


「Meta版ChatGPT」背后的技术:想让基础LLM更好地处理长上下文,只需持续预训练
在处理长上下文方面,LLaMA 一直力有不足,而通过持续预训练和其它一些方法改进,Meta 的这项研究成功让 LLM 具备了有效理解上下文的能力。大型语言模型(LLM)所使用的数据量和计算量都是前所未见的,这也使其有望从根本上改变我们与数字世界的交互方式。随着 LLM 被不断快速部署到生产环境中并不
在处理长上下文方面,LLaMA 一直力有不足,而通过持续预训练和其它一些方法改进,Meta 的这项研究成功让 LLM 具备了有效理解上下文的能力。大型语言模型(LLM)所使用的数据量和计算量都是前所未见的,这也使其有望从根本上改变我们与数字世界的交互方式。随着 LLM 被不断快速部署到生产环境中并不
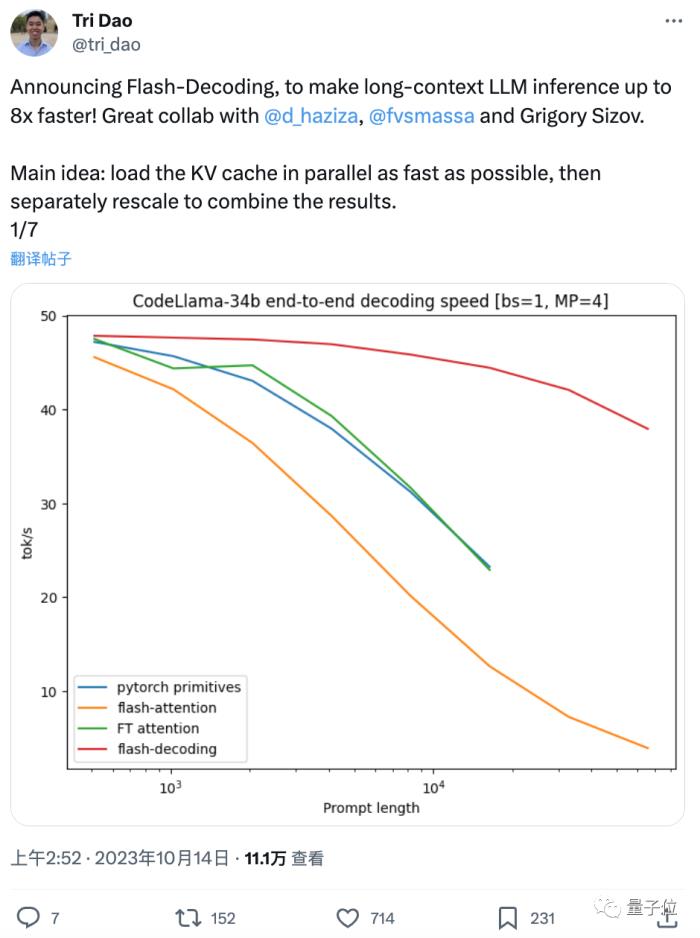
这两天,FlashAttention团队推出了新作:一种给Transformer架构大模型推理加速的新方法,最高可提速8倍。该方法尤其造福于长上下文LLM,在64k长度的CodeLlama-34B上通过了验证。甚至得到了PyTorch官方认可:如果你之前有所关注,就会记得用FlashAttentio
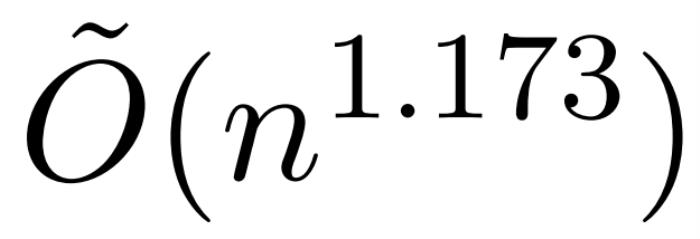
本文介绍了一项近似注意力机制新研究,耶鲁大学、谷歌研究院等机构提出了 HyperAttention,使 ChatGLM2 在 32k 上下文长度上的推理时间快了 50%。Transformer 已经成功应用于自然语言处理、计算机视觉和时间序列预测等领域的各种学习任务。

「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman「2025 年,每个公司都将拥有 AI 软件工程师 Agent,它们会编写大量代码。」










