

 新火种
2023-10-20
新火种
2023-10-20 


ChatGPT 带火大模型!解读人工智能大模型在产业中的服务新态势
作者 | 李峰
策划 | 凌敏
最早人工智能的模型是从 2012 年(AlexNet)问世,模型的深度和广度一直在逐级扩升,龙蜥社区理事单位浪潮信息于 2019 年也发布了大规模预训练模型——源 1.0。日前,浪潮信息 AI 算法研究员李峰带大家了解大模型发展现状和大模型基础知识,交流大模型在产业应用中起到的作用和 AI 服务新态势。本文整理自龙蜥大讲堂第 60 期,以下为本次分享原文。
大模型现状
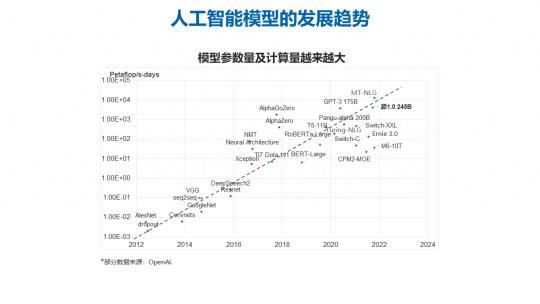
大家可以看到,人工智能的模型其实从最早 2012 年(AlexNet)问世以来,模型的深度和广度一直在逐级扩升,其中比较典型的是到了 2018 年的时候像 BERT-Large 等这种基于 BERT 和 transformer 结构的模型产生之后,兴起了一波模型规模和参数激增的热潮。从 BERT 模型出现到 GPT-3 拥有 1750 亿参数规模的千亿级大模型,大规模预训练模型成了一个新的技术发展趋势。
在 2019 年的时候,浪潮信息也发布了大规模预训练模型——源 1.0。参数量是 2457 亿。站在现在的角度回看历史的发展长河,模型的尺度和规模是在逐级扩增的,这个趋势仍旧是有愈演愈烈的一个情况。
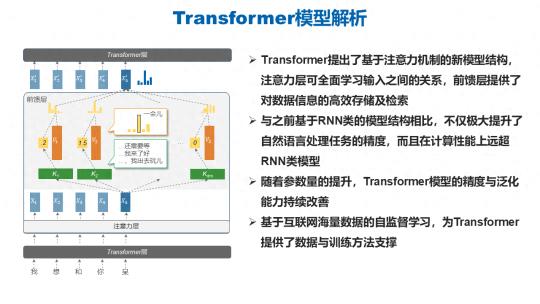
整体大模型的兴起绕不开一个基础模型结构 Transformer。Transformer 架构相当于是在接受输入之后,在内部进行了一个类似于查表的工作,其中的注意力层之所以叫注意力,最大的作用直白的来看就是可以去学习关系,所谓的注意力就是当我们看到一个东西的时候,对他感兴趣我们就会多看一会儿,对另外一个东西没有兴趣或者对它的兴趣比较低,则对它的
用这样的一个注意力层可以更好的去学习所有输入之间的一个关系,最后的一个前馈层又对输入的信息进行一个高效的存储和检索。这样的一个模型结构与之前基于 RNN 的模型结构相比不仅是极大地提升了自然语言处理任务的精度,而且在计算性能上也远超 RNN 类的模型。Transformer 结构的提出极大提升了计算效率和资源利用率。可以看到,在模型构建和训练算法的设计过程当中,算力和算法是相辅相成的,二者缺一不可,也就是我们提出的混合架构的一个算法设计。
另外 Transformer 结构之所以能够做大做强,再创辉煌,另一个根本的原因在于互联网上有相当多海量数据可以供模型进行自监督学习,这样才为我们庞大的水库中投入了庞大的数据资源和知识。
正是这些好处奠定了 Transformer 结构作为大模型基础架构的坚实的地位。
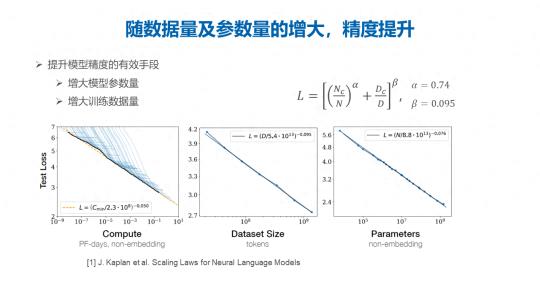
基于对前人的研究调研以及实证研究之后,我们发现随着数据量和参数量的增大,模型的精度仍旧可以进一步的提升,即损失函数值是可以进一步降低的。模型损失函数和模型的参数规模以及模型训练的数据量之间是呈现这样一个关系,现在仍旧处在相对中间的水平上,当模型和数据量的规模进一步增大的时候仍旧可以得到大模型边际效益带来的收益红利。
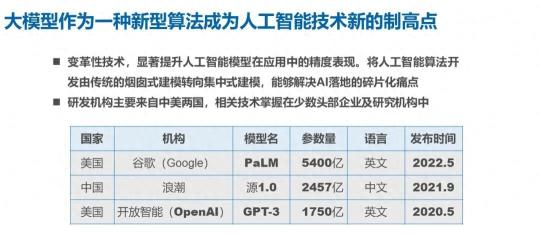
大模型正在作为一种新型的算法,成为整个人工智能技术新的一个制高点和一个新型的基础设施。可以说大模型是一种变革性的技术,他可以显著的提升我们人工智能模型在应用当中的性能表现,将人工智能的算法开发的过程由传统的烟囱式开发模式转向一种集中式建模,解决 AI 应用落地过程当中的一些场景碎片化、模型结构和模型训练需求零散化的痛点。
另外我们能看到的是对于大模型这个领域里面的玩家,主要是来自中美两国。从 GPT3 发布以后我们国内也开始相应的有不同的参数规模的模型来去引领世界大模型业界的一个浪潮。正如我们之前提到的,在大规模预训练模型里面,模型参数提升带来的边际收益仍旧存在,所以大家在短期之内仍旧在吃这种大模型参数提升带来的收益红利。
浪潮·源 1.0 大规模中文自然语言模型
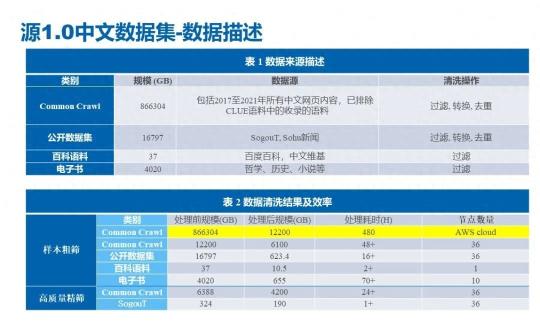
浪潮·源 1.0 大规模中文自然语言处理模型有 2457 亿参数,于 2019 年的时候 9 月份发布,在发布之时,凭借参数量登顶了业界规模最大的中文自然语言的单体模型。在这个模型整个构建的时候,最大的一个问题就是数据,数据集从哪来,怎样去构建,包含哪些内容。这里给大家列了一个表来简单阐述,源 1.0 的中文数据集包含了有互联网中文社区近五年的所有数据,以及一些公开数据集、百科、电子书等原始语料,总计超过 800TB。
我们对原始语料做了过滤转换、去重,之后构建了打分模型对所有的样本语料进行高质量和低质量的判定。经过一系列的处理,最终我们得到了 5T 的高质量中文语料数据集,这个语料数据也是目前中文语料当中规模最大,质量最高的语料库。我们的一些合作伙伴也拿我们公开的语料数据进行了一些模型的预训练,也是成功登顶了 CLUE 等测评榜单。
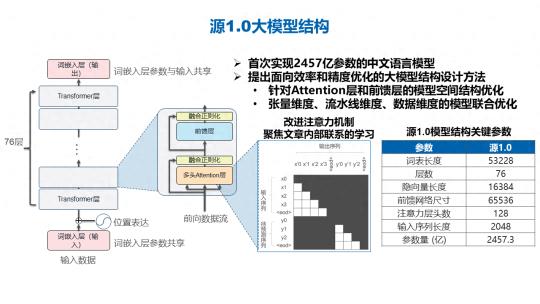
源大模型的结构上也做了一些创新,一方面是 2457 亿的参数,这个参数主要是基于 Transformer 的解码层结构进行了堆叠,也首次面向计算的效率和精度优化方面做了大模型的结构设计,针对 Attention 层和前馈层的模型空间结构也做了一些优化。我们改进的注意力机制来聚焦文章内部的联系,之后在整个计算过程当中我们也采用了张量并行、流水并行和数据并行三大并行方式来做模型的联合优化,从而提升模型训练的效率。
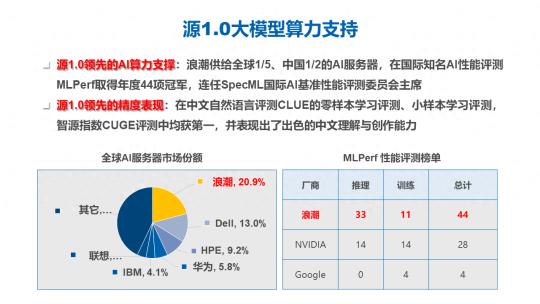
源大模型在整个训练阶段,因为模型结构和模型参数如此巨大,就需要更大规模的算力跟算力优化的能力支持。浪潮信息供给了全球五分之一,中国 50% 的 AI 服务器,并且在 MLPerf 等等这些与 AI 计算相关的比赛和精度优化、计算优化的比赛当中也是获得了非常多的冠军,也连任了 SpecML 的评委的主席,在这些过程当中我们积累下来的 AI 计算和性能优化方面的这些能力也在源 1.0 的训练过程当中被重复的赋能,所以我们的源 1.0 在训练过程当中,有非常强大的 AI 算力支持。
在大模型训练方面,我们采用了 2128 块 GPU,在单个 GPU 上的实际性能和理论性能的比值达到了 45%,远高于 GPT3 和 MT-NLG 等模型的训练过程。对于计算性能的提升会带来非常大的绿色环保的收益以及人力成本、时间成本上的收益。
源 1.0 在中文的自然语言测评的 CLUE 的零样本学习和小样本学习测评当中,获得了业界第一的水平,在智源指数 CUGE 上面的评测也获得了总分第一的成绩。模型除了可比较、可量化的评价标准以外也表现出非常丰富和出色的中文理解和创作能力,后文也有一些基于源 1.0 落地的应用实例,跟合作伙伴一起开发和赋能的相关案例,也会做一个简短的介绍。
我们在 WebQA 和 CMRC 的测评上面也横向比较了当时业界我们国内的一些模型的水平,可以看到在这两个任务上面我们也达到了一个业界高水平的成绩。
基于源 1.0 的技能模型构建
大模型带来优异的精度表现和泛化能力,也带来一系列的问题。模型太大,部署起来会比较麻烦,因此我们基于源 1.0 在不同领域上面针对不同的任务构建了一些技能模型。
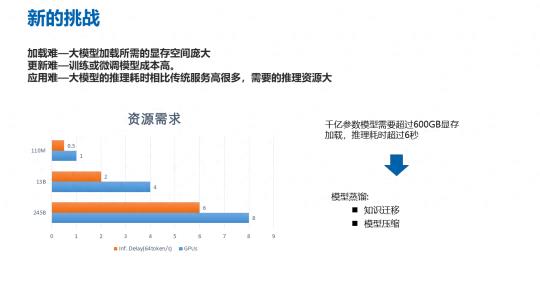
在实际应用当中,有 2000 多亿参数的大模型加载所需的显存空间就非常庞大。千亿参数模型需要用 8 张 GPU 卡做部署,推理时间要达到 6 秒多,而用百亿参数模型只需要 4 张 GPU 卡就可以实现 2 秒钟的推理效率,推理效率的提升还是比较明显的,这样的模型在实际的应用当中,尤其是对实时性要求较高的应用是非常占优的。
大模型的更新也比较困难,2000 多亿参数的模型,训练和微调的成本非常高,如果训练数据量少起不到对于这么庞大模型的所有参数更新的作用,如果训练数据规模大,虽然它的参数会被整体进行更新,但是会带来两个比较大的问题,一个是训练成本本身会变得很高,另外一个就是大规模的数据在训练过程当中有可能带来灾难性的遗忘,这会导致模型本身原有的泛化能力会有所衰减。还有就是应用困难,大模型的推理耗时相比传统服务高好多,推理的资源需求也会大很多。千亿参数的模型需要超过 600GB 的显存进行加载,推理时间超过 6 秒。因此我们希望采用知识迁移和模型压缩的方式来实现模型蒸馏。
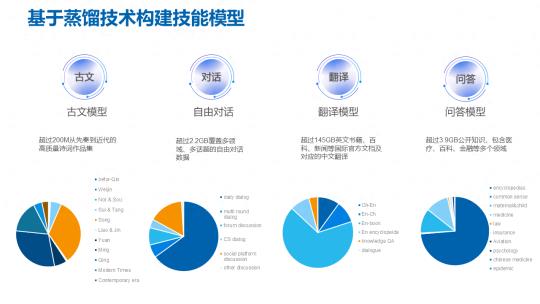
为了构建技能模型我们对一些典型场景进行了数据收集,一种是古文,古诗文是中国传统文化的一个艺术结晶,因此我们希望能够通过现代的技术去挖掘古代的文学之美,所以我们去收集古文类的所有的数据和样本,然后去训练一个古文模型来去实现让大模型来做吟诗作对的这样一个能力。另一个是对话场景,我们对于自由对话场景收集了超过 2GB,覆盖多领域多话题的自由对话数据,以它为基础,我们后续要进行模型的蒸馏。
关于中英文翻译场景,我们收集了超过 145GB 的英文书籍和百科、新闻等国际官方文档,以及他们对应的中文翻译,期望在后续可以做翻译的模型。还有一个是问答场景。我们共收集了超过 3.9G 的公开知识,包括医疗、百科、金融等等多个领域。期望在后续可以去做问答的模型来匹配这样的一个知识问答场景。
无论是在做什么样的模型的时候,算法里面叫百算数为先,无论构建什么样的算法,我们都要从应用场景出手,在我们的模型开发实践过程当中都是以场景和场景所需要的数据着手,首先进行数据准备,之后才是相应的模型算法上面的一个开发工作。

在传统意义上或者是在过去我们的一些算法实践当中,模型压缩一般是压缩到 60%、50%,甚至相对大一点的时候把模型压缩到原有模型的 40%,我们想要把千亿参数模型进行 10 倍压缩,然后我们去探索在这个压缩过程当中所使用的方法,从相应的实践当中去积累经验,进一步把百亿参数模型再往亿级参数模型去压缩。
想要做模型压缩,第一个是需要确定参数的初始化方法:一种是采用 PKD 的 skip 方式,采用跳层的方式去保留其中需要的层数,使得模型宽度保持不变的情况下让深度降低,从而达到减少参数量的目的,这种方式会使模型的抽象表达的能力变弱。
第二种方式是采用 Hiddensizetransformation,模型的深度不变,而把模型宽度上面进行一个压缩,但模型特征抽取的能力就会变得非常弱,从我们的实践当中也发现采用这样的线性压缩变换都会导致模型在训练过程当中的稳定性变差,模型收敛会呈现一个波动的状态。
第三种方式是基于预训练的方法,根据期望的训练时长和模型推理的延迟等要求,预先设定相应的模型结构,在已有的数据上做预训练,把这个预训练出来的模型当做学生模型,在此基础上再用专业数据集结合千亿参数模型,对这个百亿参数模型进行进一步的知识蒸馏,采用这样的方式降低了模型开发的成本,同时可以很好的保留模型宽度跟深度上的一些结构。
第二个问题是模型的蒸馏的策略。蒸馏的时候究竟是以渐进式的知识迁移方式为主还是以辅助式的知识迁移的方式来进行模型蒸馏。渐进式知识迁移的精度和性能表现是比较好的,但是计算成本很高。
除了以上,还有一种模型压缩的方式是直接同步的指导 studentmodel 里面对应的对应层,在 loss 层面上面做一个加权,采用这样的方式叫 AKT 的方式,这两种方式的模型精度表现上面差异不大,但是对于采用 AKT 的方式,在一次训练过程当中可以同步的去更新所有的 Transformer 结构里面所需要的参数,这样它的计算就远比渐进式的方式计算开销要小很多。所以浪潮信息采用 AKT 的方式来进行模型压缩。transformer 结构里面包含的主要有三个东西:Embedding、Hiddenstate 还有 Attentionmatrics。
如果在 Embedding 跟 Hiddenstate 上面做知识迁移,蒸馏前后的矩阵维度是不匹配的。因此我们对 Attentionmatrics 里面 K、Q、V 三个矩阵做知识蒸馏,可以保证一方面维度不需要去考虑这个问题,另外一方面,在 transformer 当中,在最上面的内容里其实提到过,transformer 里面的 K、Q、V 矩阵,一方面做了知识的存储,另外一方面,可以最大限度的保留知识跟关系之间的一些信息。
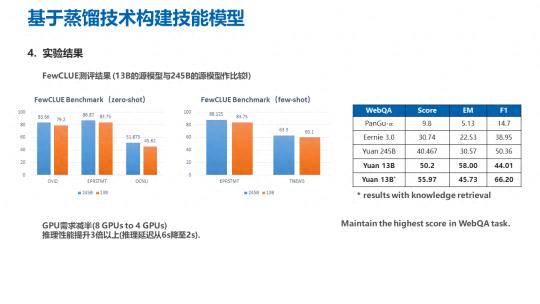
最终的实验结果,百亿参数的模型在 FewCLUE 上面与千亿参数模型进行比较,可以看到模型的精度、损失是相对比较小的,是可以接受的。而计算资源的需求从 8 个 GPU 下降到了 4GPU,推理延迟也从 6 秒一直降至 2 秒,推理性能提升非常显著。在 webQA 的问答数据集上进行测评,可以看到百亿参数的模型,因为在构建过程当中,经过了知识蒸馏,得到的性能表现甚至优于了原来直接训练出来的千亿参数模型,也是达到了业界领先的程度。
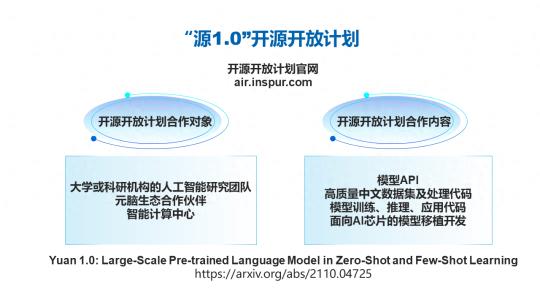
我们秉承着构建开源社区,提升大家在大模型里面的应用能力,做了大模型的开源开放计划,构建了开源的一个官方网站(air.inspur.com),针对大学或科研机构的人工智能研究团队、浪潮信息的元脑生态伙伴,还有各种智能计算中心,以及对于中文自然语言理解和大模型感兴趣的各类开发人员和开发者进行免费开放,大家可以通过官网进行申请注册。开源开放的内容包括在官网上有模型的 API,以及高质量中文数据集和相应的处理代码开放出了 1T 的数据,这些只需在官网上进行申请就行。
另外,模型训练推理和应用的相关代码也在 github 上进行了开源,我们秉持一个开放的态度,鼓励并且面向 AI 芯片的合作伙伴与大家合作,做模型相关的迁移和开发工作。

上图展示我们开源开放的一些工具,在官网上面我们构建的一个 APIExp 的线上测试工具,可以零代码的去实现对应参数 API 的交互和实验。另外,我们也提供了沙箱,通过简单的设置,就可以展示出想要设计的开发应用,在上线之后大概是一个什么样的交互方式和交互的结果。
源 1.0 大模型创新及实践
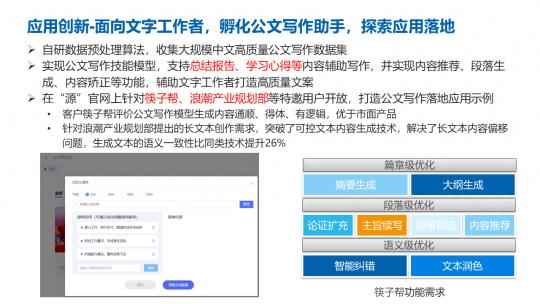
最后,大模型在开源开放之后也迎来了非常多的合作,吸引了超过一千三百多的开发者,来自不同的行业和不同的应用场景,注册并基于我们的源 1.0 大模型,进行不同应用的开发。这里给大家看到的是一些简单的事例,如图是我们和西安筷子帮共同去开发的公文写作助手,可以支持总结报告、学习心得等等内容的辅助写作。针对长篇写作内容的场景里,我们在可控文本生成上面做了一系列的研究,解决长文本内容偏移的问题,生成的文本的语意的一致性也是比同类技术提升了 26%。

另外我们做了智能问答系统,在内部的智能客户的机器人上面,问题匹配率也是达到了 92.6%,然后依赖客服机器人去解决问题的成功率达到 65%。整体的应用使用也是有所提升,这一个项目也是获得了今年哈佛商业评论里面鼎革奖的年度技术突破奖。
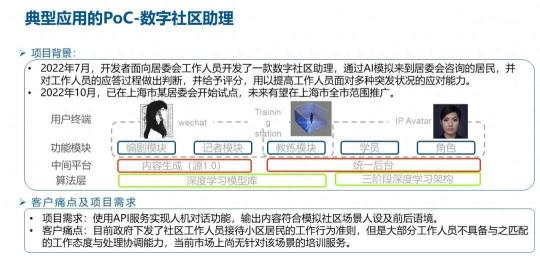
还有一些比较典型的应用,这个是和我们的开发者,一起来做的一个 PoC 项目,面向数字社区的助理。开发者面向数字社区的工作人员,提供了一款数字助理,通过采用大模型来模拟到居委会进行投诉,或者是进行咨询的居民,然后来模拟他们的对话,并且对工作人员的回答做出一个判断,并且予以评分。通过这样的方式来提高工作人员面对突发情况的应对能力。
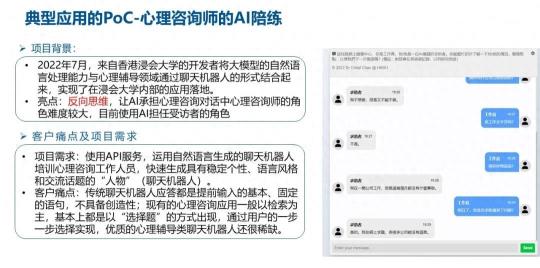
在另外一个场景里我们跟香港的浸会大学的教授一起基于大模型自然语言处理能力,开发一种心理辅导的培训机器人。这种也是基于这样的反向思维,让 AI 去承担心理咨询对话当中的求助者的角色,让咨询师根据心理来做求助的患者。
通过这样的方式,我们可以用大模型模拟可能存在问题的输入,通过标准工作者的工作内容去得到相应标准的答案。这其实也是互联网思维的一个非常典型的叫羊毛出在猪身上,我们通过这样的方式,也可以获取非常多标准的数据集和针对应用场景下的标准数据集,有这些数据的情况下,反过来之后,我们再对大模型做微调之后模型就有能力去扮演工作人员的角色,然后对心理咨询的患者直接进行辅导。这样的过程其实就是在 ChatGPT 当中提到的 RLHF 的人环强化学习的一种合理的运用。
本文转载来源:
https://www.infoq.cn/article/KDhdcyKx639AQIfYGQSA
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章









