新火种
2024-06-06
新火种
2024-06-06 


AI算力暴增至120TOPS英特尔LunarLake架构解析
随着下一代AI PC硬件核心Lunar Lake的发布,英特尔4年5个制程节点演进也逐步迎来富有革命性的时刻。
面对AI时代指数级的算力需求增长,英特尔Lunar Lake,也就是第二代酷睿Ultra平台的CPU+GPU+NPU算力突破到了120TOPS,这将为基于其打造的AI PC赋予更加强劲、高效的AI性能体验。
在台北电脑展这一PC行业重要时间节点,英特尔率先公布了Lunar Lake平台技术细节,再次革新的架构设计,以及全新的CPU、GPU、NPU特性。
同时,各大OEM厂商也带来了基于Lunar Lake平台的新一代AIPC。那么Lunar Lake究竟能够为第二代酷睿Ultra平台带来怎样的改变?接下来,让我们一起探究全新的英特尔Lunar Lake平台。

·以AI为核心的多元化计算力提升
现如今,AI应用蓬勃发展,并且深入到各个领域。聊天机器人、AI智能助手、文生图、文生视频、文生音乐、降噪、扩图、代码生成、声音模拟等等应用场景为人们所熟知。
生成式AI蓬勃增长,基于AI技术的应用日新月异,多元化大模型的转换与扩散,成为AI终端负载的主流趋势。同时更需要云、端、边缘等多模态AI硬件设备的算力支持。
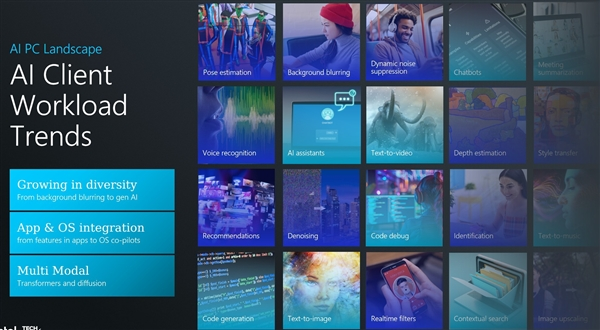
与此同时,对于像PC这样的本地化AI载体,多元化的AI应用对于CPU、GPU、NPU等核心硬件的算力要求与日俱增,单一和传统的硬件发展模式已经无法完全适应AI时代的计算要求。
因此,从Meteor Lake到如今的Lunar Lake,CPU+GPU+NPU构成的多元AI计算引擎,成为当代AI PC核心硬件的架构设计趋势。
也因此,在如何提升三大AI计算引擎算力的同时,利用制程与架构优势塑造更好的能效比,并兼顾传统计算能力的提升,成为了摆在英特尔这些上游芯片企业的最直接问题。
我们看看全新的Lunar Lake是如何做到的?
·高达120TOPS的全核心AI算力暴增
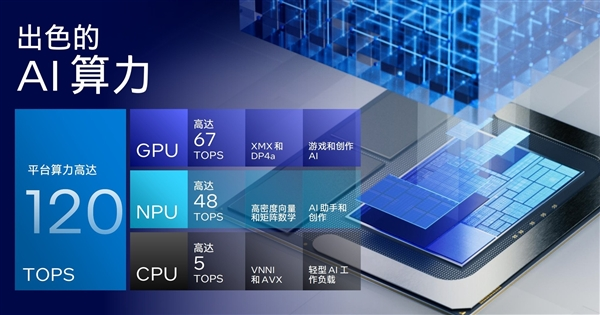
首先需要明确的一点是,Lunar Lake全新的CPU、GPU以及NPU,使得整个平台的AI计算能力达到120TOPS,相较Meteor Lake实现翻倍式提升。

那么这120TOPS算力是如何分配的呢?
首先,Lunar Lake采用的全新的Lion Cove性能核(P-Core)与Skymont能效核(E-Core)设计,支持VNNI以及AVX AI指令集,峰值AI算力为5TOPS。
别看数字比较低,但是CPU在AI应用中往往只负责一些轻度的嵌入式AI计算任务,因此5TOPS算力足以应对这些类型AI的计算需求。
其次,全新的Xe2 GPU架构带来了67TOPS的峰值AI算力,这主要得益于新架构的XMX矩阵引擎吞吐量的进一步提升,从而使得新的锐炫GPU拥有了更强的浮点运算能力,提升了BF16、INT8等常见AI数据类型的算力。
其三,全新的NPU 4架构,带来了2倍的能效提升以及48TOPS的峰值算力。相比Meteor Lake NPU 3架构的11.5TOPS算力,可以说是提升巨大。
因此,三大硬件核心算力加在一起,就构成了Lunar Lake整体120TOPS的AI计算能力。
·CPU、GPU、NPU三大核心性能更强、能效比更高
了解了Lunar Lake最为核心的特性之后,我们从架构入手,看看Lunar Lake在设计上有哪些变化?
从整体来看,Lunar Lake被英特尔定位仪下一代AI PC的旗舰级SoC。它具备四大特点:
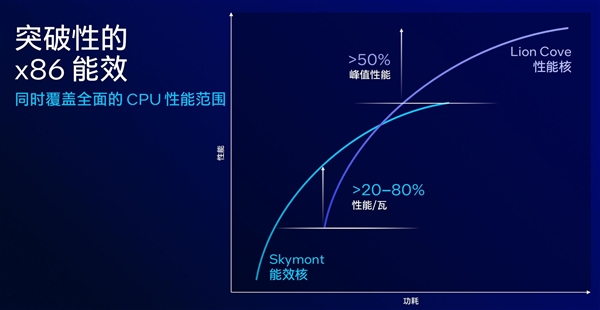
其一,降低40%能耗,带来了极富突破性的x86能效表现;
其二,达到Meteor Lake相同性能等级时,能耗只有前者的一半,从而带来了卓越的核心性能保险;
其三,全新的Xe2图形架构带来了1.5倍的图形性能提升;
其四,120TOPS全平台AI算力带来了无与伦比的AI计算能力。

在这样的前提下,我们来看看Lunar Lake的芯片设计。如下图所示:

与Meteor Lake的计算模块、图形模块、SoC模块、IO模块的架构设计相比,Lunar Lake进行了整合并直接集成了内存。
可以看到,Lunar Lake在基板上直接集成了LPDDR5x内存颗粒,最高支持32GB双通道。处理器芯片部分由计算模块(Compute tile)和平台控制模块(Platform Controller tile)构成。

Lunar Lake的计算模块包含了性能核心、能效核心、GPU、媒体和显示引擎以及NPU五个区块,这部分如果做深入解读的话会比较难以理解,所以这里我们尽量把一些较为晦涩难懂的技术细节剔除,比如流水线深度、分支预测、矢量等等,只介绍这些技术细节的改变为Lunar Lake奠定了怎样的性能基础。
·全新设计的性能核与能效核带来更好的性能体验
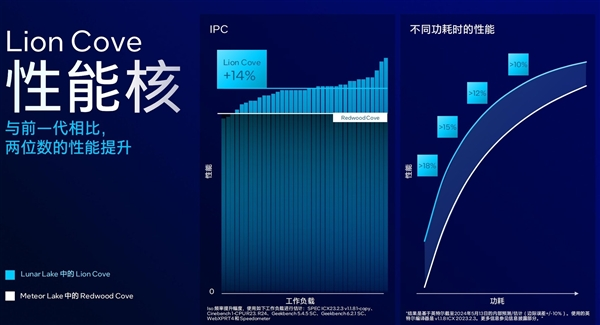
首先,Lunar Lake的性能核代号为Lion Cove,其微架构针对性能和能效、IPC、可扩展性等方面进行了优化。如针对PPA(面积功耗)进行优化,L3共享缓存提升到12MB,存储器子系统进一步改进,引入了基于AI的电源管理,矢量与整数乱序引擎进行了拆分等等。


这一系列改进使得Lion Cove的IPC相较Meteor Lake的Redwood Cove提升14%,并且能够在相同功耗下获得更好的性能,尤其在低能耗下的性能提升幅度达到了18%。
这意味着Lunar Lake能够以更少的耗电量获取更高的性能,从而兼顾性能与续航表现。

Lunar Lake的能效核代号为Skymont,其微架构设计增加了工作负载的覆盖范围并实现了双倍的矢量与AI吞吐能力提升,这使得低功耗岛上的Skymont核心在单线程以及多线程性能方面分别提升2倍和4倍。
再加上更好的电源效率,使得能效核在实现相同性能时,功耗较前代相比更低。


总体来看,Skymont微架构打造的全新能效核,增强了分支预测能力,拥有4MB L2共享缓存,L2缓存带宽提升了2倍,4x 128bit FP和SIMD矢量AI吞吐能力提升2倍,同时具备更好的并行计算能力。
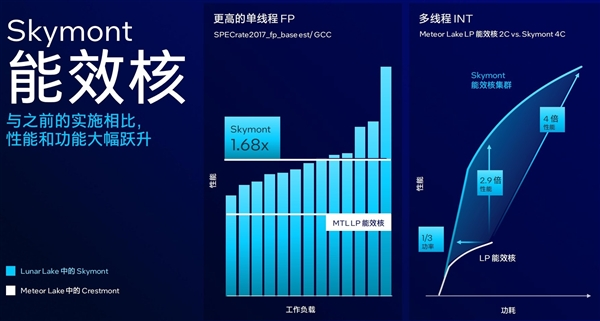

对比Meteor Lake的Crestmont微架构能效核,Skymont单线程FP计算能力提升1.68倍,多线程INT峰值算力是前者的4倍,而达到相同算力的能耗只有前者的1/3。
·全新的线程调度逻辑优化工作负载到核心匹配

此外,Lunar Lake改变了性能核与能效核的调度逻辑,以同时覆盖全面的CPU性能范围,从而优化工作负载到核心的匹配。
Meteor Lake无论在怎样的负载状态下,都会优先调用性能核来承担工作负载,这就会出现明明负载不高的工作任务,也会跑在性能核上的问题,进而影响散热与续航表现。
而Lunar Lake则会优先调用功耗更低的能效核来执行工作负载,之后如果工作负载不断增高,就会调用性能核来提供更好的性能。
这种全新的“大小核”调度逻辑,可以帮助Lunar Lake更好地分配性能与功耗,避免性能核疯狂跑,能效核在一旁“围观”的问题。
之所以能够实现更“聪明”的核心匹配,主要原因有三点:
其一是让线程调度更加智能化,以优化工作负载与核心的匹配;
其二是改善系统与OEM集成来更加实现更为智能和可控的CPU调度。
其三是扩展效率并提升整体的电池寿命。

在开始采用性能核与能效核设计之后,英特尔为酷睿平台引入了Intel Thread Director,也就是英特尔线程调度器。
Lunar Lake采用了改进后的全新线程调度器,旨在优化混合架构下多核心处理器中不同类型核心的利用效率,提高整体性能和能效。
新一代线程调度器通过智能化的调度和资源分配,能够动态调整线程的执行状态,从而实现更高效的计算和更长的电池寿命。
在用户在运行复杂应用和多任务处理时,英特尔线程调度器能确保应用程序顺畅运行,减少卡顿和延迟现象,提升用户体验。
例如在游戏场景中,英特尔线程调度器可以优先调度游戏相关线程到性能核,而将后台更新等任务安排到能效核,确保游戏的流畅运行。
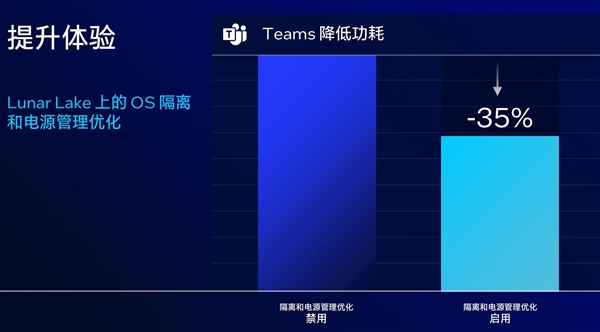
再比如Teams应用,通过基于系统容器和电源管理层面的优化,该项应用的能耗相比Meteor Lake降低35%,显著增强了在线会议时电脑的能效表现。
另外还可以看看Office生产力应用时的能效核与性能核调度逻辑。
第一张图是任务刚刚开始时,工作负载较低的情况下,优先调用能效核来执行;第二张图是任务负载持续爬坡之后需要更高性能时,工作负载会迅速转移到性能核上来。
如果后续性能不需要性能核介入,那么就会一直跑在功耗更低的能效核上,这可以说是非常典型的Lunar Lake“大小核”调度逻辑。
而以往Meteor Lake可能在任务开始时,就会将负载放到性能核上来。

总体来说,全新的英特尔线程调度器通过实时监控和动态调度,实现了对混合架构中不同核心的高效利用。
它不仅提高了系统的整体性能和响应速度,还通过优化资源分配降低了功耗,延长了电池寿命。这项技术在Lunar Lake等平台上展现出了显著的优势,将为用户提供无缝、高效的计算体验。
·全新的Xe2核显释放更强图形与AI性能
CPU部分说完,我们再来看看GPU。

Meteor Lake引入全新的锐炫GPU之后,图形性能提升显著。一方面在游戏端可以在1080p、高画质下用核显运行大型3A游戏,并可以获得35-40fps以上的画面流畅度;另一方面,锐炫核显在Intel OpenVINO加持下, 可以提供更加出色的AI算力,尤其在本地化的Stable Diffusion应用上,文生图、图生图效率提升显著。

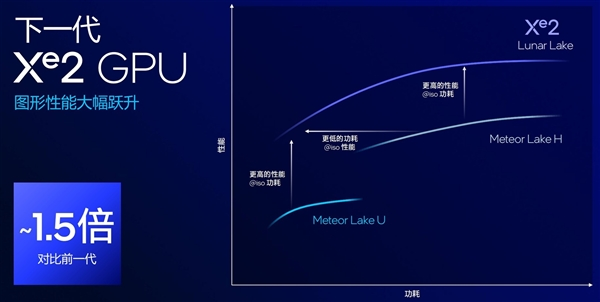
Lunar Lake引入了全新的Xe2 GPU,相比Meteor Lake而言,图形性能提升1.5倍,并且提供了更大的光追单元,帮助提升游戏的画质与真实感。
Xe2 GPU架构提高了硬件功能的利用率,在整个架构上实现更好地工作负载分配,并且加强了硬件和软件集成。
同时在硬件规格方面,Xe2架构也实现了升级,其Xe核心增加到了8个,图形性能自然提升。AI性能的提升则来源于全新引入的Xe矩阵扩展引擎,这一全新的矢量引擎支持4096OPS/clock和2048OPS/clock的INT8和FP16计算,并且改进了固定功能单元,提高了吞吐量,从而优化了AI计算效率。其总体AI算力达到了67TOPS,并且拥有8MB L2缓存。

同时,Xe2 GPU增强了XeSS内核,从而提升了图像处理和渲染效果,并且带来更好的能效比。在同等性能下功耗更低,在同等功耗下性能更高。相比Meteor Lake,Lunar Lake功耗降低了40%。
图形性能和能效升级的同时,Lunar Lake也带来了全新的媒体和显示引擎。

其中,媒体引擎在原有的AV1编解码上增加了VVC解码支持,而显示引擎支持eDP 1.5、DP 2.1、HDMI 2.1接口标准。新的媒体与显示引擎可以更好地支持自适应分辨率流媒体和360°全景视频。

VVC解码也是新引擎的一大亮点,虽然目前支持的比较少,但是VVC相对于AV1而言,保证相近质量的同时文件体积减少了10%,这可以帮助视频流媒体平台进一步缩减成本,是未来视频解码的一大主流方向。
·NPU 4架构带来4倍AI算力升级

Lunar Lake的NPU也迎来大幅升级。全新的NPU 4架构增加了芯片规模、提高了时钟频率和能效,同时针对现代AI进行了优化,以更好地支持LLMs(大语言模型)和Transformer的高效运行。

与Meteor Lake搭载的NPU 3相比,NPU 4的峰值性能高出4倍。
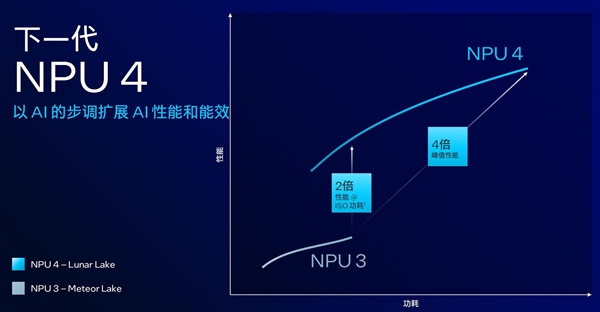
NPU 4被英特尔定义为AI PC最大的集成和专用AI加速器,它集成了12个增强版SHAVE DSP(Streaming Hybrid Architecture Vector Engine Digital Signal Processors),J加速LLMs和Transformer的加速,并且支持原生激活功能和数据转换。
其带宽是Meteor Lake的2倍,内置6个神经计算引擎,MAC(Multiply-Accumulate)阵列能效优化,从而使得AI算力从Meteor Lake的11.5TOPS激增至48TOPS,峰值性能高出4倍,能耗更低、性能更强。

·出色的平台级连接性
计算模块之外,Lunar Lake的平台控制模块提供了出色的连接性。

Lunar Lake原生支持蓝牙5.4、Wi-Fi 7(5Gig)、Thunderbolt 4。PCIe 4.0和PCIe 5.0通道数量进一步提升,新增支持Thunderbolt Share技术【具体参看:雷电接口史诗级强化!一根线完成2台电脑协同应用】,因此Lunar Lake在连接性方面有着天花板级别的生态支持。

·结语
总体来说,Lunar Lake相比Meteor Lake而言,在CPU、GPU、NPU计算性能与能效比方面都有着极其显著的提升。其SoC能耗降低40%,片上封装内存之后使得数据迁移的能耗降低40%。

同时,Lunar Lake架构设计逻辑相较Meteor Lake变化极大,从原先的4大模块整合成计算与平台控制两大模块,CPU、GPU、NPU均采用了全新的微架构设计,IPC性能、AI计算性能、图形性能、能效比、内存性能得到全方位提升。
目前,包括微星、华硕、宏碁在内的多家OEM以及发布基于Lunar Lake的笔记本新品,但是具体上市时间并未公布,同时英特尔也没有给出Lunar Lake家族的具体型号构成。
预计新产品和新平台正式上市时间会在2024年第三季度,其性能体验如何?让我们拭目以待!
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章