新火种
2023-09-08
新火种
2023-09-08 


深度学习模型:GAN
GAN(Generative Adversarial Network,生成对抗网络)是一种深度学习的模型,它由两个神经网络组成,分别称为生成器(Generator)和判别器(Discriminator)。生成器的目的是从一个随机噪声向量生成一些新的数据,例如图像、文本、音频等。判别器的目的是判断输入的数据是真实的还是生成器生成的。生成器和判别器在一个零和博弈(Zero-sum Game)的框架下进行竞争,生成器试图欺骗判别器,使其无法区分真假数据,判别器试图识别出生成器生成的数据,并给出一个接近于0或1的概率值。通过不断地更新两个网络的参数,最终使得生成器能够生成足够逼真的数据,而判别器无法区分真假数据。
GAN的结构如下图所示:
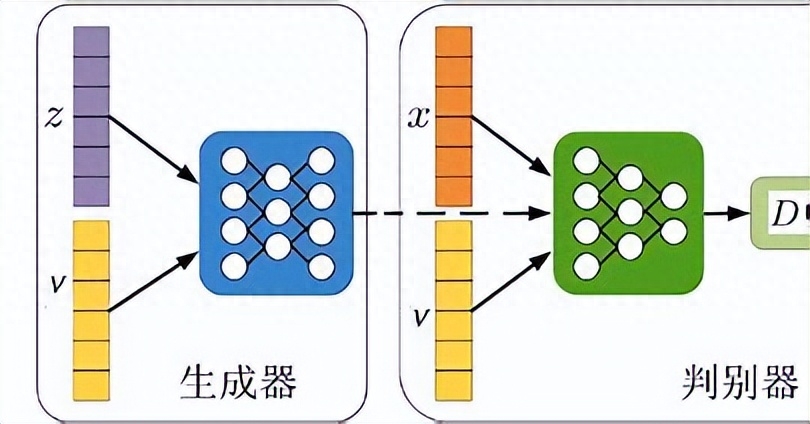
其中,z是一个随机噪声向量,G(z)是生成器输出的数据,x是真实数据,D(x)是判别器对真实数据的概率输出,D(G(z))是判别器对生成数据的概率输出。GAN的训练过程是通过最小化以下损失函数来进行的:
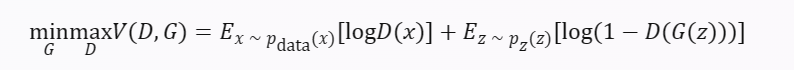
其中,E表示期望值,pdata(x)表示真实数据的分布,pz(z)表示噪声向量的分布。这个损失函数可以理解为判别器和生成器之间的交叉熵(Cross Entropy),判别器希望最大化这个损失函数,即让D(x)尽可能接近于1,而让D(G(z))尽可能接近于0;生成器希望最小化这个损失函数,即让D(G(z))尽可能接近于1。
GAN有很多优点,例如可以从数据中自动学习特征,而不需要人工设计或标注;可以用于生成新的数据,例如图像、文本、音频等;可以用于增强已有的数据,例如图像超分辨率、图像风格迁移、图像修复等。
GAN也有一些缺点,例如训练过程不稳定,容易出现模式崩溃(Mode Collapse)或梯度消失(Vanishing Gradient)等问题;难以评估生成数据的质量和多样性;难以控制生成数据的属性和特征等。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章