

 新火种
2025-02-21
新火种
2025-02-21 

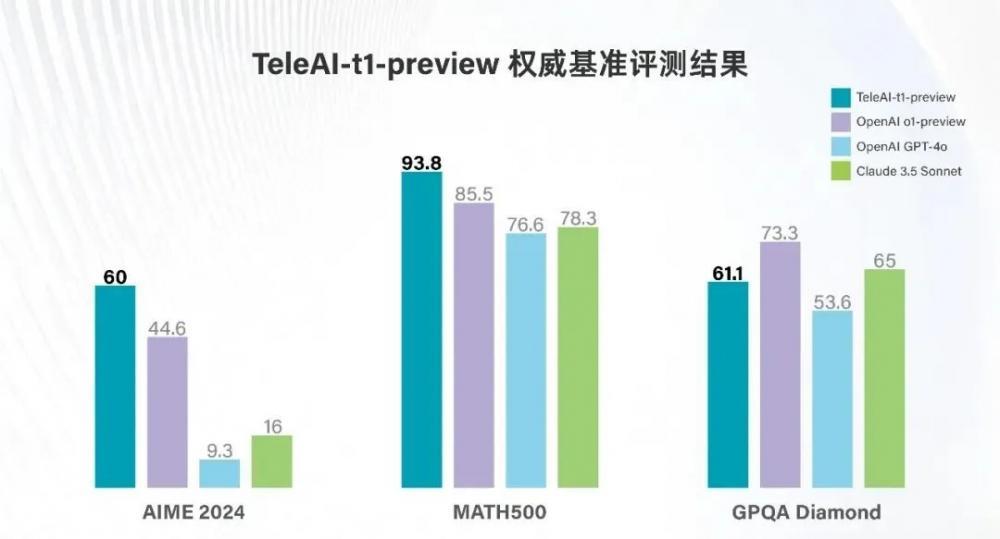

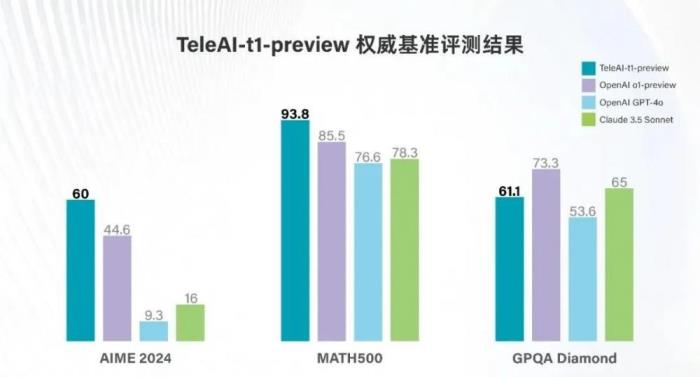
中国电信发布“复杂推理大模型”达竞赛级数学表现,评分超o1-preview
近日,中国电信人工智能研究院(TeleAI)“复杂推理大模型”TeleAI-t1-preview正式发布。TeleAI-t1-preview使用了强化学习训练方法,通过引入探索、反思等思考范式,大幅提升模型在数学推导、逻辑推理等复杂问题的准确性。在美国数学竞赛AIME 2024、MATH500两项权威数学基准评测中,TeleAI-t1-preview分别以60和93.8分的成绩,大幅超越OpenAI o1-preview、GPT-4o等标杆模型。在研究生级别问答测试GPQA Diamond中,TeleAI-t1-preview得分超过 GPT-4o,并比肩Claude 3.5 Sonnet的性能水准。
以2024年全国高中数学竞赛试题为例,TeleAI-t1-preview面对三角函数的复杂等式关系,通过多次假设尝试和思路纠偏,将原先的复杂等式抽丝剥茧,转化成简化的方程式,并经过逻辑清晰的公式推导后,最终给出了正确答案。
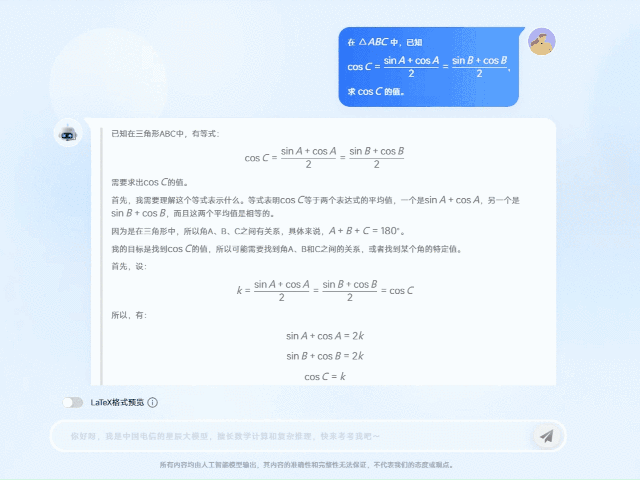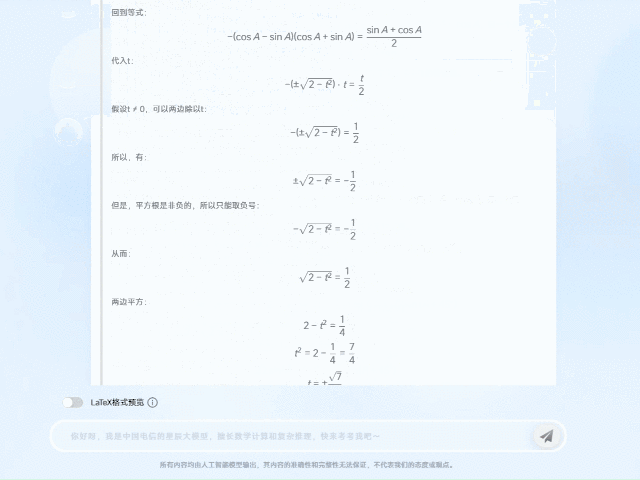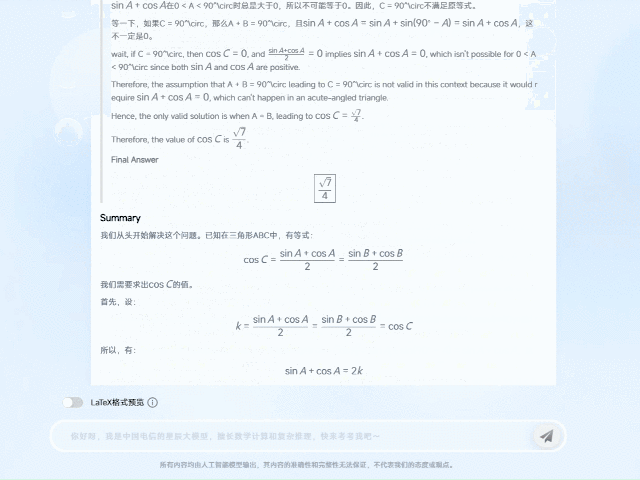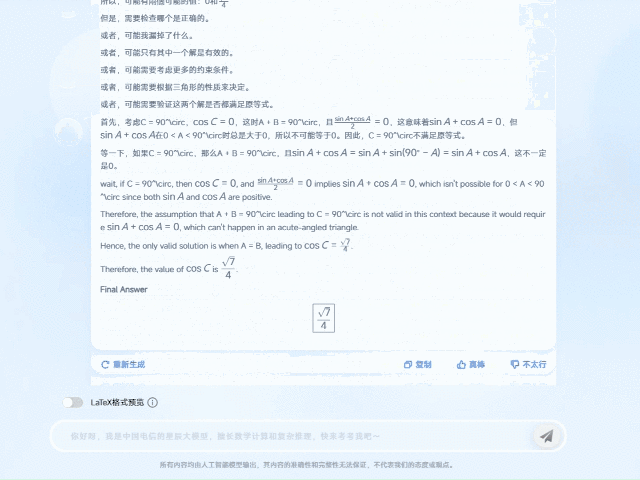
TeleAI-t1-preview在回答问题时并非只是给出结论,而是把思考和分析过程也完整呈现。这样可以帮助学生在做题过程中深入理解题目背后的逻辑和思考方法。
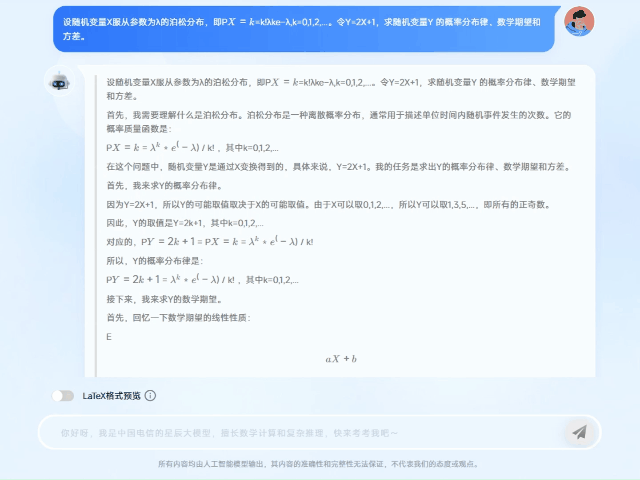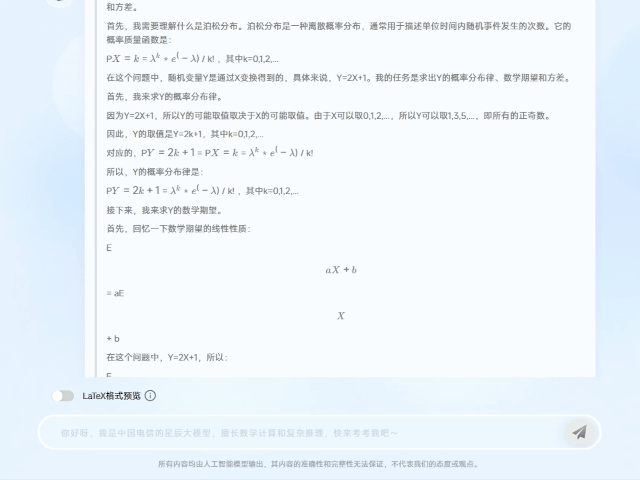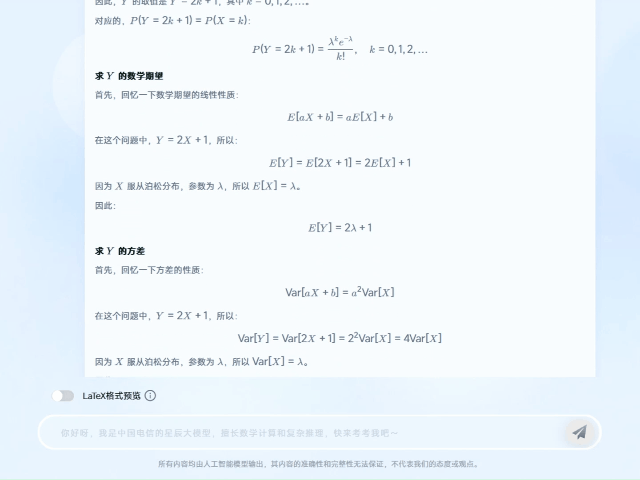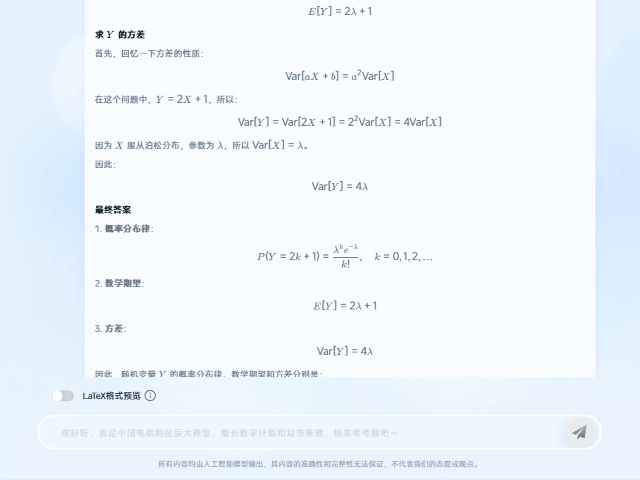
在一道概率论考研试题中,题目涉及“泊松分布”概念。TeleAI-t1-preview首先对这个概念进行了介绍和解读,然后给出解题思路和最终答案。
我国古代数学发展历史悠久,流传众多经典著作,但因其文言文表述,通常让人望而却步。不少大模型也会陷入沉思,无法作答。将《九章算术》中的一道题目给到 TeleAI-t1-preview后,它先针对文言文进行了理解和简化,转换成现代汉语,随之给出数学推导和答案。

在过程中,TeleAI-t1-preview还将形象思维与抽象思维结合,对所涉及的场景进行具象化思考,辅助理解题目。同时,它还严谨地进行了古今单位换算,顺利过关。
如果说数学竞赛和考研题目还能符合人的正常思维方式,那么面对极度“烧脑”的策略推理问题时,以往的大模型往往会答非所问,被绕到“陷阱”中去。TeleAI-t1-preview能够迅速理解游戏规则并完成破题。

TeleAI-t1-preview在解题过程中,列出了对游戏规则的理解、场景道具分析、优劣势分析,并给出解题策略、验证有效性。不仅如此,它还考虑到了可能出现的特殊情况。
针对 TeleAI-t1-preview训练的不同阶段,TeleAI引入了创新的训练策略,从而保障思考推理过程准确有效。
数据准备阶段:收集、构建了一个以数学为核心、多学科为补充的高质量推理数据集,确保模型能够适应不同类型的推理任务。
Judge Model(评估模型):训练了一个Judge Model专门用于分析和评估模型长思考链路的正确性,为模型的反思和错误修正提供指导。
SFT(监督微调)阶段:用MCTS(蒙特卡洛树搜索)构造高质量长推理数据,结合每个步骤的准确率和解决方案长度来选择最优的完整路径,在保证推理答案准确性的同时有效拉长思考链路以获得更细粒度的推理过程。同时使用 Judge Model对推理过程中正确率较低的路径进行分析,引导模型对错误的推理步骤进行反思和修正,从而构造出高质量的思维链数据进行SFT训练。
强化学习阶段:额外构造了Rule-based Reward Model(基于规则的奖励模型),以提供足够准确的奖励信号,通过在线强化学习算法进一步提升模型的逻辑推理能力。
直观呈现的思维链将帮助人们更清晰地追踪推理过程,方便验证推理正确性,从而使模型的可解释性和透明度大大提升。
TeleAI将持续在推理模型领域研究探索,让人工智能基于人类的“已知”,推导出期盼得到的“未知”。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。










