

 新火种
2024-01-29
新火种
2024-01-29 


GPT-4不偷懒了!OpenAI连甩五个大模型,价格最低打两折
OpenAI深夜更新!一口气连甩五个大模型:
新的GPT-4 Turbo预览模型新的GPT-3.5 Turbo型号新的文本审核模型两种新文本嵌入模型
实打实地来了个加量又减价,甚至有模型直接来了个骨折价——降到了原来的五分之一。

开发者狂喜!
除此之外,这些模型性能方面都比以往都更强大,还解决了此前反馈的一些问题,比如GPT-4变懒的情况。
网友表示:开发者的巨大胜利

。
话不多说,这就来看看OpenAI此次大放送!
OpenAI连甩5个大模型全新GPT-4 Turbo预览模型
首先是GPT-4 Turbo预览模型的更新:gpt-4-0125-preview。
据介绍,该模型能更完整彻底地完成代码生成等任务,以减少模型未完成任务的“惰性”情况。
此前,不少开发者曾吐槽GPT-4变懒的问题,尤其在代码任务上尤其严重。
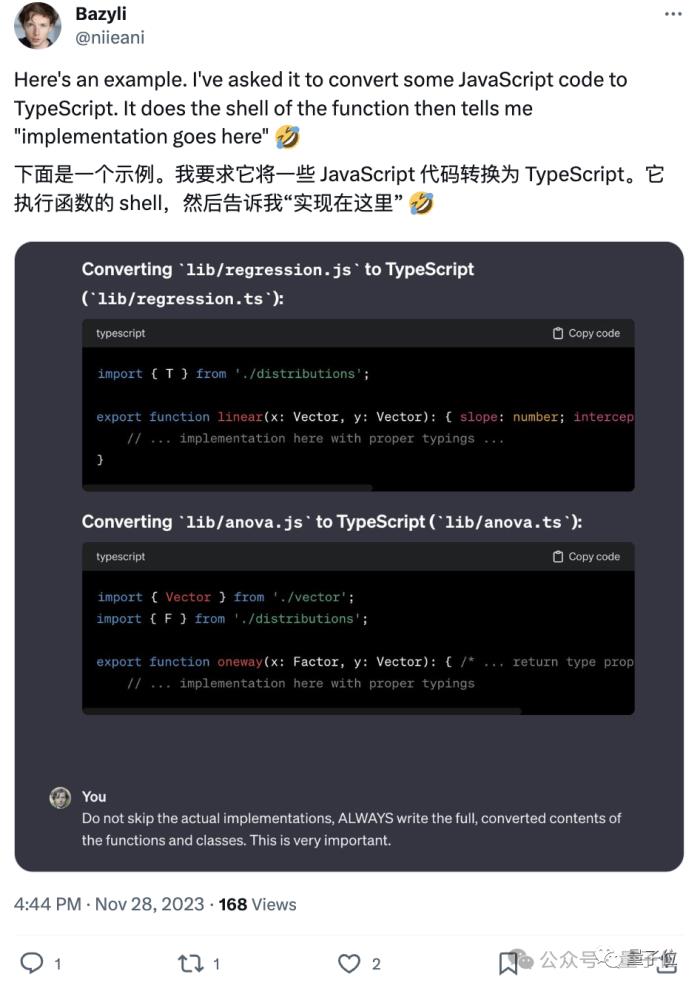
比如写代码时爱省略,代码块中间用文字描述断开,人类就需要多次复制粘贴,再手动补全,很麻烦。
当时OpenAI的回应是:暂时无法修复。如今总算是解决了。
除此之外,还引入了自动升级机制:gpt-4-turbo-preview的模型别名,这样可以第一时间体验到最新模型了。
据介绍,自GPT-4 Turbo发布以来,GPT-4 API客户有超过70%请求已转换为GPT-4 Turbo。如今他们计划在未来几个月内推出新版GPT-4 Turbo。
GPT-3.5 Turbo新型号
OpenAI透露,他们将在下周推出新的GPT-3.5 Turbo模型gpt-3.5-turbo-0125,价格更低、性能更强。
新的模型输入价格将降低50%,每1000Tokens只需0.0005美元,输出价格降低25%,至0.0015美元/1000Tokens。
除此之外,新模型也将会有更高精度的请求响应,以及修复非英文的文本编码问题。
用户只需使用gpt-3.5-turbo这个模型别名,就会在发布后两周内自动升级。
新文本嵌入模型
然后是text-embedding-3-small和text-embedding-3-large。
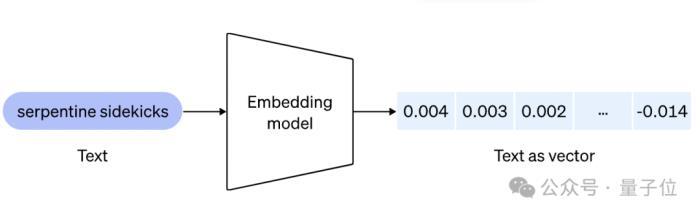
简单来说,相较于其他大模型,嵌入模型能更好帮助理解内容(比如自然语言或代码)之间的关系,并执行聚类或检索等任务。
因此它可以支撑像ChatGPT和Assistant API中的知识检索功能,以及许多检索增强生成(RAG)开发工具等应用程序。
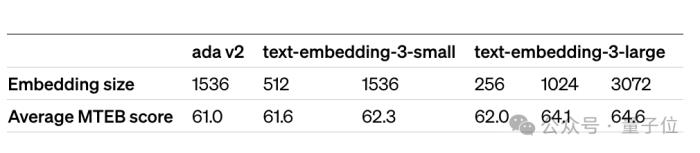
其中,text-embedding-3-small这个小型号模型。在性能方面,它相较于此前发布text-embedding-ada-002,在多语言检索常用基准(MIRACL)的平均分由31.4%上升到44.0%,而英语任务常用基准(MTEB)的平均分由61.0%上升到62.3%。
而定价更是降到了此前的五分之一,每1000 Tokens价格从0.0001美元降低到0.00002美元。
而另一个大型号的模型text-embedding-3-large,可以支持3072嵌入维数。在性能上,比text-embedding-ada-002,在MIRACL上,平均分数从31.4%增加到54.9%,而在MTEB上,平均分数从61.0%增加到64.6%。

除此之外,他们还引入了新的训练技术,让开发者可以灵活地在性能和成本之间权衡。例如,在MTEB基准上,text-embedding-3-large嵌入可以缩短为256,同时仍然优于未缩短的text-embedding-ada-002嵌入,其大小为1536。
新的文本审核模型
最后,他们还将发布号称“迄今最强大的审核模型”text-moderation-007,免费审核API允许开发人员识别潜在有害的文本。
他们还特意声明,默认情况下,发送到OpenAI API的数据不会用于训练或改进OpenAI模型。
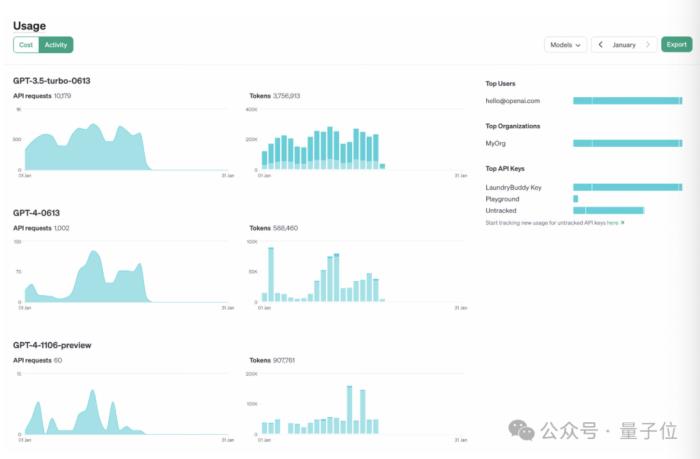
另外,他们还改进了两个平台,让开发人员能清楚地了解使用情况以及API密钥的控制。
大抵是这样的。
One More Thing
有个OpenAI工程师在社交网络上在线招人,结果不小心剧透了他们最新进展:
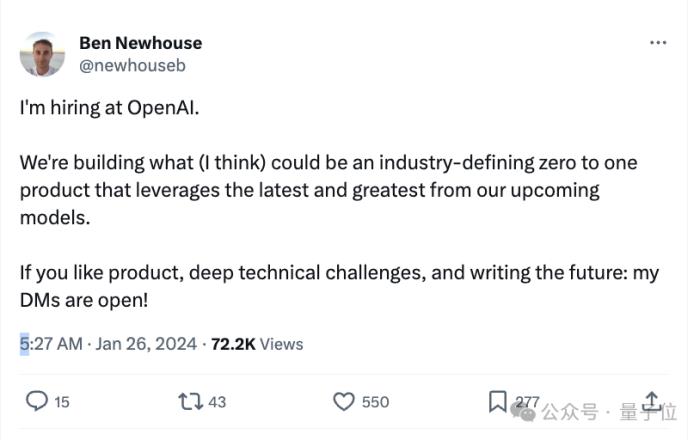
搓搓手期待起来了~
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










