

 新火种
2024-09-10
新火种
2024-09-10 


视觉模型底座超越OpenAI,格灵深瞳开启多模态落地的ScalingLaw
大模型时代,有个大家普遍焦虑的问题:如何落地?往哪落地?
聚光灯下最耀眼的OpenAI,最近也先被曝出资金告急,后又寻求新一轮10亿美元新融资。
但在中国,有这么一家公司:
它的多模态大模型不仅在多个权威数据集上的表现超过了OpenAI,更是用一个个落地案例告诉大家,大模型并不仅仅包括大语言模型,视觉大模型和多模态大模型在产业界有更大的想象空间。
这家公司就是格灵深瞳,它曾因“A股AI视觉第一股”的标签为人熟知,如今以新姿态再次刷新外界认知:大模型落地先行者。
银行安防领域,AI算法规模化应用,落地10000+银行网点城市管理领域,交通治理业务在10余个省市开展试点及落地应用商业零售领域,智慧案场解决方案落地全国20余省市近1000个项目体育教育领域,相关产品方案已在全国多个校园试点应用,为100000+名在校师生提供日常教学支持与考试服务……

取得这样的成绩背后,离不开格灵深瞳在大模型技术层面取得的进展:
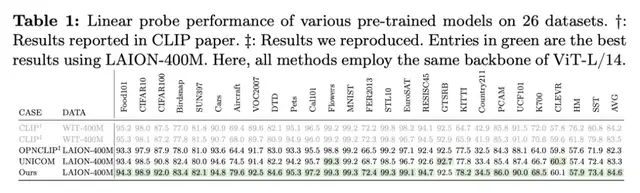
自研视觉大模型Unicom v2,在多业务数据集上平均优于OpenAI的CLIP、Meta的DINOv2和苹果的DFN基于Unicom的深瞳灵感-7B多模态大模型在业界同等规模的VLM模型中居领先地位,优于业界普遍使用的OpenAI CLIP和谷歌 SigLIP其中,Unicom v2相关论文还入选AI顶会ECCV 2024。

虽然现在不加限定的使用“大模型”一词,默认就是指“大型语言模型”,Large Language Model。
但从格灵深瞳的故事中可以看到,视觉大模型、多模态大模型在原本视觉AI的存量市场依然大有可为,而且壁垒依然深厚。
多模态给传统视觉AI带来什么改变?早在2022年,格灵深瞳就开始自研视觉大模型,但当时想要推进落地,还是遇到了瓶颈:
今天已为人熟知的大模型、Transformer、Scaling Law等等,当时还未成为行业共识。彼时的主流是不断优化卷积神经网络,把模型做小、最好能直接在边缘设备运行。
总而言之,当时很难说服客户接受大模型这一前沿但成本高昂的技术。
然而ChatGPT横空出世,彻底改变了这一切。
一方面,它以直观的人机对话方式向公众展示了算力与效果的正相关,人们终于意识到“大量投入算力,才能获得理想中的效果”。
另一方面,硬件也开始主动适配Transformer算法,比如英伟达在Hopper架构GPU中首次引入专用Transformer引擎。
从某种意义上说,ChatGPT是替所有AI公司做好了教育市场的工作。
视觉AI在这一阶段经历了与语言模型类似的,从“模块化”到“一体化”的范式转变。
传统的检测、分割、分类等任务需要针对性设计复杂的特征工程和网络结构,而视觉大模型则以统一的Transformer骨干直接学习图像到特征再到应用输出的端到端映射。
格灵深瞳自研视觉大模型Unicom系列就是这一转变的成果,通过做大数据的规模、做大计算的规模来做强通用能力,让模型以统一的方式对世界进行“理解”和“泛化”。
如果说视觉大模型是让AI“看到了世界”,再结合语言模型则是让AI升级为“看懂了世界”,大大拓宽了应用边界。
以格灵深瞳多年深耕的银行安防行业为例,如何让AI判断摄像头画面中是否有人在打架?
这涉及动作识别、对视角遮挡的推断等等多项难点,在AI 1.0时代需要复杂的规则和阈值设计,再加上难以采集的数据样本,工程量巨大且效果有限。
而加入语言模型后,只需把视频帧连续输入并描述场景,模型就能从语义层面判断这是否属于打斗行为。
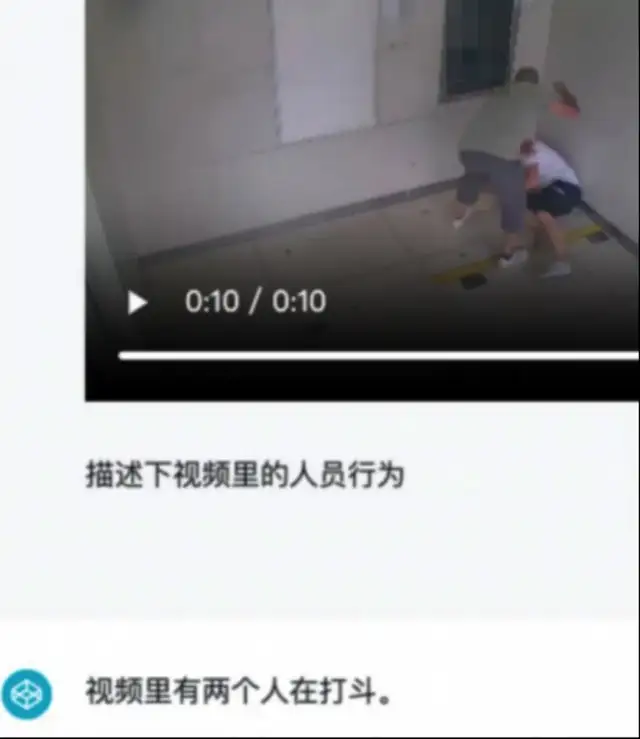
“面对各种长尾、复杂场景,多模态的优势就体现出来了。”格灵深瞳工程研发副总裁周瑞认为,“它让以前难以想象的应用变成了可能。”
同样,在工业质检领域,以前要针对每种缺陷去采集标注数据,代价高昂且泛化性差,更何况一些稀有缺陷数据总量根本就不够。
而通用视觉大模型具备少样本学习、跨场景泛化的能力,再结合上语言模型的多模态生成范式,现在AI只要智能识别到缺陷,同时就能给出文字描述,供现场工作人员参考。
除了在单项任务中,多模态大模型的推理和生成能力,还可以在整个系统中承担任务分配的“路由”作用。
例如格灵深瞳覆盖某银行10000+网点的解决方案,形成总-分-支三层架构:总行利用大模型训练通用模型,分发至各地分行。各省分行结合自身业务特点,定期微调优化模型。支行则直接应用本地分行下发的模型调用服务。
在视频结构化方面,边缘端负责提取人、车、物等目标的实时信息并上传。若无法判别的复杂场景,则发送至中心端请求二次识别。云端利用多模态大模型,从语义层面对场景内容做更全面的理解。
此外,基于多模态大模型强大的数据汇聚与语义理解能力,该行还打通了原本割裂的各类监控数据。目前正着手建设一套覆盖全行的“AI中台”,可灵活调度跨网点、跨系统的数据和算力,快速响应总分支的各种临时需求。
这套架构能随时利用零散的多模态数据对大模型做增量学习提升,让整个银行集团的AI平台像一个不断进化的“中央大脑”。
弱监督学习开启视觉的Scaling Law格灵深瞳视觉大模型的进化之路,开始于做自研的视觉基座模型Unicom。
最初的v1版本参考人脸识别的特征学习方式,把网络直接改成了ViT结构,数据也从人脸扩展到4亿通用图像,精度就超过了当时最好的对比学习模型。
但图像数据不像文本,天然就有高密度的语义信息,无需标注就能通过“预测下一个token”任务进行无监督学习。
如何扩大视觉大模型数据规模,无需标注也能利用好更多图像数据呢?
格灵深瞳团队逐渐探索出一种新颖的弱监督方式:先用一个特征聚类模型,把相似图片自动归类到一起,视为同一类别。然后基于聚类结果,为每张图像分配一个“软标签”,作为训练目标。
这种做法为无标签数据注入了丰富的语义信息。
具体来说,格灵深瞳开发了多标签聚类辨别 (MLCD)方法,在聚类步骤中为每个图像选择多个最近的聚类中心作为辅助类标签,以考虑图像中不同粒度的视觉信号。
与此配合,他们还设计了一种消除多标签分类歧义的损失函数。
不同于常规的多标签损失函数通过缩小类内相似度和类间相似度的相对差距来优化,本文引入了另外两个优化目标:最小化类间相似度和最大化类内相似度,从而可以优雅地分离正类损失和负类损失,减轻决策边界上的歧义。
团队在更大规模的模型和数据集上进行了实验验证,进一步证明了所提出方法的有效性和可扩展性。
Unicom v2正是基于这一思路,将数据规模、参数规模再次扩大,精度再创新高,成功刷新多项记录。
有了Unicom强大的通用视觉理解能力,再结合上语言模型,就组成了深瞳灵感-7B多模态大模型。
该模型不仅在传统的单图问答上表现优异,在多图推理、图文增量学习等前沿任务上也展现出了巨大潜力。
正如格灵深瞳在22年就开始探索ViT架构的视觉大模型落地,现在研究团队也在思考什么是能超越Transformer的下一代架构。
最近,他们尝试用RWKV(Receptance Weighted Key Value)这一基于RNN的序列建模方法替代主流的ViT架构,训练出了视觉语言模型RWKV-CLIP。
RWKV能在线性时间内处理任意长度序列,大幅降低推理时的计算复杂度,有望释放多模态AI能力在更多边缘、终端设备上。
值得一提的是,格灵深瞳还将RWKV-CLIP代码和模型权重开源到GitHub,供业界一起探讨,共同进步。
视觉AI公司做多模态,是一种不同的打法放眼当下,不乏大模型公司试水多模态应用。
但多是简单的技术Demo、带上传图片的聊天机器人、个人AI助手等轻量级形态切入,真正深入产业的尚不多见。
归根到底,把AI算法与特定行业场景深度融合的经验,是难以在短期内获得的。
让多模态大模型技术在更多地方发挥价值,还需要有视觉AI基因、掌握行业场景的公司。
拿着大模型到处找落地场景,和在已深耕多年的场景用大模型做升级改造,是两种完全不同的打法。
纵观历史,互联网作为现代社会的一种基础设施,几十年来积累的大量文本数据,最终成就了大语言模型公司。
接下来,视觉AI时代建设的大量摄像头、积累的图像视频数据也会成就一批多模态大模型公司。
至于为什么是语言模型先一步完成蜕变,格灵深瞳认为是图像数据中的分布更不均匀,比如很容易获得一家上市公司的财报文档,但很难通过开放数据来获取一家公司大量的图像。
到了专业细分场景,如医疗影像、工业缺陷,可获取的训练数据体量更是远不及互联网语料。
但换个角度从应用价值来看,视觉数据直接反映现实世界,与城市治理、工业生产、商业运营等领域的痛点诉求高度契合。
从图像数据中提取出价值更难,也更值得做。
格灵深瞳正是这样一家将技术创新与行业理解相结合的先行者。十多年来,公司始终坚持在智慧金融、城市治理等领域精耕细作,打磨出一整套面向行业的数字化解决方案。
这些方案不仅考虑了算法本身的创新,更融入了大量行业知识和实践经验,形成独特的竞争壁垒。
这种积淀,让格灵深瞳在多模态大模型应用落地中先人一步:既能洞悉行业痛点,设计好落地路径,又能调动资源快速迭代。大到顶层的商业模式设计,小到一线的模型适配、部署,公司上下形成了一套成熟的方法论。
大模型带来的是一个构建行业AI应用的全新技术范式。多模态感知、跨域推理、小样本学习等能力的提升,从根本上拓展了AI的想象空间。
但归根结底,技术只是实现愿景的工具,行业才是应用的土壤。惟有深耕行业,AI才能开花结果。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










