

 新火种
2023-10-21
新火种
2023-10-21 


Transformer王者归来!无需修改任何模块,时序预测全面领先
原文来源:新智元

图片来源:由无界 AI生成
近年来,Transformer在自然语言处理以及计算机视觉任务中取得了不断突破,成为深度学习领域的基础模型。
受此启发,众多Transformer模型变体在时间序列领域中被提出。
然而,最近越来越多的研究发现,使用简单的基于线性层搭建的预测模型,就能取得比各类魔改Transformer更好的效果。

最近,针对有关Transformer在时序预测领域有效性的质疑,清华大学软件学院机器学习实验室和蚂蚁集团学者合作发布了一篇时间序列预测工作,在Reddit等论坛上引发热烈讨论。
其中,作者提出的iTransformer,考虑多维时间序列的数据特性,未修改任何Transformer模块,而是打破常规模型结构,在复杂时序预测任务中取得了全面领先,试图解决Transformer建模时序数据的痛点。

论文地址:https://arxiv.org/abs/2310.06625
代码实现:https://github.com/thuml/Time-Series-Library
在iTransformer的加持下,Transformer完成了在时序预测任务上的全面反超。
问题背景
现实世界的时序数据往往是多维的,除了时间维之外,还包括变量维度。
每个变量可以代表不同的观测物理量,例如气象预报中使用的多个气象指标(风速,温度,湿度,气压等),也可以代表不同的观测主体,例如发电厂不同设备的每小时发电量等。
一般而言,不同的变量具有完全不同的物理含义,即使语义相同,其测量单位也可能完全不同。
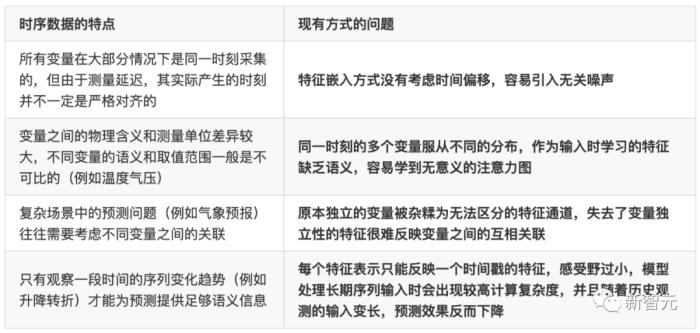
以往基于Transformer的预测模型通常先将同一时刻下的多个变量嵌入到高维特征表示(Temporal Token),使用前馈网络(Feed-forward Network)编码每个时刻的特征,并使用注意力模块(Attention)学习不同时刻之间的相互关联。
然而,这种方式可能会存在如下问题:
设计思路
不同于自然语言中的每个词(Token)具有较强的独立语义信息,在同为序列的时序数据上,现有Transformer视角下看到的每个「词」(Temporal Token)往往缺乏语义性,并且面临时间戳非对齐与感受野过小等问题。
也就是说,传统Transformer的在时间序列上的建模能力被极大程度地弱化了。
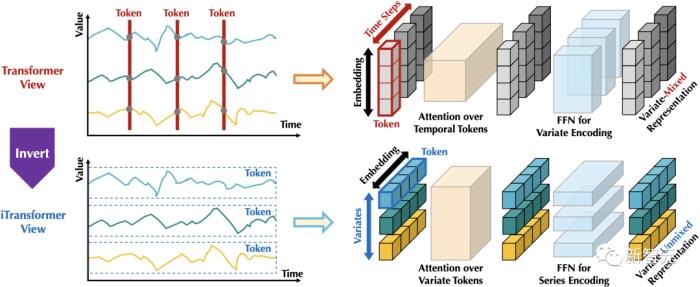
为此,作者提出了一种全新的倒置(Inverted)视角。
如下图,通过倒置Transformer原本的模块,iTransformer先将同一变量的整条序列映射成高维特征表示(Variate Token),得到的特征向量以变量为描述的主体,独立地刻画了其反映的历史过程。
此后,注意力模块可天然地建模变量之间的相关性(Mulitivariate Correlation),前馈网络则在时间维上逐层编码历史观测的特征,并且将学到的特征映射为未来的预测结果。
相比之下,以往没有在时序数据上深入探究的层归一化(LayerNorm),也将在消除变量之间分布差异上发挥至关重要的作用。
iTransformer
整体结构
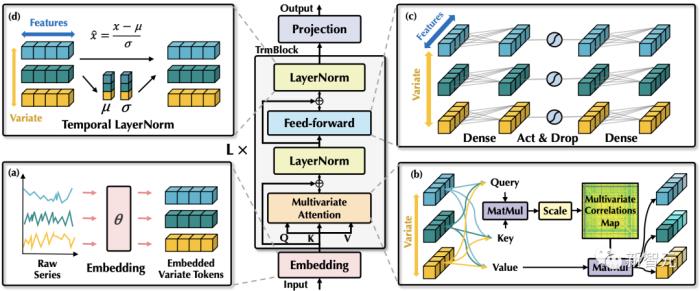
不同于以往Transformer预测模型使用的较为复杂的编码器-解码器结构,iTransformer仅包含编码器,包括嵌入层(Embedding),投影层(Projector)和 个可堆叠的Transformer模块(TrmBlock)。
建模变量的特征表示
对于一个时间长度为 、变量数为 的多维时间序列 ,文章使用 表示同一时刻的所有变量,以及 表示同一变量的整条历史观测序列。
考虑到 比 具有更强的语义以及相对一致的测量单位,不同于以往对 进行特征嵌入的方式,该方法使用嵌入层对每个 独立地进行特征映射,获得 个变量的特征表示 ,其中 蕴含了变量在过去时间内的时序变化。
该特征表示将在各层Transformer模块中,首先通过自注意力机制进行变量之间的信息交互,使用层归一化统一不同变量的特征分布,以及在前馈网络中进行全连接式的特征编码。最终通过投影层映射为预测结果。
基于上述流程,整个模型的实现方式非常简单,计算过程可表示为:
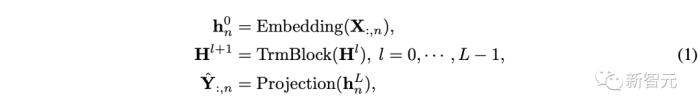
其中 即为每个变量对应的预测结果,嵌入层和投影层均基于多层感知机(MLP)实现。
值得注意的是,因为时间点之间的顺序已经隐含在神经元的排列顺序中,模型不需要引入Transformer中的位置编码(Position Embedding)。
模块分析
调转了Transformer模块处理时序数据的维度后,这篇工作重新审视了各模块在iTransformer中的职责。
1. 层归一化:层归一化的提出最初是为了提高深度网络的训练的稳定性与收敛性。
在以往Transformer中,该模块将同一时刻的的多个变量进行归一化,使每个变量杂糅无法区分。一旦收集到的数据没有按时间对齐,该操作还将引入非因果或延迟过程之间的交互噪声。
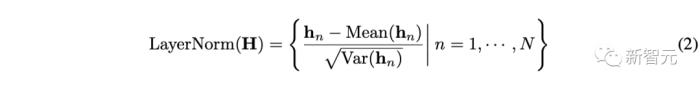
而在倒置版本中(公式如上),层归一化应用于每个变量的特征表示(Variate Token),让所有变量的特征通道都处于相对统一的分布下。
这种归一化的思想在处理时间序列非平稳问题时已经被广泛证明是有效的,只是在iTransformer中可以自然而然的通过层归一化实现。
此外,由于所有变量的特征表示都被归一化到正态分布,由变量取值范围不同造成的差异可以减弱。
相反,在此前的结构中,所有时间戳的特征表示(Temporal Token)将被统一标准化,导致模型实际看到的是过平滑的时间序列。
2. 前馈网络:Transformer利用前馈网络编码词向量。
此前模型中形成「词」向量的是同一时间采集的多个变量,他们的生成时间可能并不一致,并且反映一个时间步的「词」很难提供足够的语义。
在倒置版本中,形成「词」向量的是同一变量的整条序列,基于多层感知机的万能表示定理,其具备足够大的模型容量来提取在历史观测和未来预测中共享的时间特征,并使用特征外推为预测结果。
另一个使用前馈网络建模时间维的依据来自最近的研究,研究发现线性层擅长学习任何时间序列都具备的时间特征。
对此,作者提出了一种合理的解释:线性层的神经元可以学习到如何提取任意时间序列的内在属性,如幅值,周期性,甚至频率谱(傅立叶变换实质是在原始序列上的全连接映射)。
因此相较以往Transformer使用注意力机制建模时序依赖的做法,使用前馈网络更有可能完成在未见过的序列上的泛化。
3. 自注意力:自注意力模块在该模型中用于建模不同变量的相关性,这种相关性在有物理知识驱动的复杂预测场景中(例如气象预报)是极其重要的。
作者发现自注意力图(Attention Map)的每个位置满足如下公式:
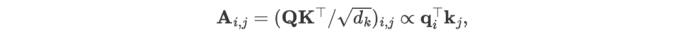
其中 对应任意两个变量的Query和Key向量,作者认为整个注意力图可以在一定程度上揭示变量的相关性,并且在后续基于注意力图的加权操作中,高度相关的变量将在与其Value向量的交互中获得更大的权重,因此这种设计对多维时序数据建模更为自然和可解释。
综上所述,在iTransformer中,层归一化,前馈网络以及自注意力模块考虑了多维时序数据本身的特点,三者系统性互相配合,适应不同维度的建模需求,起到1+1+1 > 3的效果。
实验分析
作者在六大多维时序预测基准上进行了广泛的实验,同时在支付宝交易平台的线上服务负载预测任务场景的数据(Market)中进行了预测。
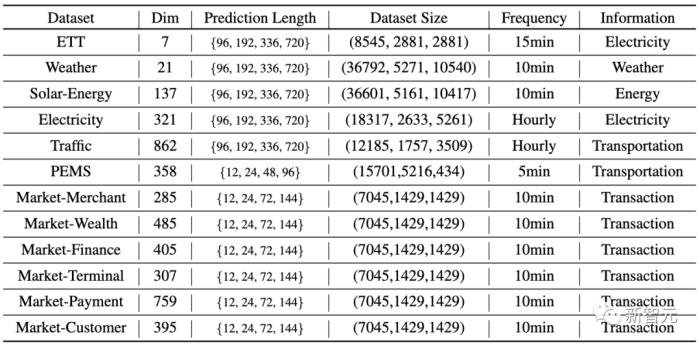
实验部分对比了10种不同的预测模型,包含领域代表性Transformer模型:PatchTST(2023)、Crossformer(2023)、FEDformer(2022)、Stationary(2022)、Autoformer(2021)、Informer(2021);线性预测模型:TiDE(2023)、DLinear(2023);TCN系模型:TimesNet(2023)、SCINet(2022)。
此外,文章分析了模块倒置给众多Transformer变体带来的增益,包括通用的效果提升,泛化到未知变量以及更加充分地利用历史观测等。
时序预测
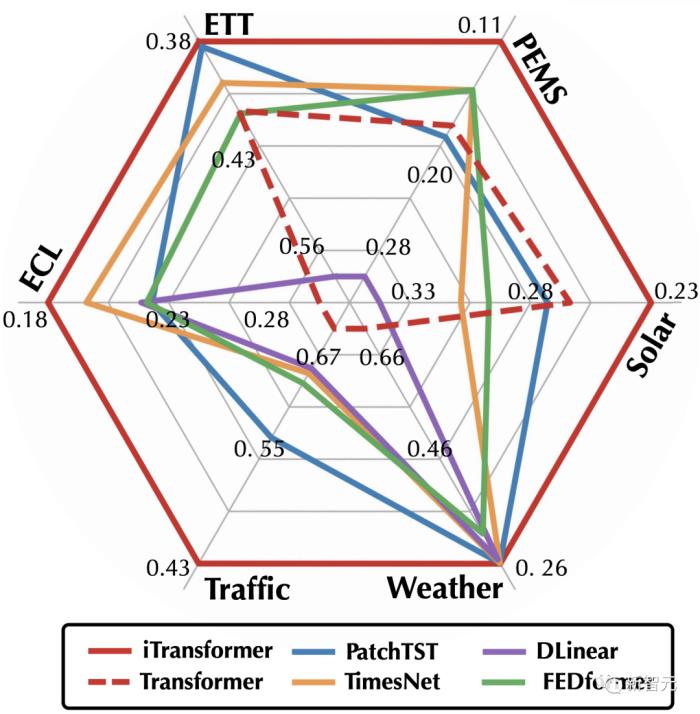
如开篇雷达图所示,iTransformer在六大测试基准中均达到了SOTA,并在Market数据的28/30个场景取得最优效果(详见论文附录)。
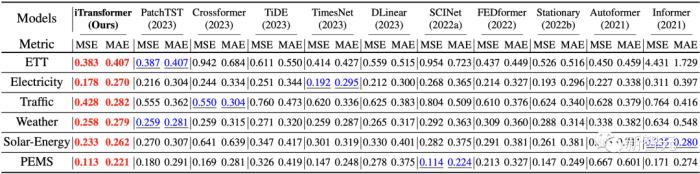
在长时预测以及多维时间预测这一充满挑战的场景中,iTransformer全面地超过了近几年的预测模型。
iTransformer框架的通用性
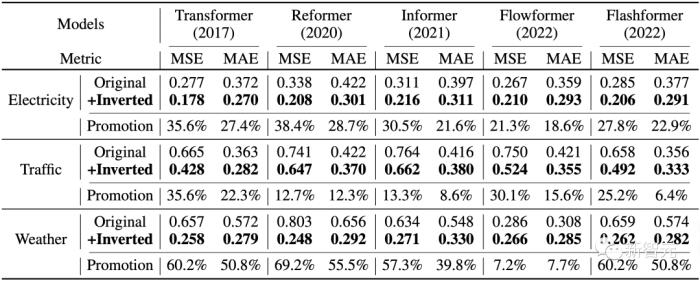
在取得最佳效果的同时,作者在Reformer、Informer、Flowformer、Flashformer等Transformer变体模型上进行了倒置前后的对比实验,证明了倒置是更加符合时序数据特点的结构框架。
1. 提升预测效果
通过引入所提出的框架,这些模型在预测效果上均取得了大幅度的提升,证明了iTransformer核心思想的通用性,以及受益于高效注意力研究进展的可行性。
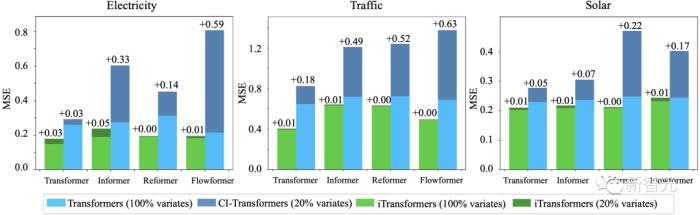
2. 泛化到未知变量
通过倒置,模型在推理时可以输入不同于训练时的变量数,文中将其与一种泛化策略——通道独立(Channel Independence)进行了对比,结果表明该框架在仅使用20%的变量时依然能够尽可能减少泛化误差。
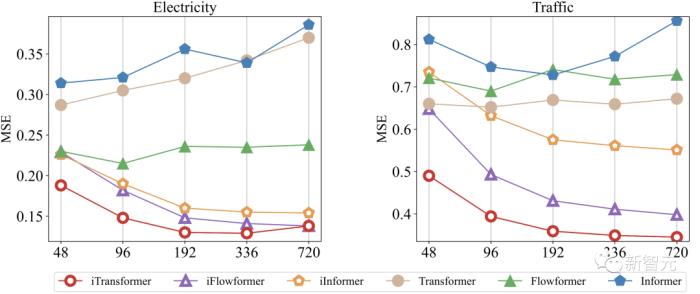
3. 使用更长历史观测
以往Transformer系模型的预测效果不一定随着历史观测的变长而提升,作者发现使用该框架后,模型在历史观测增加的情况下展现出了惊人的预测误差减小趋势,在一定程度上验证了模块倒置的合理性。
模型分析
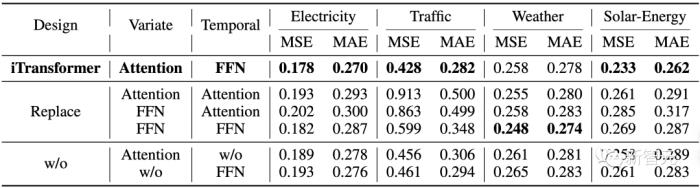
1. 模型消融实验
作者进行了消融实验验证iTransformer模块排布的合理性。
结果表明在变量维使用自注意力,在时间维上使用线性层的建模方式在绝大部分数据集上都取得了最优效果。
2. 特征表示分析
为了验证前馈网络能够更好地提取序列特征的观点,作者基于CKA(Centered Kernel Alignment)相似度进行特征表示分析。CKA相似度越低,代表模型底层-顶层之间的特征差异越大。
值得注意的是,此前研究表明,时序预测作为一种细粒度特征学习任务,往往偏好更高的CKA相似度。
作者对倒置前后的模型分别计算底层-顶层CKA,得到了如下的结果,印证了iTransformer学习到了更好的序列特征,从而达到了更好的预测效果。
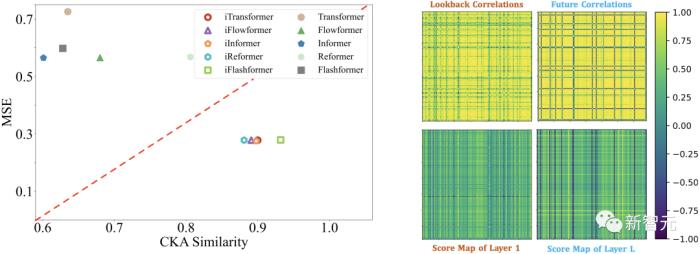
3. 变量相关性分析
如上图所示,作用在变量维的注意力机制在学习到的注意力图中展现出更加强的可解释性。通过对Solar-Energy数据集的样例进行了可视化,有如下观察:
在浅层注意模块,学习到的注意力图与历史序列的变量相关性更加相似。当深层注意模块,学习到的注意力图与待预测序列的变量相关性更加相似。这说明注意力模块学到了更加可解释的变量相关性,并且在前馈网络中进行了对历史观测的时序特征编码,并能够逐渐解码为待预测序列。
总结
作者受多维时间序列的本身的数据特性启发,反思了现有Transformer在建模时序数据的问题,提出了一个通用的时序预测框架iTransformer。
iTransformer框架创新地引入倒置的视角观察时间序列,使得Transformer模块各司其职,针对性完成时序数据两个维度的建模难题,展现出优秀的性能和通用性。
面对Transformer在时序预测领域是否有效的质疑,作者的这一发现可能启发后续相关研究,使Transformer重新回到时间序列预测的主流位置,为时序数据领域的基础模型研究提供新的思路。
参考资料:
https://arxiv.org/abs/2310.06625
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










