新火种
2024-11-18
新火种
2024-11-18 


AMD的GPU跑AI模型终于Yes了?PK英伟达H100不带怕的
都很贵。
AMD vs 英伟达绝对算是一个长盛不衰的话题 —— 从玩游戏用哪家强到如今训练 AI 哪个更高效?原因也很简单:它们的 GPU 产品存在直接竞争关系。
当然,答案通常都偏向于英伟达,尤其是在 AI 算力方面,正如前些天李沐在上海交大演讲时谈到的那样:「算力这块,你可以用别的芯片,但是这些芯片用来做推理还 OK,做训练的话还要等几年的样子,英伟达还是处在一个垄断的地位。」
但基于实证的对比研究却往往又会给出不一样的答案,比如在同一个演讲中,李沐还提到了这两家 GPU 的内存情况,对此他表示:「在这一块,虽然英伟达是领先者,但其实英伟达是不如 AMD 的,甚至不如 Google 的 TPU。」
实际上,不少业内人士都表达过对 AMD 占据更大市场份额的信心,比如 Transformer 作者及生成式 AI 初创公司 Cohere 创始人之一艾丹・戈麦斯(Aidan Gomez)前些天说:「我认为 AMD 和 Tranium 这些平台很快也将做好真正进入主流市场的准备。」
近日,专注计算硬件的科技媒体 The Information 发布了一份对比评测报告,声称是首个直接对比 AMD 和英伟达 AI 集群的基准评测。该报告的数据来自 MLCommons,这是一个由供应商主导的评测机构。
他们构建了一套 MLPerf AI 训练和推理基准。AMD Instinct 「Antares」 MI300X GPU 以及英伟达的「Hopper」H100 和 H200 和「Blackwell」B200 GPU 都得到了评估。The Information 对比了这些评估数据。
结果表明:在 AI 推理基准上,MI300X GPU 绝对能比肩 H100 GPU,而根据 The Information 对 GPU 成本及系统总成本的估计,说 MI300X GPU 能媲美 H100 和 H200 GPU 也不为过。但是,也需要说明这些测试存在局限:仅使用了一种模型,即来自 Meta 的 Llama 2 70B。希望未来能看到这些测试中使用更多不同的 AI 模型。
对 MI300X 及 AMD 未来的 GPU 来说,这个结果很是不错。
但到今年年底时,考虑到英伟达 Blackwell B100 和 B200 GPU 的预期价格,似乎英伟达将与 AMD MI300X 加速器开始比拼性价比。另外,也许 AMD 会在今年晚些时候推出 MI325X GPU。
重点关注推理
AMD 的数据直到上周才发布。业内有传言说 AMD 签了一些大订单,会把 MI300X 出售给超大规模计算公司和云构建商,以支撑他们的推理工作负载。无怪乎 AMD 直到上周才发布 MLPerf Inference v4.1 测试结果。
对 MLPerf 推理结果的分析表明,在使用 Llama 2 70B 模型执行推理任务时,MI300X 在性能和成本上确实能与 H100 比肩。但和 H200 相比就差点了,毕竟 H200 有更大的 HBM 内存(141GB)和更高的带宽。如果 Blackwell 的定价符合预期,那么今年晚些时候推出的 MI325 为了具备竞争力,就必须得拥有更大的内存、更高的带宽和更激进的价格才行。
下面是最新发布的 MLPerf 基准评测结果:
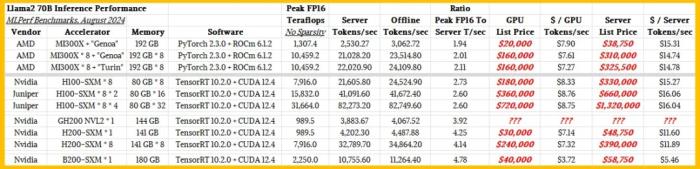
英伟达的 MLPerf 基准评测结果来自英伟达自身,其中也包括使用 Llama 2 70B 模型在单台 Blackwell B200 SXM 上的结果,详情可访问这篇博客:https://blogs.nvidia.com/blog/mlperf-inference-benchmark-blackwell/
The information 提取了所有英伟达的结果,并新增了 Juniper Networks 在包含 2 个和 4 个节点的 HGX H100 集群上得到的结果(总共 8 和 16 台 H100)。
AMD 在配备一对当前的「Genoa」Epyc 9004 系列处理器和八台 Antares MI300X GPU 的服务器节点中测试了标准通用基板(UBB),还测试了一台将 Genoa CPU 换成即将推出的「Turin」Epyc 9005 系列 CPU 的机器,该系列 CPU 预计将在下个月左右推出。

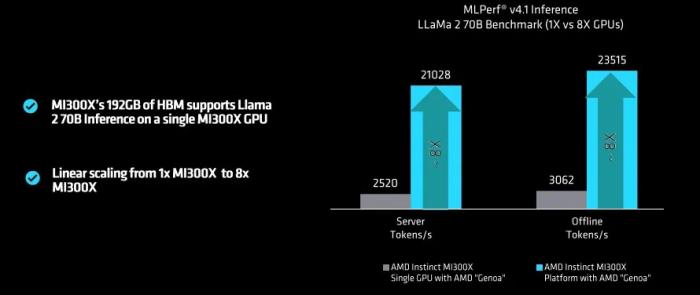
AMD 还向 The Next Platform 提供了一张图表,其中展示了在 Genoa 盒子上测试一台 MI300X GPU 的性能,这可以显示节点内 GPU 的扩展性能:
让我们先看性能,然后再看性价比。
对于性能,我们想知道,在执行 Llama 2 推理时,AMD 和英伟达设备所具备的潜在峰值浮点性能有多少会被实际用于生成 token。但并没有这方面的具体数据,因为 GPU 利用率和内存利用率不在基准测试中。不过我们可以根据已有数据进行推断。
AMD GPU 配置了 PyTorch 2.3.0 框架和 AMD 的 ROCm 6.1.2 软件库和 runtimes,它类似于英伟达的 CUDA 堆栈。在 MI300X 的张量核心上的峰值 FP16 性能为 1307.4 TFlops,但这是在服务器模式下运行的(也就是使用在现实世界中看到的一种随机查询),可知在运行 Llama 2 70B 模型时,单台 MI300X 每秒生成 2530.7 个 token。因此,Llama 2 性能与假设峰值 Flops 之比为 1.94。当扩展到 8 台 MI300X 设备并换用更高速的 CPU,则这一比值会略微升至 2.01 到 2.11。
我们知道,H100 GPU 的 HBM 内存仅有 80GB,启动带宽也较低,这是因为缺少 HBM3 和 HBM3E 内存导致的内存配置不足。MI300X 也是类似。大家都在拉低 GPU 的内存配置,这样不仅是为了多卖些设备,而且也因为在 GPU 芯片附近堆叠 HBM 的难度很大,并且还有封装制造工艺的问题。
再看看英伟达测试的 H100 系统,每秒服务器 token 与峰值 FP16 Flops 的比值是 2.6 或 2.73,这比 AMD 的更好,这可能要归结于软件调整。针对 H100,CUDA 堆栈和 TensorRT 推理引擎进行了大量调整,现在你明白为什么 AMD 如此渴望收购人工智能咨询公司 Silo AI 了吧?这笔交易几周前刚刚完成。
由于切换到了 HBM3E,H200 的 HBM 内存将大幅提升至 141 GB,带宽也将从 3.35 TB/s 提升至 4.8 TB/s。于是这个比值将增至 4.25,而英伟达自己的基准测试表明,只需在完全相同的 Hopper GH100 GPU 上添加内存容量和带宽,AI 工作负载就能提升 1.6 至 1.9 倍。
MI300X 应该具有什么样的内存容量和带宽才能平衡其在推理(可能还有训练)工作负载方面的浮点性能呢?这一点很难估计。但 The Information 给出了一个直觉估计:MI325X 将具有 6 TB/s 的带宽(MI300 为 5.3 TB/s)和 288 GB 的 HBM3E( HBM3 为 192 GB)—— 这是朝着正确方向迈出的一大步。另外,MI325X 的 FP16 浮点性能似乎还是 1.31 Pflops。
不过明年的 MI350 的浮点性能可能会大幅提升,据信其会有新迭代的 CDNA 架构:CDNA 4。其不同于 Antares MI300A、MI300X 和 MI325X 中使用的 CDNA 3 架构。MI350 将转向台积电的 3 纳米工艺,并增加 FP6 和 FP4 数据类型。据推测,将有一个全 GPU 的 MI350X 版本,也许还有一个带有 Turin CPU 核心的 MI350A 版本。
你可能倾向于相信 AMD MI300X 和英伟达 H100 之间的性能差异是因为:一致性互连将 GPU 绑定到其各自 UBB 和 HGX 板上的共享内存复合体中。AMD 机器上的是 Infinity Fabric,而英伟达机器上的是 NVSwitch。Infinity Fabric 的每台 GPU 的双向带宽为 128 GB/s,而 NVLink 4 端口和 NVSwitch 3 交换机的带宽为 900 GB/s,因此英伟达机器在内存一致性节点结构上的带宽高 7 倍。
这可能是 Llama 2 工作负载性能差异的一部分原因,但 The Information 认为不是。原因如下。
单台 MI300X 的峰值性能为 1.31 Pflops,比 H100 或 H200 的 989.5 Tflops(FP16 精度)高出 32.1%,且没有稀疏矩阵重新调整,吞吐量翻倍。MI300X 的内存是 H100 的 2.4 倍,但 Llama 2 推理工作性能仅比 H100 多 7%,并且推理负载仅为 H200 的 60%。根据英伟达进行的测试,相比于配备 180 GB 内存的 Blackwell B200,该设备的工作性能仅为其 23.5%。
据信 B200 的内存也会受限,因此根据 6 月份发布的英伟达路线图,B200 和 B100(可能)将在 2025 年进行内存升级,容量可能会提升到 272 GB 左右。H200 的内存升级会领先于 MI300X,后者的升级将在今年晚些时候体现在 MI32X 上,并会在内存方面领先 B200 Blackwell Ultra 六到九个月。
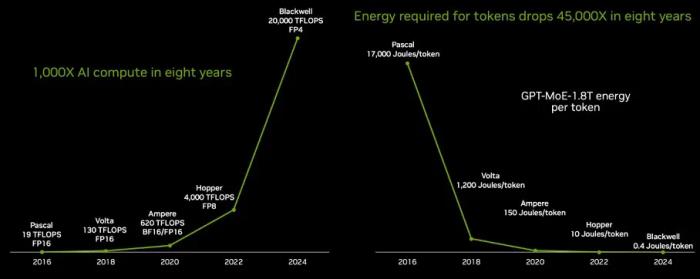
The Information 表示:「如果我们要买 GPU,我们会等 Hopper Ultra (H200)、Blackwell Ultra (B200+) 和 Antares Ultra (MI325X)。拥有更多 HBM 的数据中心 GPU 更划算。」
当然,你也可以等,用你现有的 GPU 参加这场生成式 AI 大战。
当然,上面的数据围绕着推理,至于 AI 训练方面的数据,AMD 可能会在今年秋季发布。
实际应用的性价比
MI300X 与英伟达的 Hopper 和 Blackwell 的性价比如何呢?
今年早些时候,英伟达联合创始人兼 CEO 黄仁勋在 Blackwell 发布后表示:这些设备的价格将在 3.5 至 4 万美元之间。Hopper GPU 的价格可能为 2.25 万美元,具体取决于配置。黄仁勋在 2023 年时曾表示,一套配置完成的 HGX H100 系统板的价格售价 20 万美元。至于 H200,如果单独购买,价格应该是 3 万美元。MI300X 的售价大概是 2 万美元,但这基本基于猜测。具体还要看消费者和市场情况。
当然,大量购买应该还有折扣,正如黄仁勋喜欢说的那样:「买得越多,省得越多。」(The More You Buy, The More You Save)
粗略估计,将这些 GPU 变成服务器(两台 CPU、大量主内存、网卡和一些闪存)的成本约为 15 万美元,并且可以插入英伟达的 HGX 板或 AMD 的 UBB 板来构建八路机器。考虑到之前计算的单台 GPU 的性能,于是这里便以这一成本的八分之一进行计算。
综合这些成本,可以看到 MI300X 与 H100 一样非常烧钱。
我们已经知道,对于 Llama 2 70B 推理任务,H100 系统中平均每台 GPU 每秒可输出 2700 个 token,这比 MI300X 好 7%。H200 的内存是 141 GB,是原来的两倍多,而其推理性能提升了 56%,但 GPU 的价格仅上涨了 33%,因此其 GPU 和系统层面的性价比都得到了提升。
如果 B200 的价格如黄仁勋所说的那样为 4 万美元,那么在 Llama 2 70B 测试中,其在 GPU 层面上每单位推理的成本将降低近一半,在系统层面上则会略多于一半。
考虑到 Blackwell 的短缺以及希望在给定空间和给定热范围内容纳更多 AI 计算的需求,因此也可以推断英伟达可能为每台 B200 GPU 定价 5 万美元 —— 很多人都这样预计。
当然,具体如何,还要看今年晚些时候 AMD MI325 的定价以及产能。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章