


OPPO明日将发千亿参数安第斯大模型:对话能力获提升
11月15日消息,据媒体报道,OPPO将于明日发布个人专属、对话增强的安第斯大模型(AndesGPT),这是基于千亿参数的对话增强语言模型。OPPO明日将会在上海世博中心举行OPPO开发者大会,正式发布ColorOS 14,与之同台登场的还有AndesGPT,
11月15日消息,据媒体报道,OPPO将于明日发布个人专属、对话增强的安第斯大模型(AndesGPT),这是基于千亿参数的对话增强语言模型。OPPO明日将会在上海世博中心举行OPPO开发者大会,正式发布ColorOS 14,与之同台登场的还有AndesGPT,

刘强东AI数字人“采销东哥”上播第一天起,就有许多质疑。
要点:通义千问开源全家桶推出多款模型,包括18亿、70亿、140亿、720亿参数的大型模型,满足不同需求。Qwen-72B是其中一款720亿参数的模型,性能强劲,在多个权威基准测评中超越其他开源和商用模型,填补了中国大模型市场的空白。通义千问的开源模型具有全尺寸、全模态的特点,包括小型模型Qwen-

GPT【新智元导读】曾经怀疑LLM能干什么用的苹果高管,如今急了。苹果一天烧几百万美元,只为把Apple GPT塞进明年发布的iPhone里。苹果急了?据The Information报道,为了加速开发LLM,苹果现在不仅大幅增加了研究经费——每天烧掉数百万美元,还从谷歌挖来了许多工程师。对此,苹果

刚刚,X 上的一则推文受到了大家的广泛讨论,浏览量迅速增长。原来,OpenAI 发布的 GPT-4o-mini 居然是一个仅有 8B 参数的模型?
马斯克说到做到开源Grok-1,开源社区一片狂喜。但基于Grok-1做改动or商用,都还有点难题:Grok-1使用Rust+JAX构建,对于习惯Python+PyTorch+HuggingFace等主流软件生态的用户上手门槛高。
11 月 9 日消息,阿里巴巴集团 CEO 吴泳铭今日在 2023 年世界互联网大会乌镇峰会上透露,阿里巴巴即将开源 720 亿参数大模型,这将是国内参数规模最大的开源大模型。查询获悉,阿里巴巴目前已经开源通义千问 140 亿参数模型 Qwen-14B 和 70 亿参数模型 Qwen-7B
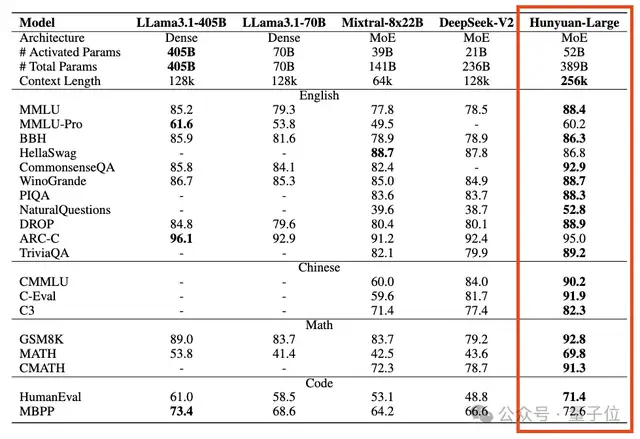
腾讯拿出看家本领,来挤开源赛道,突然发布了市面上最大的开源MoE模型。Hunyuan-Large,3890亿总参数,520亿激活参数。跑分超过Llama 3.1 405B等开源旗舰,上下文长度支持也高出一档来到256k。

1月30日报道,11月27日,算力龙头企业浪潮信息发布了完全开源且可免费商用的源2.0基础大模型,包含1026亿、518亿、21亿不同参数规模,这也是国内首个千亿参数、全面开源的大模型。浪潮信息源2.0大模型在数理逻辑、数学计算、代码生成能力方面大幅提升,

据中新网,5月28日,在北京举行的中关村论坛平行论坛“人工智能大模型发展论坛”上,中国科学技术信息研究所所长赵志耘发布了《中国人工智能大模型地图研究报告》。赵志耘解读称,中国大模型的各种技术路线都在并










