新火种
2024-02-21
新火种
2024-02-21 


OpenAI文生视频大模型深度揭秘:真正遥遥领先无可追赶
近日,OpenAI 发布了新的文生视频大模型,名为 “ Sora ”。
Sora 模型可以生成最长 60 秒的高清视频,生成的画面可以很好的展现场景中的光影关系、各个物体间的物理遮挡、碰撞关系,并且镜头丝滑可变。
相信大家已经在朋友圈看到了非常多的文章在展示 OpenAI 的官方演示视频,下面,我们想重点探讨为何 Sora 模型的效果看起来远超市面上我们见过的其他文生视频模型,他们都做了什么?
以防您没看到,我们放几个示例:

示例视频的生成提示词为:
一位时尚的女人走在东京的街道上,街道上到处都是温暖的发光霓虹灯和动画城市标志。她身穿黑色皮夹克,红色长裙,黑色靴子,背着一个黑色钱包。她戴着墨镜,涂着红色口红。她自信而随意地走路。街道潮湿而反光,营造出五颜六色的灯光的镜面效果。许多行人四处走动。

AI想象中的龙年春节,红旗招展人山人海,有紧跟舞龙队伍抬头好奇观望的儿童,还有不少人掏出手机边跟边拍,海量人物角色各有各的行为。

一名年约三十的宇航员戴着红色针织摩托头盔展开冒险之旅,电影预告片呈现其穿梭于蓝天白云与盐湖沙漠之间的精彩瞬间,独特的电影风格、采用35毫米胶片拍摄,色彩鲜艳。

竖屏超近景视角下,这只蜥蜴细节拉满。
首先,在文生视频领域,比较成熟的模型思路有循环网络( RNN )、生成对抗网络( GAN )和扩散模型( Diffusion models ),而本次OpenAI 推出的 Sora 则是一种扩散模型。
虽然 GAN 模型之前一直很火,但图像和视频生成相关的领域,现在处于被扩散模型统治的阶段。
因为扩散模型是有非常卓越的优越性的,相较于 GAN,扩散模型的生成多样性和训练稳定性都要更好。
最重要的是,扩散模型在图片和视频生成上有更高的天花板,因为 GAN 模型从原理上来看本质上是机器对人的模仿,而扩散模型则更像是机器学会了 “ 成为一个人 ”。
这么说或许有些抽象,我们换一个不严谨但通俗好理解的例子:
GAN 模型像是一个勤奋的画家,但不太受控制,因为画家( 生成器 )一边不停对着先作( 训练源 )画画,然后另一边老师( 判别器 )也不停打分。
就在大战无数个回合之后,画家和老师疯狂升级进步,最后直到画家画出逼真的画。
但整个过程不太好控制,经常练着练着就走火入魔,输出一些谁也看不懂的玩意儿。
同时,他的提升过程本质上是对先作的不断模仿,所以他还缺乏创造力,导致天花板也潜在会比较低。
扩散模型,则是一个勤奋且聪明的画家,他并不是机械的仿作,而是在学习大量先作的时候,他学会了图像内涵与图像之间的关系,他大概知道了图像上的 “ 美 ” 应该是什么样,图像的某种 “ 风格 ” 应该是什么样,他更像是在思考,他是比 GAN 更有前途的画家。
也就是说,OpenAI 选择扩散模型这个范式来创造文生视频模型,在当下属于开了个好头,选择了一个有潜力的画家来培养。
那么,另一个疑问就出现了,由于大家都知道扩散模型的优越性,除了 OpenAI 以外,同样在做扩散模型的还有很多友商,为什么 OpenAI 的看起来更惊艳?
因为 OpenAI 有这样一个思维:我曾经在大语言模型上获得了非常好的效果、获得了如此巨大的成功,那我有没有可能参考这个经验获得一次新的成功呢?
答案是可以。
OpenAI 认为,之前在大语言模型上的成功,得益于 Token( 可以翻译成令牌、标记、词元都可,翻译为词元会更好理解一些 ),Token 可以优雅的把代码、数学以及各种不同的自然语言进行统一,进而方便规模巨大的训练。
于是,他们创造了对应 Token 的 “ Patch ” 概念( 块,如果 Token 翻译为词元理解的话,Patch 或许可以被我们翻译为 “ 图块 ” )用于训练 Sora 这个视频模型。
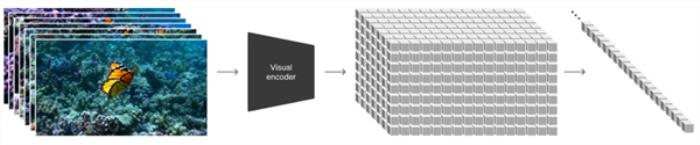
实际上,在大语言模型中,Token 的应用之所以会如此成功,还得益于 Transformer 架构,他与 Token 是搭配着来的,所以 Sora 作为一个视频生成扩散模型,区别于主流视频生成扩散模型采用了 Transformer 架构。( 主流视频生成扩散模型较多采用 U-Net 架构 )
也就是说,OpenAI 赢在了经验与技术路线的选择上。
但是,Transformer 架构这个 “ 成功密码 ”人尽皆知,在文字、图像生成上已经成为了主流,为什么别人没想着在视频生成上用,OpenAI 就用了呢?
这源自另外一个问题:Transformer 架构中全注意力机制的内存需求会随着输入序列长度而二次方增长,所以处理视频这样的高维信号时,计算成本会非常非常高。
通俗点说,就是虽然用了 Transformer 效果会好,但所需的计算资源也是非常恐怖的,这么做不是很经济。
当然,OpenAI 虽然拿各种融资拿到手软,但也依然没那么财大气粗,所以他们并没有直接猛砸资源,而是想了另外一种方式来解决计算成本高昂的问题。
这里我们要先引入 “ latent ” ( 潜 )这一概念,它是一种 “ 降维 ” 或者说是 “ 压缩 ”,意在用更少的信息去表达信息的本质。我们列举一个不恰当但好理解的例子,这就好像我们用一个三视图就能保存记录一个简单的立体物体的结构,而非一定要保存这个立体本身。
OpenAI 为此开发了一个视频压缩网络,把视频先降维到潜空间,然后再去拿这些压缩过的视频数据去生成 Patch ,这样就能使输入的信息变少,有效减小 Transformer 架构带来的计算量压力。
如此一来,大部分问题就都解决了,OpenAI 成功地把文生视频模型套进了其在过去取得巨大成功的大语言模型的范式里,所以效果想不好都难。
除此之外,OpenAI 在训练上的路线选择也稍有不同。
他们选择了 “ 原始尺寸、时长 ” 训练,而非业内常用的 “ 把视频截取成预设标准尺寸、时长 ” 后再训练。
这样的训练给 Sora 带来了诸多好处:
①生成的视频能更好地自定义时长;
②生成的视频能够更好地自定义视频尺寸;
③视频会有更好的取景和构图;
前两点很好理解,第三点 OpenAI 给出了范例,他们做了一个截取尺寸视频训练和原始尺寸视频训练的模型对比:

左侧为截取尺寸视频训练后模型生成的视频,右侧为原始尺寸视频训练后模型生成的视频
另外,为了文生视频能够更好地理解用户的意图,达到更好的生成效果,OpenAI 也在 Sora 模型上加入了一些巧思。
首先,训练 Sora 这样的文生视频模型,需要大量含有文本说明的视频素材,所以 OpenAI 利用自家 DALL·E 3 的 re-captioning 功能,给训练用的视频素材都加上了高质量文本描述,他们表示这样可以提高输出视频的整体质量。
除了训练端,在输入端他们也动了脑筋,用户输入的提示词并非直接交给 Sora 进行生成的,OpenAI 利用了 GPT 的能力,在用户给 Sora 输入提示词的时候,GPT 会先将用户输入的提示词进行精准的详尽扩写,然后再将扩写后的提示词交给 Sora,这样能更好地让 Sora 遵循提示词来生成更精准的视频。
好了,到这里,我们对 Sora 模型为什么看起来更强的简要解析就结束了。
从整体来看,你会发现 Sora 模型的成功并非偶然,他能有如此惊艳的效果,全都得益于 OpenAI 过去的工作,包括 GPT、DALL·E 等,有些是直接调用,有些是借用了思路。
或许我们可以说,OpenAI 自己先成为了一个巨人,然后再站在自己这个巨人的肩膀上,成为了一个新的巨人。
而相对应的是,无论国内还是国外的其他竞争对手,或许会因为文生文、文生图上的技术差,在未来被甩的更远。
所谓 “ 弯道超车 ”、“ 差距只有 X 个月 ”,或许是不存在的,只是自我安慰。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章