

 新火种
2023-10-28
新火种
2023-10-28 


Aquarium华人CEO分享:机器学习在自动驾驶中落地,核心不是模型,是管道

编辑 | 陈彩娴
当我大学毕业后开始第一份工作时,我自认为对机器学习了解不少。我曾在 Pinterest 和可汗学院(Khan Academy)有过两次实习,工作内容是建立机器学习系统。在伯克利大学的最后一年,我展开了计算机视觉深度学习的研究,并在 Caffe 上工作,这是最早流行的深度学习库之一。毕业后,我加入了一家名为“ Cruise ”的小型创业公司,Cruise专门生产自动驾驶汽车。现在我在 Aquarium,帮助多家公司部署深度学习模型来解决重要的社会问题。这些年来,我建立了相当酷的深度学习和计算机视觉堆栈。与我在伯克利做研究的时候相比,现在有更多的人在生产应用程序中使用深度学习。现在他们面临的许多问题,与我2016年在 Cruise 所面临的问题是一样的。我有很多在生产中进行深度学习的经验教训想与你们分享,希望大家可以不必通过艰难的方式来学习它们。
将ML模型部署到自动驾驶车上的故事首先,让我谈谈 Cruise 公司有史以来第一个部署在汽车上的ML模型。在我们开发模型的过程中,工作流程感觉很像我在研究时期所习惯的那样。我们在开源数据上训练开源模型,将之集成到公司产品软件堆栈中,并部署到汽车上。经过几个星期的工作,我们合并的最终 PR, 在汽车上运行模型。“任务完成了!”我心想,我们该继续扑灭下一场大火。我不知道的是,真正的工作才刚刚开始。模型投入生产运行,我们的 QA 团队开始注意到它的性能方面的问题。但是我们还有其他的模型要建立,还有其他任务要做,所以我们没有立即去解决这些问题。3个月后,当我们研究这些问题时,我们发现训练和验证脚本已经全部崩溃,因为自我们第一次部署以来,代码库已经发生了变化。经过一个星期的修复,我们查看了过去几个月的故障,意识到在模型生产运行中观察到的许多问题不能通过修改模型代码轻松解决,我们需要去收集和标记来自我们公司车辆的新数据,而不是依靠开放源码的数据。这意味着我们需要建立一个标签流程,包括流程所需要的所有工具、操作和基础设施。又过了3个月,我们运行了一个新的模型,这个模型是根据我们从车上随机选取的数据进行训练的。然后,用我们自己的工具进行标记。但是当我们开始解决简单的问题时,我们不得不对哪些变化可能产生结果变得更加敏锐。大约90% 的问题是通过对艰难或罕见的场景进行仔细的数据整理来解决的,而不是通过深度模型架构变更或超参数调整。例如,我们发现模型在雨天的表现很差(在旧金山很罕见),所以我们标记了更多雨天的数据,在新的数据上重新训练模型,结果模型的表现得到了改善。同样,我们发现该模型在绿色视锥上的性能较差(与橙色视锥相比较少见),因此我们收集了绿色视锥的数据,经过了同样的过程,模型的性能得到了改善。我们需要建立一个可以快速识别和解决这类问题的流程。花费数个星期,这个模型的 1.0 版本组装好了,又用了6个月,新推出一个改进版本模型。随着我们在一些方面(更好地标记基础设施、云数据处理、培训基础设施、部署监控)的工作越来越多,大约每月到每周都能重新训练和重新部署模型。当我们从头开始建立更多的模型管道,并努力改善它们,我们开始看到一些共同的主题。将我们所学到的知识应用到新的管道中,更快更省力地运行更好的型号变得容易了。
保持迭代学习
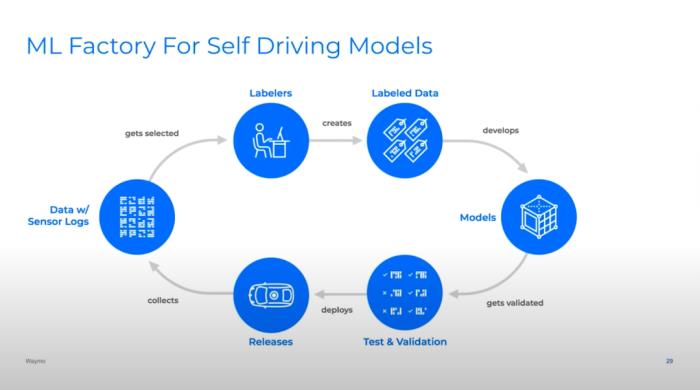
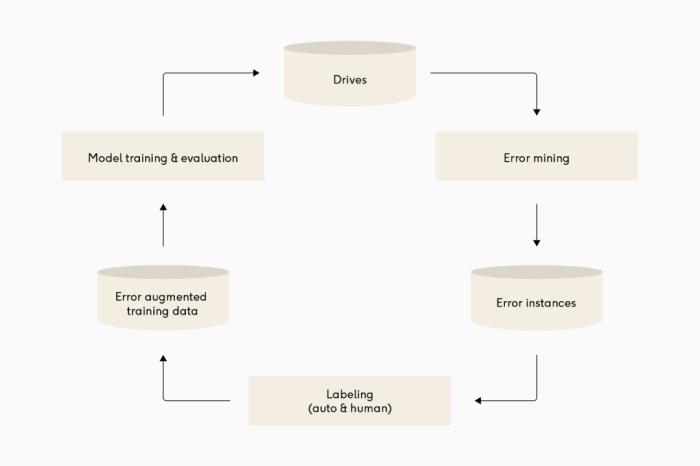
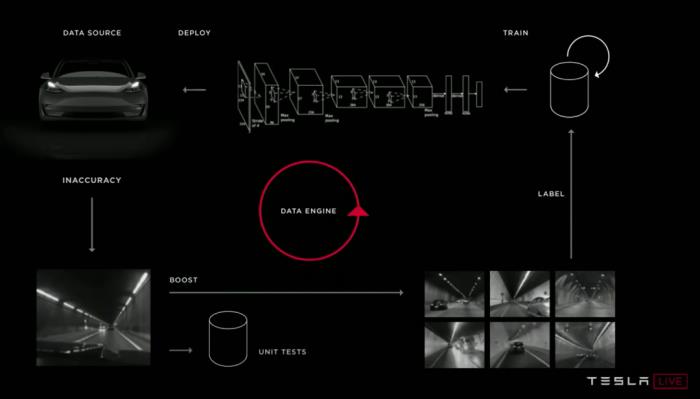
建立反馈回路
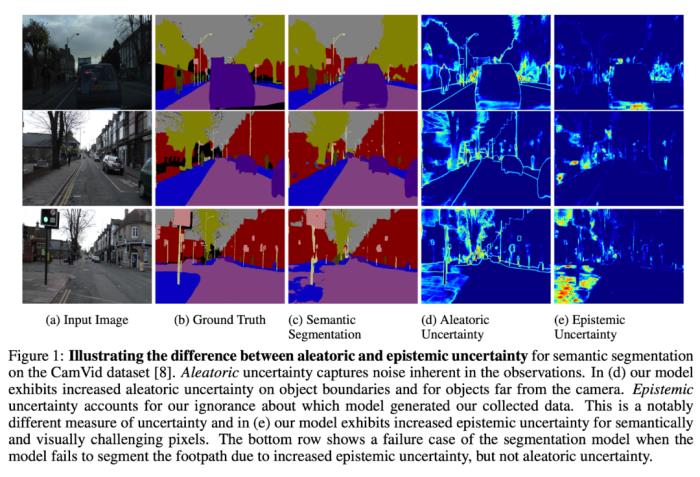 校准模型的不确定性是一个诱人的研究领域,模型可以标记它认为可能失败的地方。对模型进行有效迭代的一个关键部分是集中精力解决最具影响力的问题。要改进一个模型,你需要知道它有什么问题,并且能够根据产品/业务的优先级对问题进行分类。建立反馈回路的方法有很多,但是首先要发现和分类错误。利用特定领域的反馈回路。如果有的话,这可能是获得模型反馈的非常强大和有效的方法。例如,预测任务可以通过对实际发生的历史数据进行训练来“免费 ”获得标签数据,使他们能够不断地输入大量的新数据,并相当自动地适应新情况。设置一个工作流程,让人可以审查你的模型的输出,并在发生错误时进行标记。当人们很容易通过许多模型推断捕获错误时,这种方法尤其适用。这种情况最常见的发生方式是当客户注意到模型输出中的错误并向机器学习团队投诉。这是不可低估的,因为这个渠道可以让您直接将客户反馈纳入开发周期!一个团队可以让人类双重检查客户可能错过的模型输出:想象一下一个操作人员看着一个机器人在传送带上对包进行分类,当他们发现一个错误发生时,就点击一个按钮。设置一个工作流程,让人可以审查你的模型的输出,并在发生错误时进行标记。当人类审查很容易捕捉到大量模型推论中的错误时,这就特别合适。最常见的方式是当客户注意到模型输出中的错误并向ML团队投诉时。这一点不容小觑,因为这个渠道可以让你直接将客户的反馈纳入开发周期中 一个团队可以让人类仔细检查客户可能错过的模型输出:想想一个操作人员看着机器人在传送带上分拣包裹,每当他们发现有错误发生时就点击一个按钮。当模型运行的频率太高,以至于人们无法进行检查时,可以考虑设置自动复查。当很容易针对模型输出编写“健全性检查”时,这尤其有用。例如,每当激光雷达目标检测器和二维图像目标检测器不一致时,或者帧到帧检测器与时间跟踪系统不一致时,标记。当它工作时,它提供了许多有用的反馈,告诉我们哪里出现了故障情况。当它不起作用时,它只是暴露了你的检查系统中的错误,或者漏掉了所有系统出错的情况,这是非常低风险高回报的。最通用(但困难)的解决方案是分析它所运行的数据的模型不确定性。一个简单的例子是查看模型在生产中产生低置信度输出的例子。这可以表现出模型确实不确定的地方,但不是100% 精确。有时候,模型可能是自信地错误的。有时模型是不确定的,因为缺乏可用的信息进行良好的推理(例如,人们很难理解的有噪声的输入数据)。有一些模型可以解决这些问题,但这是一个活跃的研究领域。最后,可以利用模型对训练集的反馈。例如,检查模型与其训练/验证数据集(即高损失的例子)的不一致表明高可信度失败或标记错误。神经网络嵌入分析可以提供一种理解训练/验证数据集中故障模式模式的方法,并且可以发现训练数据集和生产数据集中原始数据分布的差异。
校准模型的不确定性是一个诱人的研究领域,模型可以标记它认为可能失败的地方。对模型进行有效迭代的一个关键部分是集中精力解决最具影响力的问题。要改进一个模型,你需要知道它有什么问题,并且能够根据产品/业务的优先级对问题进行分类。建立反馈回路的方法有很多,但是首先要发现和分类错误。利用特定领域的反馈回路。如果有的话,这可能是获得模型反馈的非常强大和有效的方法。例如,预测任务可以通过对实际发生的历史数据进行训练来“免费 ”获得标签数据,使他们能够不断地输入大量的新数据,并相当自动地适应新情况。设置一个工作流程,让人可以审查你的模型的输出,并在发生错误时进行标记。当人们很容易通过许多模型推断捕获错误时,这种方法尤其适用。这种情况最常见的发生方式是当客户注意到模型输出中的错误并向机器学习团队投诉。这是不可低估的,因为这个渠道可以让您直接将客户反馈纳入开发周期!一个团队可以让人类双重检查客户可能错过的模型输出:想象一下一个操作人员看着一个机器人在传送带上对包进行分类,当他们发现一个错误发生时,就点击一个按钮。设置一个工作流程,让人可以审查你的模型的输出,并在发生错误时进行标记。当人类审查很容易捕捉到大量模型推论中的错误时,这就特别合适。最常见的方式是当客户注意到模型输出中的错误并向ML团队投诉时。这一点不容小觑,因为这个渠道可以让你直接将客户的反馈纳入开发周期中 一个团队可以让人类仔细检查客户可能错过的模型输出:想想一个操作人员看着机器人在传送带上分拣包裹,每当他们发现有错误发生时就点击一个按钮。当模型运行的频率太高,以至于人们无法进行检查时,可以考虑设置自动复查。当很容易针对模型输出编写“健全性检查”时,这尤其有用。例如,每当激光雷达目标检测器和二维图像目标检测器不一致时,或者帧到帧检测器与时间跟踪系统不一致时,标记。当它工作时,它提供了许多有用的反馈,告诉我们哪里出现了故障情况。当它不起作用时,它只是暴露了你的检查系统中的错误,或者漏掉了所有系统出错的情况,这是非常低风险高回报的。最通用(但困难)的解决方案是分析它所运行的数据的模型不确定性。一个简单的例子是查看模型在生产中产生低置信度输出的例子。这可以表现出模型确实不确定的地方,但不是100% 精确。有时候,模型可能是自信地错误的。有时模型是不确定的,因为缺乏可用的信息进行良好的推理(例如,人们很难理解的有噪声的输入数据)。有一些模型可以解决这些问题,但这是一个活跃的研究领域。最后,可以利用模型对训练集的反馈。例如,检查模型与其训练/验证数据集(即高损失的例子)的不一致表明高可信度失败或标记错误。神经网络嵌入分析可以提供一种理解训练/验证数据集中故障模式模式的方法,并且可以发现训练数据集和生产数据集中原始数据分布的差异。自动化和委托

鼓励ML工程师健身

结语总结一下: 在研究和原型开发阶段,重点是建立和发布一个模型。但是,随着一个系统进入生产阶段,核心任务是建立一个系统,这个系统能够以最小的努力定期发布改进的模型。这方面你做得越好,你可以建造的模型就越多!为此,我们需要关注以下方面:以规律的节奏运行模型管道,并专注于比以前更好的运输模型。每周或更短的时间内获得一个新的改进型号投入生产!建立一个良好的从模型输出到开发过程的反馈回路。找出模型在哪些示例上做得不好,并向您的培训数据集中添加更多的示例。自动化管道中特别繁重的任务,并建立一个团队结构,使您的团队成员能够专注于他们的专业领域。特斯拉的Andrej Karpathy称理想的最终状态为“假期行动”。我建议,建立一个工作流程,让你的机器学习工程师去健身房,让你的机器学习管道来完成繁重的工作!最后,需要强调一下,在我的经验中,绝大多数关于模型性能的问题可以用数据来解决,但是有些问题只能通过修改模型代码来解决。这些变化往往是非常特殊的模型架构在手头,例如,在图像对象检测器工作了若干年后,我花了太多的时间担心最佳先前的盒子分配为某些方位比和提高特征映射对小对象的分辨率。然而,随着Transformer显示出成为许多不同深度学习任务的万能模型架构类型的希望,我怀疑这些技巧中的更多将变得不那么相关,机器学习发展的重点将进一步转向改进数据集。参考链接:https://thegradient.pub/lessons-from-deploying-deep-learning-to-production/Kendall, A. & Gal, Y. (2017). What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Advances in Neural Information Processing Systems, 5574-5584.


相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









