新火种
2023-10-29
新火种
2023-10-29 


不可能三角:预训练语言模型的下一步是什么?
 PLM的不可能三角困境。
PLM的不可能三角困境。编译 | 王玥
编辑 | 陈彩娴
近年来,大规模预训练语言模型(PLM)显著提高了各种NLP任务的性能。由BERT和GPT-2开始,自监督预训练范式和监督的微调范式取得了巨大的成功,并刷新了许多自然语言处理领域的最先进成果,如语义相似度、机器阅读理解、常识推理和文本摘要等。此外,这些PLM的规模为中等(即大小低于1B参数),令模型可以做出广泛且快速的微调与适应。
然而在许多真实的、特别是新颖的NLP场景中,由于预算或时间限制,用于有效微调的标记数据非常有限。这就刺激了零样本和少样本NLP模型的开发。
从GPT-3开始,超大规模 PLM (SL-PLM)在只给出任务描述和一些手工示例的情况下,在一般的NLP任务上表现出了优越的性能。这种能力以前在中等规模的PLM中没有观察到。然而,这些SL-PLM前所未有的超大规模在很大程度上阻碍了其广泛应用。人们甚至很难获得足够的计算资源来加载这样的模型,更不用说有效的部署和微调了。因此我们认为,目前还没有一种轻量级PLM在监督学习和一般NLP任务的零/少样本学习场景中都具有出色的性能。这导致了在实际场景中使用这些PLM时需要投入大量的额外工作。
对于PLM来说,似乎产生了中等规模,零/少样本学习能力和微调能力三者不可同时出现的困境。日前,微软认知服务研究小组研究员朱晨光(Chenguang Zhu)及 Michael Zeng在其新论文《Impossible Triangle: What’s Next for Pre-trained Language Models?》中将这种困境称为“不可能三角”。
据悉,朱晨光本科毕业于清华姚班,后取得斯坦福大学计算机系博士学位,毕业后进入微软公司,现为微软公司自然语言处理高级研究员。此前,AI科技评论对朱晨光博士做过一次人物专访,更多内容可看:《朱晨光:一个从不通宵的AI研究员》。
不可能三角
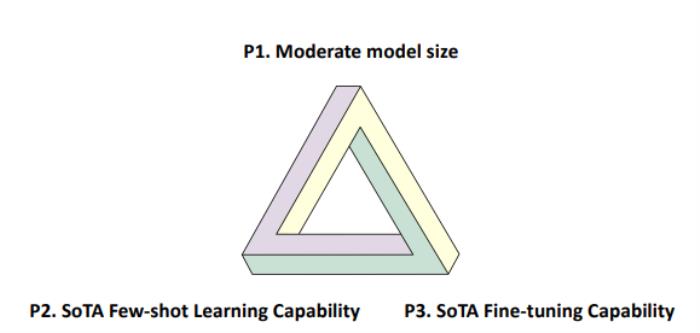
PLM的不可能三角包含了在实际场景中部署模型所需的三个属性,分别是:
P1:模型规模适中,即参数小于10亿
P2:SoTA少样本学习能力
P3::SoTA微调能力
三角形图源:https://commons.wikimedia.org/wiki/File:Penrose_triangle.svg
图为描述当前PLM障碍的不可能三角形,这个三角形描绘了三个PLM关键属性:P1,即模型规模适中,P2,即SoTA少样本学习能力,以及P3,即SoTA监督学习能力。这三个属性对应于PLM实际应用中的三个要求:P1是使用合理数量的计算资源进行高效部署;P2对应标记数据为零或很少的情况;而P3对应标记数据相对丰富的情景。
不可能三角形存在的一个原因是,在当前阶段,只有当PLM达到极大的规模并具有足够的模型容量时,才会拥有强大的少样本学习能力。虽然iPET设计了中等大小的PLM,从而实现比GPT-3更佳的少样本学习性能,但已经被后来的SL-PLM(如PaLM)超越。随着模型规模的增大,我们可以观察到零样本/少样本学习性能的不连续改善。例如,与参数为8B和62B的模型相比,参数为540B的PaLM在许多任务上的准确性都有了巨大飞跃。因此,开发出一个具有SoTA零/少样本学习性能的中等大小模型,同时又保持高超的监督学习能力,仍然是一个巨大的挑战。
虽然没有一个PLM能实现不可能三角中的所有三个特性,但许多PLM已经具备了其中的一or两个属性:
中等规模的PLM(具备P1 + P3的属性),这些语言模型属于中等大小,参数小于10亿个,从而能够有效地进行模型调优和部署。它们在一般的NLP任务中都可以达到SoTA性能,这些NLP任务包括GLUE基准测试、文本摘要、开放域问题回答和常识推理等。然而这些模型的零/少样本学习能力通常相对较弱,这意味着使用这些模型需要依赖目标域中足够的标记数据。
具备P2属性的超大规模PLM,这些语言模型有极大的规模(参数从10到1000亿不等),且已经在超大规模的数据上预训练过。拥有5400亿个参数、在7800亿个单词的文本语料库上进行了预训练的PaLM就属此列。当只提示任务描述和少量输入输出对示例时,他们在一般的零/少样本NLP任务中已经实现了SoTA性能。然而总的来说,1)SL-PLM的零/少样本学习性能低于有监督训练的模型,2)经过微调后,许多SL-PLM的性能仍然低于最好的经过微调的中等大小的PLM,这可能就是因为它们的模型规模太大。
改善措施
由于不可能三角的存在,学界和工业界采取了许多措施来解决实践中所使用的PLM所缺少的能力。总结如下:
极大模型(缺少P1):这种情况出现在需要部署一个超大PLM的时候。为了获得一个中等规模、性能与SL-PLM类似的模型,常用的做法是知识蒸馏(KD)。在KD中,较大的模型是老师,较小的模型是学生,从教师的预测分布和/或参数中学习。知识提取在创建更高效的模型时非常有效,只需要牺牲一点性能。然而,这里仍然存在两个问题。首先,学生很难达到和老师一样的表现。其次,SL-PLM的巨大规模阻碍了有效的推理,使它们不方便作为教师模型。
零/少样本学习性能较差(缺少P2)。这对于中等规模的PLM最常见,它们在微调后可以实现SoTA性能,但具有相对较低的零/少样本学习能力。在许多场景中,当缺少足够的标记数据时,希望部署这样的模型。因此,解决这个问题的一种方法是数据增强,生成伪标签和伪数据实例使得模型可以利用这些额外的数据进行有效的监督训练。然而,伪数据质量的参差不齐和不同任务中数据类型的多样性对普遍适用的解决方案提出了挑战。
监督训练表现欠佳(缺乏P3)。这种情况在使用SL-PLM时很常见,在这种情况下,计算资源有限使得微调超大型模型的所有参数变得十分困难。一个典型解决方案是prompt学习。我们可以利用hard prompt,如离散文本模板,或 soft prompt,如连续参数嵌入,以便在微调期间仅更新 hard prompt 词或 soft prompt 参数。这些方法已被证明对于提高SL-PLM 的准确度十分有效。然而,这些方法的效果对prompt以及训练数据的选择非常敏感,且最终效果一般仍然低于监督学习后的中等规模PLM。
以上提到的这些额外工作拖慢了训练和部署PLM模型的进程。而且对于不同下游任务或产品,需要不断进行这些工作。因此,如果一个PLM能够实现这个不可能三角形,则将大大加快模型训练和实用的过程。
展望未来
虽然目前在NLP模型中存在不可能三角形,但研究者认为可以通过三阶段的方法来解决这个问题。
阶段1:开发PLM以达到三角形中的某些属性,并同时改进其他缺失的属性。例如,提高一个具有SoTA监督学习能力的中等规模模型在少样本学习上的效果;或将具有SoTA少样本学习能力的SL-PLM压缩成更小的模型,并使其具有更好的监督学习性能。
阶段2:在一个或几个NLP任务上实现具有所有三个期望属性的PLM。为了实现这一点,可以利用目标任务的特殊性。例如,在某些任务上,模型性能对于训练数据规模的依赖性较小,零/少样本学习和监督学习性能之间的差距较小,等等。
阶段3:在第一阶段和第二阶段的基础上开发在通用NLP任务上实现所有三个属性的PLM。可能使用到的方法有:i) 用更大数据预训练一个中等规模模型; ii) 更好地进行知识蒸馏; iii) 泛化数据增强方法等。一旦一个PLM在通用NLP任务中具备了不可能三角形的所有三个特性,将很大程度上改变整个NLP研究和应用的格局,促进快速、高效和高质量的模型开发和部署。
原文链接:https://arxiv.org/pdf/2204.06130.pdf


相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章