


GPT-4不知道自己错了!LLM新缺陷曝光,自我纠正成功率仅1%,LeCun马库斯惊呼越改越错
GPT-4根本不知道自己犯错?最新研究发现,LLM在推理任务中,自我纠正后根本无法挽救性能变差,引AI大佬LeCun马库斯围观。原文来源:新智元由无界AI生成大模型又被爆出重大缺陷,引得LeCun和马库斯两位大佬同时转发关注!在推理实验中,声称可以提高准确性的模型自我纠正,把正确率从16%
GPT-4根本不知道自己犯错?最新研究发现,LLM在推理任务中,自我纠正后根本无法挽救性能变差,引AI大佬LeCun马库斯围观。原文来源:新智元由无界AI生成大模型又被爆出重大缺陷,引得LeCun和马库斯两位大佬同时转发关注!在推理实验中,声称可以提高准确性的模型自我纠正,把正确率从16%

对于 2023 年的计算机视觉领域来说,「分割一切」(Segment Anything Model)是备受关注的一项研究进展。Meta四月份发布的「分割一切模型(SAM)」效果,它能很好地自动分割图像中的所有内容Segment Anything 的关键特征

原文来源:新智元由无界AI生成最近,包括LeCun在内的一众大佬又开始针对LLM开炮了。最新的突破口是,LLM完全没有推理能力!在LeCun看来,推理能力的缺陷几乎是LLM的「死穴」,无论未来采用多强大的算力,多广阔和优质的数据集训练LLM,都无法解决这个问题。而LeCun抛出的观点,引发
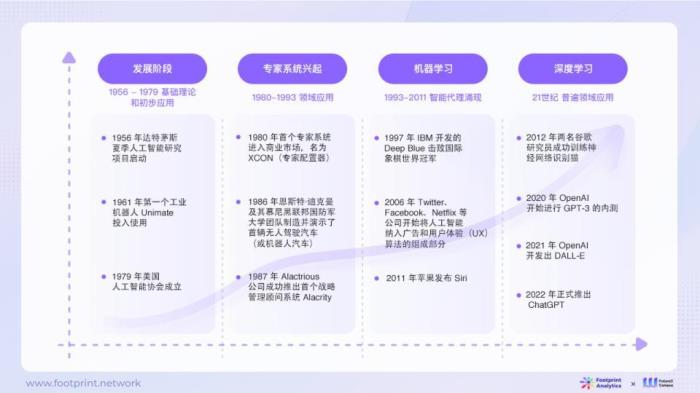
GPT的横空出世将全球的目光吸引至大语言模型,各行各业都尝试着利用这个“黑科技”提高工作效率,加速行业发展。Future3 Campus携手Footprint Analytics共同深入研究AI与Web3结合的无限可能,联合发布了《AI与Web3数据行业融合现状、竞争格局与未来机遇探析》研报。该研报

原文来源:机器之心由无界 AI生成大型语言模型 (LLMs) 在各种自然语言任务中展现出了卓越的性能,但是由于训练和推理大参数量模型需要大量的计算资源,导致高昂的成本,将大语言模型应用在专业领域中仍存在诸多现实问题。因此,北理团队先从轻量级别模型入手,最大程度发挥数据和模型的优势,立足更好

来源:硅兔赛跑作者:林檎 编辑:蔓蔓周由无界 AI生成编者按:本文探讨了大语言模型(LLM)研究中的十大挑战,作者是Chip Huyen,她毕业于斯坦福大学,现为Claypot AI —— 一个实时机器学习平台的创始人,此前在英伟达、Snorkel AI、Netflix、Primer公司

原文来源:新智元由无界 AI生成幻觉,老朋友了。自打LLM进入我们的视野,幻觉问题就一直是一道坎,困扰着无数开发人员。当然,有关大语言模型幻觉的问题已经有了无数研究。最近,来自哈工大和华为的团队发表了一篇50页的大综述,对有关LLM幻觉问题的最新进展来了一个全面而深入的概述。这篇综述从LL

原文来源:硅星人由无界 AI 生成你有多久没听到一家创业公司说自己要拯救互联网了。今天的创业者似乎要么闷声赚钱,要么在讨论用AI拯救(或者毁灭)全人类。我们每天都生活其中的互联网,似乎早就没人关心他的死活了。而在Chri看起来,它就要死了。我在圣何塞明媚的阳光下听他这么对我说的时候,感觉

来源:深思SenseAI由无界 AI生成汽车是工业时代机械电子的集大成者。OpenAI 布局自动驾驶领域,有了具备通用理解能力的多模态大规模语言模型(MLLM)加成,汽车会是我们通往 AGI 道路的重要 Agent。自动驾驶对安全性和可靠性依赖度高,MLLMs 可以在自动驾驶堆栈的各个环

由无界 AI生成当前,让大语言模型拥有更强的上下文处理能力是业界非常看重的热点主题之一。本文中,加州大学伯克利分校的研究者将 LLM 与操作系统巧妙地联系在了一起,在扩展上下文长度领域带来了新的进展。近年来,大语言模型(LLM)及其底层的 transformer 架构已经成为了对话式 AI










