屹立几座哄哄作响的「铁皮疙瘩」,结果出乎意料:一间仅 50 平米「小户型」,里面只有一台 Atlas 900 AI 集群( Atlas 900 PoD )。
一个集群共有 8 台机柜,中间五台是核心计算设备,每个机柜里塞进了八个计算节点,是 100P 真正来源。最左边两个柜子其实是液冷分配器,决定液冷水输往哪个管道。最右边两个机柜负责高性能卡之间快速通信。

100P 是什么概念?1P 相当于每秒可进行一千万亿次运算,100P 大约相当于五万台高性能电脑的算力。就计算精度而言,100P 是指半精度( FP16 )算力。
大模型时代有一个明显趋势,企业都是基于一些开源模型做微调,包括二次训练。 「他们会跟我们要两个节点。几十亿参数规模的模型,一到两天就能训练完毕。」北京昇腾人工智能生态创新中心 CTO 杨光介绍说,计算中心目前有四十个节点,按照一家企业需要两个节点来算,可以同时服务二十多家。
绕到机柜身后,触摸背后的液冷门,感觉冰凉,大概只有十几个度。打开厚重的液冷门,依然可以感到热风袭来。只见每台服务器背后都有不少细长管子,直接通到服务器里:
从底部上来的液冷水经由这些管道与服务器进行热交换,带走热量,使温度下降,升温的液冷水回到冷却塔后,恢复以往温度。
整个过程都被封闭在液冷门里,关上门后,外面只剩嗖嗖的凉意。

得益于液冷技术,一台机柜可以塞进八个计算节点,传统运营商的一个机柜通常只能放一台,计算中心 PUE 也做到了 1.15(多数地方要求是 1.2 以下)。
目前使用到中心算力的企业大概有 36 家,算力使用率的峰值可以到 80%。长远来看,100P 只能算「起步价」,「企业业务对应到算力需求都很大。」北京格灵深瞳信息技术股份有限公司副总经理周瑞告诉我们,「像我们这样的企业,未来都是几倍的算力需求。」
今年,计算中心算力规模将达到 400P,并持续扩容至 1000P。100P 算力集群内置 320 张卡,以此类推,400P 算力集群将有 1200 多张卡,1000P 集群卡数将猛增到 3200 张。卡的数量激增,工程复杂度也会呈指数级增长,这对算力集群高可用性提出巨大挑战。
比如,模型训练一个多月,已经完成 99%,突然有张卡出现故障,一切只能从头再来。高性能卡之间的通信问题、训练时无法快速调度到足够算力资源也常常导致训练断掉,之前的努力付诸东流。
为此,计算中心的集群系统提供断点续训能力:平台会保存临界点的 check point (权重文件),故障恢复之后,自动拉取一个非故障节点,将之前保存的权重文件加载进去,继续训练。

「我们最长的稳定时间能做到 25 天」杨光给了一个具体数字。作为对比,Meta 发布 OPT- 175B 模型时曾提到它的稳定训练时间只有 2.8 天。
针对比较知名的开源大模型,计算中心的硬件水平可与英伟达 A100 PK,千卡 NPU 利用率基本能做到 40%。
「易用」与「普惠」:最难的是让企业用起来
除了算力资源充沛、数据安全,价格和易用性也是任何一家想要落地行业大模型企业选择算力底座时考虑的核心因素。
本质上,大模型是对小模型时代作坊式底层算力运作的重新洗牌。过去有一个工作站、几张显卡就能做模型训练,现在完全行不通。
「等了一秒钟,底层的模型才蹦出四、五个字,然后又是几秒的等待,体验很差。」在拜访未接入计算中心算力的企业后,中心工作人员介绍到: 「如果接入计算中心的算力,大约每秒可以输出 20 个 Token 。」
从 Transformer 时代开始,主要面向智慧交通领域的中科视语就在做一些大模型的基础建设。对于这样一家智慧交通领域的成长型 AI 企业来说,自建机房训练大模型的前期资本投入过于巨大,周期也不可控。
去年,手握大几百张卡的格灵深瞳也开始与计算中心合作大模型的研发,「因为需要更加专业、系统的算力基础。」周瑞说。
为了做中国医疗领域最好的科学大模型,医渡科技已经买走了计算中心大部分算力。
其实,像中科视语、格灵深瞳、医渡科技这样人工智能企业都有自己的优势。他们往往拥有一支精细的 AI 团队、积累多年的行业数据和自己的知识图谱,知道怎么将这些「独家秘笈」、行业 know-how 与大模型更好地结合。至于算力与大模型强耦合的工作,他们更愿意交给更有经验的合作伙伴。
在这些方面,昇腾已经积累了二年多经验。北京昇腾人工智能生态创新中心 COO 李天哲说到,我们调优有很好的经验,系统级的工程上也做了很多的优化,保证机器的高可用。
在服务定价上,「我们不收回一次性投入数据中心的成本,只收运维的费用(比如电,水,物业等)。」李天哲说。价格相当于现在市场公有云、对外提供算力 IDC 价格的二分之一到三分之一,如果是门头沟区的企业,费用仅为云上企业的七分之一。
相较于算力充沛、高可用和普惠,计算中心面临的最大挑战还是基于国产、全栈自主可控算力系统的易用性。 现在计算中心也通过两大服务,提升平台的易用性,尽量降低客户对国产底层硬件的感知。
一个是开源的大模型服务。在昇腾自主可控的全栈基础底座能力上,主动安排技术人员积极适配业界主流的开源大模型。
目前,计算中心基于昇思 MindSpore/MindFormers 套件,已成功适配 LLaMA、ChatGLM、Bloom、PanGuAlpha、GPT 等主流开源 NLP 大模型和 VIT、Swin 等主流开源 CV 大模型。
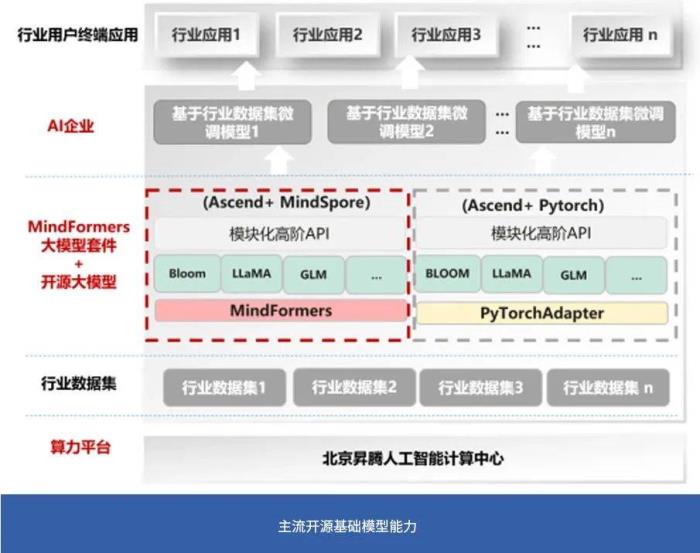
计算中心还做了很多兼容第三方的算子模型还有框架,甚至引入一些加速库和推理服务,服务上层不同框架、模型的 AI 应用。
现有基于其他系统研发的软件是否能容易地迁移到国产生态中,也是易用性的一个重要指标。为了让大模型方便地迁移到昇腾平台,计算中心也积极拥抱 Huggingface等开源社区,做了很多工具套件。比如,只需 5 行代码就能快速将模型从 Huggingface 迁移到计算中心。目前计算中心已经完成了超过 200 个 AI 模型的迁移。
第二个服务就是技术工程师提供贴身技术服务,包括支持训练、微调和在线推理服务( FaaS ,微调即服务)。
告诉我们你用的什么基础模型,把一些公开非涉密的数据上传到计算中心,不用企业再去做太多模型调优,我们就能帮你调好,一到两个月的时间就能交付。李天哲解释说,到时企业直接上来训练就行了。
「我们在门头沟有一个本地化的十几人团队专门做这种技术服务。」杨光说。现在,也在慢慢将一些上层应用封装成服务,我们对上层算法进行了部署,企业只需上传数据,就能立刻使用。

北京昇腾人工智能计算中心已经完成了超高清视频修复增强算法部署。
把脉趋势:为何百亿行业大模型先行?
作为计算中心第一批使用者,中科视语在这里完成了坤川大模型的研发及优化工作。
「我们的感知模型最新成果 Fast Sam,对标的是 Meta 提出的 SAM( Segment Anything Model,SAM ),在同等效果下,速度提升 50 倍,就是在门头沟区的计算中心实现的。」中科视语联合创始人张腊告诉大家。
公司视语通途®智慧交通解决方案在应用场景中实现精准感知、高效运算、快速检索等能力,也充分利用了昇腾 AI 能力。比如,基于针对 AI 场景推出的异构计算架构 CANN 及细粒度正则化模型压缩技术实现了模型高效推理;在 MindX SDK 帮助下,优化了业务效率 。
 中科视语无人驾驶道面病害智能检测车
中科视语无人驾驶道面病害智能检测车
医渡科技的行业模型也是本地企业与计算中心密切合作的典型例子。 「我们希望做中国医疗领域最好的科学大模型,」医渡云首席数据科学家彭滔告诉我们。这家医疗 AI 技术公司已经嗅到大模型给医疗领域带来的巨大机遇:公司的业务场景会拆解成很多产品,它们都有可能被大模型的崭新能力升级一遍。
比如,一个新药从科学家研发到最后的上市,可能需要十五年时间、二十六亿美金,大部分花在临床实验上。其中,临床实验的执行阶段具有知识密集、时间地域跨度大、人员流动性强的特点,这也导致企业投入数亿美金,但执行结果往往像开盲盒。类似 ChatGPT 这样的技术可以将繁复的文档查询转化为一个问题,有利于实验执行阶段新进人员快速掌握背景知识,增加结果可控性。
医渡科技的行业大模型目前有两个版本( 70 亿、130 亿),公司也在与计算中心合作,「调一些基座的模型,叠加数据进行持续的精进,通过轻量的工具达到更好的效果。」 彭滔说。医渡科技有自己的优势,积累了相当多的医学洞见和疾病知识图谱,也在不断尝试如何更好地将知识图谱与大模型相结合。
在智慧体感方面深耕的北京格灵深瞳信息技术股份有限公司与昇腾之间的合作已有 5 年之久。据格灵深瞳副总经理周瑞介绍,公司目前正在图像大模型预训练、微调以及计算加速等底层技术上与计算中心合作。另一方面,大模型落地方面也依托计算中心,提供推理服务。

格灵深瞳大规模沉浸式人机交互系统是一种可以提供沉浸式交互体验的空间型XR产品,游戏是其主要应用领域之一。
目前,计算中心在智慧能源、智慧医疗、智慧城市、智慧交通、智慧金融等行业输出基于昇腾 AI 基础软硬件平台的创新解决方案已经超过 250 项。
根据昇腾对大模型发展趋势的判断,未来千亿大模型会走向收敛,行业大模型将迎来百花齐放,其中,百亿级别的行业大模型大约占 75%,构成算力需求主体,也是昇腾 AI 基座重点支撑的对象。
具体而言,大模型的第一个发展阶段是千亿级大模型。因为知识量非常庞大,它会是千亿训练、千亿推理,用一些高端的卡(像以前的训练卡)去做模型推理。落地场景可能会以 2C 为主,就像 ChatGPT 、百度文心一言和讯飞星火大模型都有人机对话的功能。
对于 2C 来讲,人工智能大模型还有很长的一段路要走,面对很多的用户量和算力需求,最终怎么落地,客户怎么付费?怎么降低推理成本?都是很大的挑战。
在第二阶段,会有大量分布在中长尾部分,面向行业的大模型。 我们估计大部分是 7B、13B 的模型,13B 可能会是一个面向行业的大模型主流规模。杨光解释道。因为,与千亿级的通用大模型相比,行业大模型的推理成本没那么高。一方面,行业知识量要求没有那么通用,参数量不用那么多。另一方面企业用户也会追求极致性价比。
人工智能要走向千行百业,百亿行业大模型的孵化可能会是爆发式,昇腾也因此选用一些百亿规模的行业模型作为算力产品的主要支撑对象。
众人拾柴,自然生长
目前,昇腾 AI 芯片已经孵化了 30 多个大模型,国内原创的大模型一半基于昇腾开发。
相比前大模型时代打造算力底座的繁琐,大模型对国产化平台来说,其实是一个利好。过去视觉领域的模型结构各异,数都数不过来。现在主流开源大模型也就五、六个,很多企业都是基于主流开源模型做改造和训练。
「所以,我们只要把 LLAMA 等几个主流开源大模型的支持做到极致,就能从金融、互联网走向千行百业。」杨光说。
不过,计算中心也认识到自己对这些开源大模型的支持,很难在第一时间完成拟合、适配,会有开发 bug 等问题。这也是他们对培育中国自己的开源社区、打造昇腾 AI 原生大模型抱以极大期待的原因。
我们还在今年推出了面向算子开发场景的昇腾 Ascend C 编程语言。「希望更多算法工程师能用昇腾 Ascend C 来写自己的算子。」杨光说。
计算中心也在与北京高校合作,通过创新大赛、合作创新课程等方式,让昇腾 AI 平台、Ascend C 为更多年轻人所熟悉,伴随他们的成长足迹,一路渗透到行业深处。
发展大模型,算力、模型、生态,缺一不可。昇腾底座能否成为更多行业客户的选择,还是要看企业是否感到好用,要看昇腾的生态,这并非单靠昇腾就能做起来,需要众人拾柴。
这里最关键的是时间,就跟农民种地一样,需要慢慢耕耘,自然生长。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章