新火种
2024-01-04
新火种
2024-01-04 


百度交了份“大”作业:文心一言用户破1亿,累计37亿字文本创作,能力再升32%!
今年国产大模型的最后一声枪响,属于百度:

这便是在深度学习“春晚”——WAVE SUMMIT+ 深度学习开发者大会2023中,百度CTO王海峰披露的有关文心大模型的最新数据。
值得一提的是,本届“春晚”与以往有所不同,从2019年开始以“一年两届”的节奏,已然是来到了第10届的标志性节点。
而在这整整五年的进程中,除了文心大模型从1.0逐步迭代到4.0之外,每届WAVE SUMMIT的另一个主角飞桨,也迎来了里程碑。
从王海峰公布的一组飞桨生态的数据便可感知一二:
开发者规模:从2019年的150万,直接提升一个量级,达到1070万;企业数量:服务了23.5万家企事业单位;模型数量:基于飞桨创建了86万个模型。
那么在百度交出这份“大作业”的同时,文心一言和飞桨在具体表现上又如何?
我们现在一同来看下。
文心一言更强了首先是文心一言。
百度集团副总裁吴甜在大会中也总结了一组与之相关的数据:
什么概念?
字数规模相当于10部《永乐大典》、500套《鲁迅全集》、1万本《三体》。

在代码编写方面,文心一言也已经输出了3亿行代码,涵盖到所有的主流编程语言。
除此之外,聚焦到更多细分任务,文心一言还完成了累计达到4亿字的专业合同、制定500万次的旅行计划,以及240万次的建议和支持等等。
不仅如此,为了让文心一言能够变得“更聪明”,百度还把AI Agent,即智能体技术融入了进来。

百度在智能体上的打法,是在文心一言中开发了两个系统:
系统一:以模型和记忆为基础,给予用户诸如直接反应的的答复生成;
系统二:加强理解、规划、反思、进化等一系列的能力。
在二者“双buff”加持之下,文心一言就可以把知识和工具用得更加灵活,问题也能剖析得更深。
更利好的一个消息是,现在,文心一言的智能体模式已经面向专业版用户进行邀请测试了!
至于“新发布”这事上,百度这次在大模型上剑指的就是生态——星河社区整体大升级。
从下至上来看,在算力层方面,星河社区已经为开发者提供异构算力的支持,包括英伟达、英特尔和中科曙光等等。
通用组件方面,便可实现多语言编程环境和服务化部署。
在模型开发层面,星河社区提供了飞桨产业级模型库以及飞桨的全流程开发工具,可以让开发者用更灵活的方法去搞模型开发。
最后是在应用开发方面,百度也提供了多种模式,包括AI绘画和AI对话的零门槛开发方法,以及大模型工具中心和多工具智能编排等。

而刚才提到的大模型工具中心,则是此次星河社区中重点新发的内容之一。
例如在大模型工具中心的加持之下,现在要开发一个“旅游助手”,现在就变成“点点点”这样的操作了。
首先来到飞桨AI Studio星河社区页面的应用栏目,点击右上角的“创建应用→零代码开发”,然后点击“多工具智能编排”,并输入项目名称:

为了让“旅游助手”更加专业,还可以通过在知识库中上传更专业的文档,让大模型变成专家,提升特定领域的问答能力。
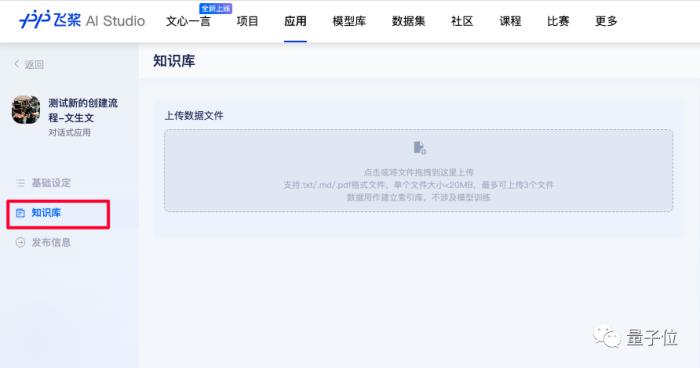
还可以点击“工具挂载”,把百度已经提供出来的包括多模态输入输出等在内的众多挂载工具加进去。

最后只需再点击“发布”,一个应用程序就搭建好了。
不难看出,现在开发一个应用程序,哪怕是不会编程的小白都能操作得游刃有余。
而在这背后,实则是百度将飞桨已经积累了的产业级模型库中的数百个模型塞了进去,涵盖金融、制造业、工业等等;也包括百度大脑的AI能力,覆盖语音、视觉、自然语言处理等主流的AI技术方向。
不仅如此,百度为了让文心一言变得更强,还特意让它“拜师”到10个行业的10位专家门下。

这些导师所涵盖的领域也是极为广泛,包括艺术设计、科技传播、交通运输、文学创作、医疗健康等等。
吴甜表示:
当然,让文心一言变强,也离不开背后飞桨的支持。
飞桨再升级:搞开发门槛又降低了在本届WAVE SUMMIT中,飞桨开源框架也以全新的姿态现身——V2.6。
我们依旧是先来整体看下升级内容。
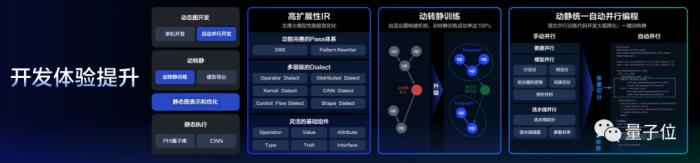
首先在底层,飞桨夯实了高扩展性中间表示体系,可以更好地支撑更极致的性能优化。
其次动转静训练方面,飞桨做了进一步的升级,通过自适应的图构建技术,使得整个动转静的成功率大幅提升,达到了100%。
针对分布式开发困难的问题,飞桨研发了动静统一的自动并行编程,开发者只需要了解张量切分,便可以轻松地开发相关的混合并行训练代码。
与此同时,大模型的套件也进行了全流程的优化,从预训练到精调、压缩、推理、部署,全环节都得到了相应的改善。

最后,在最具挑战的算力方面,飞桨也在适配方面做了相应的升级。
例如计算执行方面,可以支持多Stream的并行算子调度;在硬件厂商进行开发方面,可以通过 “自定义加速算子” 灵活接入根据自身硬件特性定制的不同颗粒度的大算子等。
并且在结合文心大模型适配的过程当中,飞桨也进行了软硬件协同,支持硬件厂商建设在硬件层的Transformer大算子加速库,协助硬件厂商加速软件栈的完善。
而基于上述的升级,百度AI技术生态总经理马艳军也带来三个“新发布”——大模型重构开发工具链,带来三大开发新范式。

第一个新发布就是Comate AutoWork——2分钟开发一个领取Comate试用权益的程序。
简单来说,就是开发者只需要提需求,剩下的工作都可以交给Comate AutoWork来解决。
例如我们提一个这样的需求:
而后你也附上一个PRD文档,让Comate AutoWork更好地理解需求。
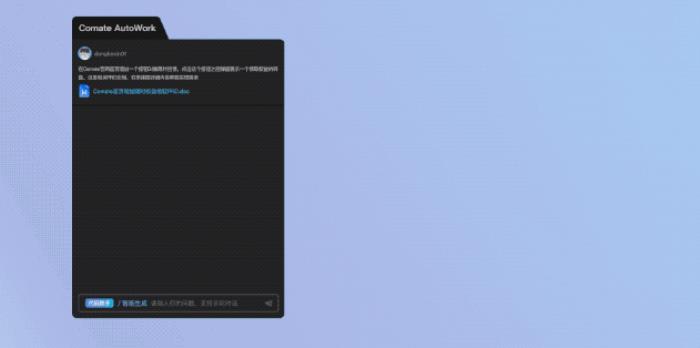
可以看到,Comate AutoWork接下来就会自动分析PRD文档,做总结提炼等工作。
对于不清楚地方,它还会自己提问,我们所要做的就是再次对需求做说明和澄清。例如:
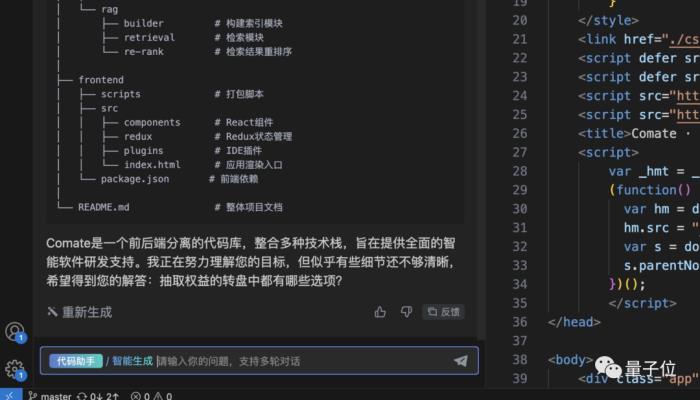
之后,AutoWork就会给出执行计划,并根据开发者的反馈做动态调整。
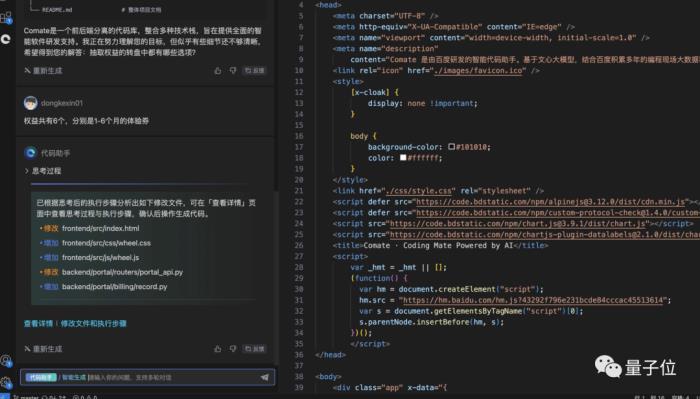
之后,AutoWork对于代码文件还会标注出来哪些需要“修改”,方便开发者做进一步的调整。
开发者对于需要修改的文件,同样可以用自然语言做调整;最终,开发者就可以检查代码、采纳,并在本地做测试了。
飞桨第二个新发布,则是低代码开发工具PaddleX升级到了2.2版本。
以字符识别为例,以往哪怕是用到了PaddleOCR,对于较复杂的文件来说,识别结果可能是这样的:
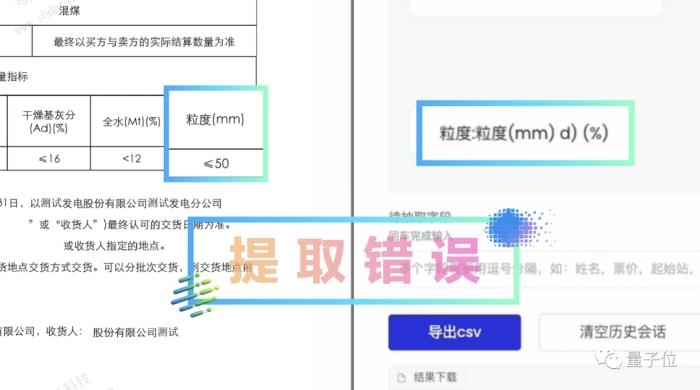
为此,在2.2版本中,飞桨专门做了PP-ChatOCR,再次进行同样的任务,结果就完全正确了:

马艳军在现场表示:
至于飞桨最后一个发布——面向生态中广大开发者的文心一言开发机制。
星河社区用户可以通过API和SDK使用文心大模型的基础能力,并支持插件、多工具智能编排开发,以低代码和零代码开发界面,实现AI原生应用开发。
文心一言开发机制还升级了配套开发工具、优化注册接入自动化流程、支撑开发者深度效果调优、助力应用推广,全面降低应用开发门槛。典型应用开发时间缩短40%以上,端到端效果提升30%以上。
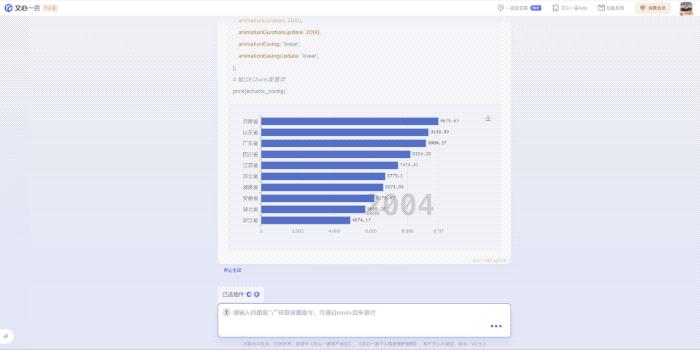
例如我们要制作“制作全国TOP10省份常住人口随时间动态排序的图表”,Prompt提给文心一言是不是就能实现了?是的!这里还用到了文心一言插件“代码解释器”。
上传一份数据后,用自然语言提出自己的需求:
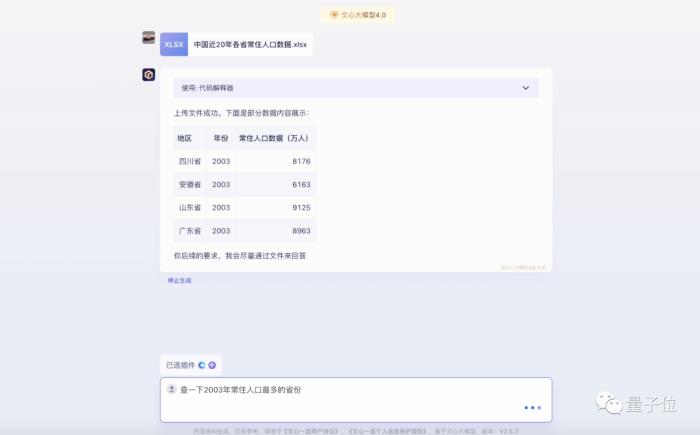
可以看到,模型会根据上述的需求自动生成相应的Python代码。而后我们可以继续提需求:
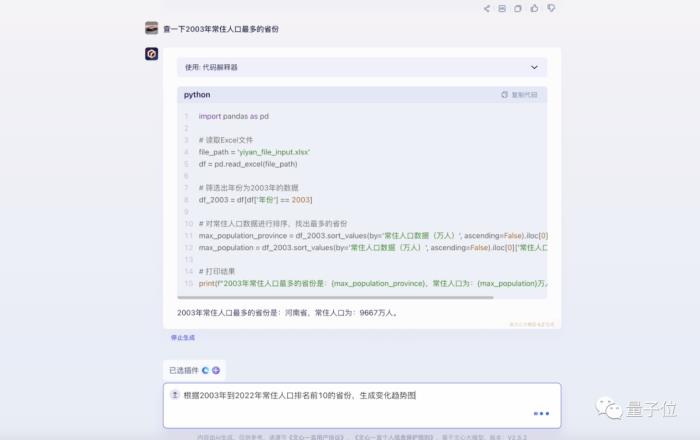
最终,在接收到这个指令之后,我们想要的动态图表就呈现出来了:
以上便是本届WAVE SUMMIT中最为重磅的升级内容了。
那么最后一个问题便是:
五载十届,百度做到了什么?首先,非常直观的一点感受,就是百度已然通过AI技术的力量,把“搞开发”这件事情的门槛狠狠地打了下去。
纵观第十届WAVE SUMMIT,与开发相关的所有内容,近乎都是通过自然语言的prompt,或者“点点点”的动作来完成。
不过很显然的,能够把开发门槛降低至如此,定然不会是一蹴而就的事情。
若是我们把WAVE SUMMIT五年历程的核心铺开来看,那么百度在AI开发的路径便会更加清晰一些:
2019年:提出深度学习是智能时代的操作系统;深度学习推动人工智能进入工业大生产阶段。2020年:打造AI新型基础设施,云智一体加速产业智能化;2021年:融合创新,降低门槛;2022年:深度学习平台加速大模型,夯实产业智能化基座;2023年:大语言模型为通用人工智能带来曙光。

虽然百度每年在WAVE SUMMIT中的“主旨”会有所变化,但从中我们也不难看出变中的“不变”——
做好人工智能时代的基础平台。
无论是在投入工业大生产阶段,亦或是现如今人人皆可开发的大模型时代,“文心大模型+飞桨”强强联手的模式,似乎都是在底部充当强劲马达的角色,为上层应用的开花结果提供源源不断的动能。
而历届WAVE SUMMIT着重强调的生态建设亦是如此。
其重要性正如苹果、安卓在移动时代下的生态大战一般,得生态者为王;而人工智能时代之下,技术与生态需并行的重要显得格外突出。
或许这也正是王海峰在今年两次的WAVE SUMMIT中都提到“文心加飞桨,翩然赴星河”的原因了,而这“星河”便是通用人工智能的星辰大海。

总而言之,百度在WAVE SUMMIT的“五载十届”中,确实是做稳了人工智能时代的基础平台。
那么在此基础之上,在科技日新月异的未来,百度还将带来怎样的技术变革,是值得期待一波了。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章