

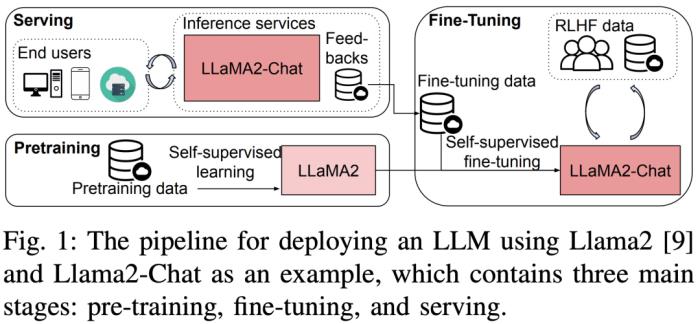
Llama2推理RTX3090胜过4090,延迟吞吐量占优,但被A800远远甩开
这是为数不多深入比较使用消费级 GPU(RTX 3090、4090)和服务器显卡(A800)进行大模型预训练、微调和推理的论文。大型语言模型 (LLM) 在学界和业界都取得了巨大的进展。但训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,
这是为数不多深入比较使用消费级 GPU(RTX 3090、4090)和服务器显卡(A800)进行大模型预训练、微调和推理的论文。大型语言模型 (LLM) 在学界和业界都取得了巨大的进展。但训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,
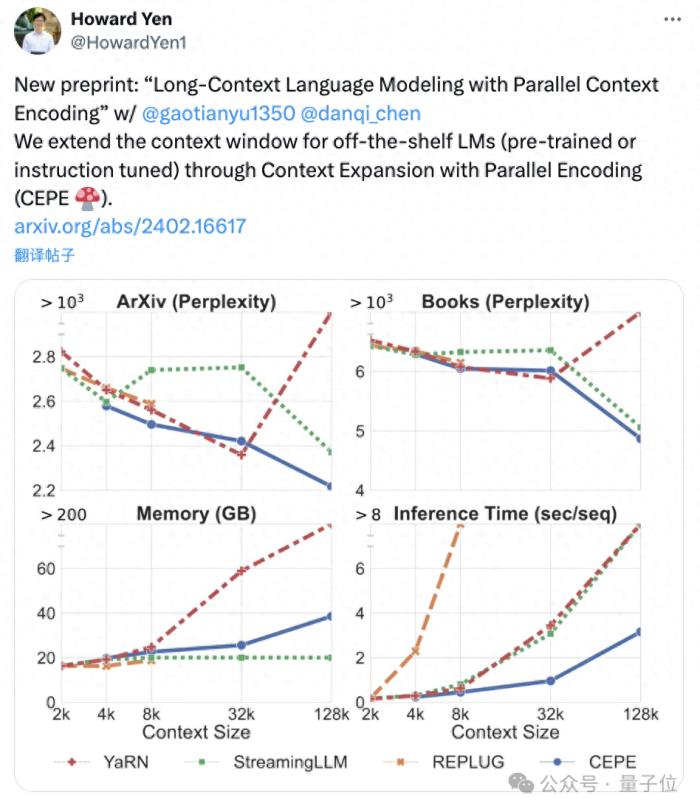
陈丹琦团队刚刚发布了一种新的LLM上下文窗口扩展方法:它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。

强化学习(RL)对大模型复杂推理能力提升有关键作用,但其复杂的计算流程对训练和部署也带来了巨大挑战。近日,字节跳动豆包大模型团队与香港大学联合提出 HybridFlow。这是一个灵活高效的 RL/RLHF 框架,可显著提升训练吞吐量,降低开发和维护复杂度

CPU+GPU,模型KV缓存压力被缓解了。来自CMU、华盛顿大学、Meta AI的研究人员提出MagicPIG,通过在CPU上使用LSH(局部敏感哈希)采样技术,有效克服了GPU内存容量限制的问题。与仅使用GPU的注意力机制相比,MagicPIG在各种情况下提高了1.76~4.99倍的解码吞吐量,并










