新火种
2024-11-15
新火种
2024-11-15 


腾讯混元又来开源,一出手就是最大MoE大模型
随着人工智能技术的快速发展,大型语言模型(LLMs)在自然语言处理、计算机视觉和科学任务等领域取得了显著进展。然而,随着模型规模的扩大,如何在保持高性能的同时优化资源消耗成为关键挑战。为了应对这一挑战,腾讯混元团队率先采用混合专家(MoE)模型架构,最新发布的 Hunyuan-Large(Hunyuan-MoE-A52B)模型,是目前业界已经开源的基于 Transformer 的最大 MoE 模型,拥有 389B 总参数和 52B 激活参数。
本次腾讯混元 - Large 共计开源三款模型:Hunyuan-A52B-Pretrain,Hunyuan-A52B-Instruct 和 Hunyuan-A52B-FP8,可支持企业及开发者精调、部署等不同场景的使用需求,可在 HuggingFace、Github 等技术社区直接下载,免费可商用。通过技术优化,腾讯混元 Large 适配开源框架的精调和部署,具有较强的实用性。腾讯云 TI 平台和高性能应用服务 HAI 也同步开放接入,为模型的精调、API 调用及私有化部署提供一站式服务。

开源官网:
github(开源模型工具包):
huggingface(模型下载):
huggingface demo 地址:
技术报告:
Hunyuan-Large 整体模型效果
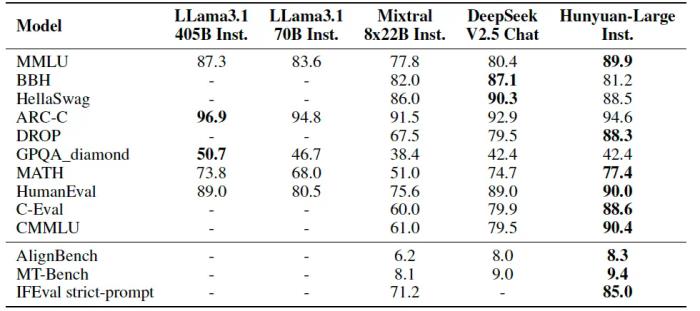
公开测评结果显示,腾讯混元 Large 在 CMMLU、MMLU、CEval、MATH 等多学科综合评测集以及中英文 NLP 任务、代码和数学等 9 大维度全面领先,超过 Llama3.1、Mixtral 等一流的开源大模型。
技术创新点
MoE (Mixture of Experts),也即混合专家模型,MoE 模型的每一层都包含多个并行的同构专家,一次 token 的前向计算只会激活部分专家。MoE 模型的每一层会采用路由算法,决定了 token 会被哪些专家处理。MoE 是一种稀疏的网络结构,具有比激活总参数量同等大小稠密模型更优越的性能,而推理成本却远低于总参数量相同的稠密模型。
得益于 MoE (Mixture of Experts) 结构的优越性,混元 Large 可以在保证模型推理速度的同时,显著提升模型的参数量进而提升模型性能。
1、路由和训练策略
共享专家路由策略
腾讯混元 Large 的专家层中,设置一个共享专家来捕获所有 token 所需的共同知识,还设置了 16 个需要路由的专家,模型将每个 token 路由给其激活得分最高的专家来动态学习特定领域的知识,并通过随机补偿的路由保障训练稳定性。共享专家负责处理共享的通用能力和知识,特殊专家负责处理任务相关的特殊能力,动态激活的专家,利用稀疏的神经网络来高效率的进行推理。
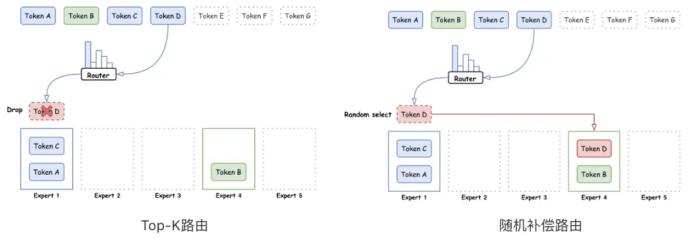
回收路由策略
路由策略,即把 token 分发给 MoE 中各个专家的策略,是 MoE 模型中至关重要的部分。好的路由策略可以有效地激活每个专家的能力,使得每个专家保持相对均衡的负载,同时提升模型的训练稳定性和收敛速度。业界常用的路由策略是 Top-K 路由,也就是将各个 token 按照其和专家的激活得分路由给各个专家。但是这种路由方式难以保障 token 在各个专家间平均分配,而那些超过专家负载的 token 则会被直接扔掉,不参与专家层的计算。这样会导致部分处理 token 较少的专家训练不稳定。
针对这一问题,腾讯混元 Large 在传统 Top-K 路由的基础上进一步提出了随机补偿的路由方式。
专家特定学习率适配策略
在 Hunyuan-A52B 中,共享专家和路由专家在每个迭代里面专家处理的 token 数有很大差异,这将导致每个专家实际的 batchsize 并不相同(共享专家的 batchsize 是其他专家的 16 倍),根据学习率与 Batch size 的缩放原则,为不同(共享 / 特殊)专家适配不同的最佳学习率,以提高模型的训练效率。
高质量的合成数据
大语言模型的成功与高质量的训练数据密不可分。公开网页数据通常质量参差不齐,高质量通常难以获取;在天然文本语料库的基础上,腾讯混元团队在天然文本语料库的基础上,利用混元内部系列大语言模型,构建大量的高质量、多样性、高难度合成数据,并通过模型驱动的自动化方法评价、筛选和持续维护数据质量,形成一条完整数据获取、筛选、优化、质检和合成的自动化数据链路。
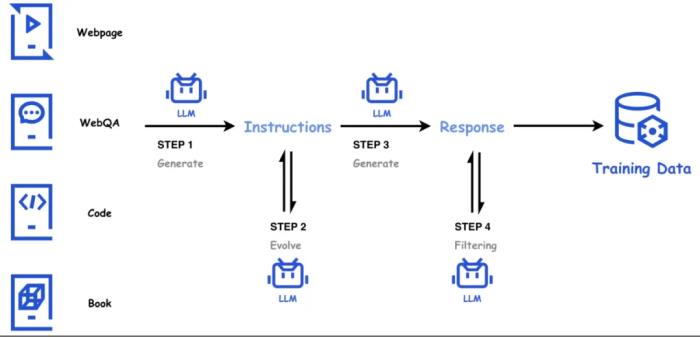
在数学领域,网页数据中很难找到大量优质的思维链 (CoT) 数据。腾讯混元 Large 从网页中挖掘构建大规模题库,并利用它作为种子来合成数学问答,从而保证了多样性;同时我们利用一致性模型和评价模型来维护数据的质量,从而得到大量优质且多样的数学数据。通过加入数学合成数据显著提高了模型的数学能力。
在代码领域中,自然代码很多质量较差,而且包含类似代码解释的代码 - 文本映射的数据很稀缺。因此,腾讯混元 Large 使用大量天然代码库中的代码片段作为种子,合成了大量包含丰富的文本 - 代码映射的高质量代码训练数据,加入后大幅提升了模型的代码生成能力。
针对通用网页中低资源、高教育价值的数据,腾讯混元 Large 使用合成的方式对数据做变换、增广,构建了大量且多样的、不同形式、不同风格、高质量的合成数据,提升了模型通用领域的效果。
2、长文能力优化
采用高效的超长文 Attention 训练和退火策略。通过将长文和正常文本混合训练,逐步多阶段引入自动化构建的海量长文合成数据,每阶段仅需少量长文数据,即可获得较好的模型长文泛化和外推能力。
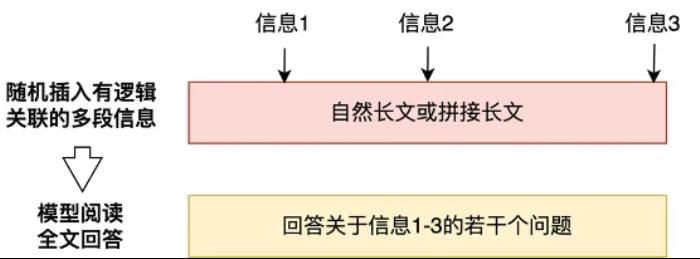
腾讯混元 Large 模型专项提升的长文能力已经应用到腾讯 AI 助手腾讯元宝上,最大支持 256K 上下文,相当于一本《三国演义》或英文原版的《哈利・波特》全集的长度,可以一次性处理上传最多 10 个文档,并能够一次性解析多个微信公众号链接、网址,让腾讯元宝具备独有的深度解析能力。
3、推理加速优化
随着 LLM 处理序列逐渐增长,Key-Value Cache 占用内存过大的问题日益突出,为推理成本和速度带来了挑战。
为了提高推理效率,腾讯混元团队使用 Grouped-Query Attention(GQA)和 Cross-Layer Attention (CLA) 两种策略,对 KV Cache 进行了压缩。同时引入量化技术,进一步提升压缩比。
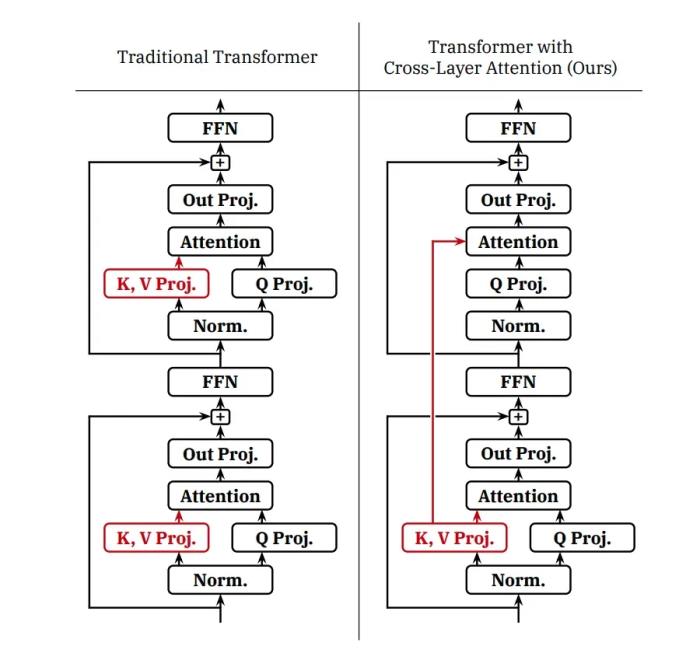
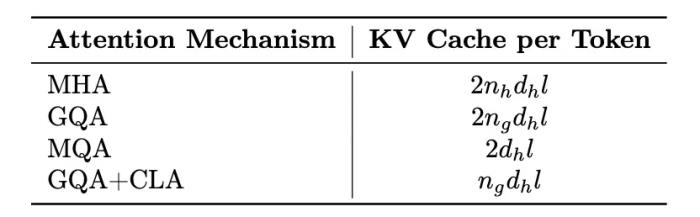
通过 GQA+CLA 的引入,我们将 Hunyuan-A52B 模型的 head 数从 80 压缩到 8,并通过 CLA 每两层共用 KV 激活值,最终将模型的 KV Cache 压缩为 MHA 的 5%,大幅提升推理性能。下面是不同策略的 KV Cache 对比。
4、Postrain 优化
SFT 训练
腾讯混元团队在预训练模型的基础上使用超过百万量级的 SFT 数据进行精调训练,这些精调数据包含了数学、代码、逻辑、文本创作、文本理解、知识问答、角色扮演、工具使用等多种类别。为了保证进入 SFT 训练的数据质量,我们构建了一套完整的基于规则和模型判别的数据质检 Pipeline,用于发现数据中常见的 markdown 格式错误、数据截断、数据重复、数据乱码问题。此外,为了自动化地从大规模指令数据中筛选高质量的 SFT 数据,我们基于 Hunyuan-70B 模型训练了一个 Critique 模型,该模型可以对指令数据进行 4 档打分,一方面可以自动化过滤低质数据,另一方面在自进化迭代过程中可以有效提升被选 response 的质量。
我们使用 32k 长度进行 SFT 训练,另外在训练过程中为了防止过拟合,我们开启了 0.1 的 attention dropout 和 0.2 的 hidden dropout;我们发现相比 Dense 模型,MoE 架构的模型通过开启合理的 dropout,能有效提升下游任务评测的效果。另外为了更高效的利用大规模指令数据,我们对指令数据进行了质量分级,通过从粗到精的分阶段训练,有效提升了模型效果。
RLHF 训练
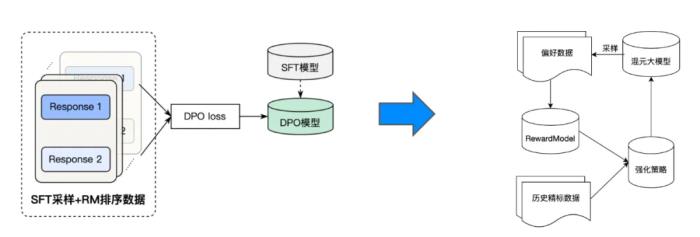
为了使模型能够生成与人类偏好接近的回答,我们进一步使用直接偏好优化(DPO)对齐算法对 SFT 模型进行强化训练。与离线 DPO 算法不同的是,我们在强化学习二阶段采用的是在线强化 pipeline,这一框架里集成了使用固定 pair 数据的离线 DPO 策略,和使用训练过程中更新的策略模型迭代式采样的在线强化策略。具体来说,每一轮模型只使用少量数据进行采样训练,训练完一轮之后的模型会对新的一批数据采样出多个回答,然后利用奖励模型(RM)打分,排序出最好的回答和最差的回答来构建偏好对。
为了进一步增强强化学习阶段的训练稳定性,我们随机筛选了一定比例的SFT数据用于计算 sft loss,由于这部分数据在 SFT 阶段已经学过,DPO 阶段加 sft loss 是为了保持模型的语言能力,且系数较小。此外,为了提升 dpo pair 数据里面的好答案的生成概率,防止 DPO 通过同时降低好坏答案的概率的方式来走捷径,我们也考虑加入好答案的 chosen loss 。通过以上策略的有效结合,我们的模型在 RLHF 训练后各项效果得到了明显的提升。
5、训练和精调
腾讯混元 Large 模型由腾讯全链路自研,其训练和推理均基于腾讯 Angel 机器学习平台。
针对 MoE 模型 All2all 通信效率问题,Angel 训练加速框架(AngelPTM)实现了 Expert 计算和通信层次 overlap 优化、MOE 算子融合优化以及低精度训练优化等,性能是 DeepSpeed 开源框架的 2.6 倍。
腾讯混元 Large 模型配套开源的 Angel 推理加速框架(AngelHCF-vLLM)由腾讯 Angel 机器学习平台和腾讯云智能联合研发。在 vLLM 开源框架的基础上适配了混元 Large 模型,持续通过叠加 NF4 和 FP8 的量化以及并行解码优化,在最大限度保障精度的条件下,节省 50% 以上显存,相比于 BF16 吞吐提升 1 倍以上。除此之外,Angel 推理加速框架也支持 TensorRT-LLM backend,推理性能在当前基础上进一步提升 30%,目前已在腾讯内部广泛使用,也会在近期推出对应的开源版本。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章