

 新火种
2025-01-16
新火种
2025-01-16 


阿里云通义开源最强过程奖励PRM模型7B尺寸比GPT-4o更能发现推理错误
1月16日消息,今日,阿里云通义开源全新的数学推理过程奖励模型Qwen2.5-Math-PRM,72B及7B尺寸模型性能均大幅超越同类开源过程奖励模型。
据悉,在识别推理错误步骤能力上,Qwen2.5-Math-PRM以7B的小尺寸超越了GPT-4o。同时,通义团队还开源了首个步骤级的评估标准 ProcessBench,此项评估标准填补了大模型推理过程错误评估的空白。
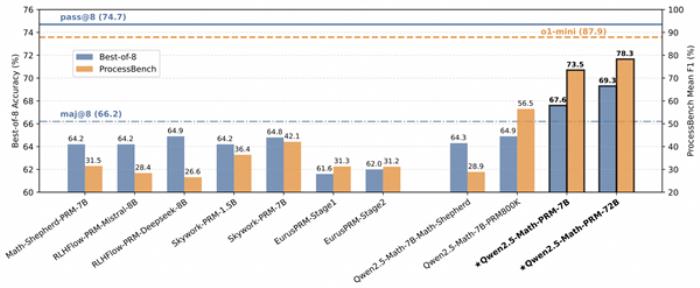
据了解,为更好衡量模型识别数学推理中错误步骤的能力,通义团队提出的全新评估标准ProcessBench。该基准由3400个数学问题测试案例组成,其中还包含奥赛难度的题目,每个案例都有人类专家标注的逐步推理过程,可综合全面评估模型识别错误步骤能力。这一评估标准也已开源。
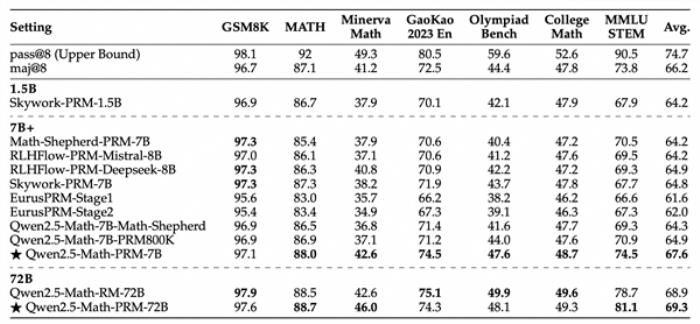
此外,在ProcessBench上对错误步骤的识别能力的评估中,72B及7B尺寸的Qwen2.5-Math-PRM均显示出显著的优势,7B版本的PRM模型不但超越同尺寸开源PRM模型,甚至超越了闭源GPT-4o-0806。这证明了过程奖励模型(PRM)能够显著提高推理的可靠性,为未来开发推理过程监督技术开辟了新的途径。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。









