Meta的视频合成新框架又给了我们一点小小的震撼。
就今天的人工智能发展水平来说,文生图、图生视频、图像/视频风格迁移都已经不算什么难事。生成式 AI 天赋异禀,能够毫不费力地创建或修改内容。尤其是图像编辑,在以十亿规模数据集为基础预训练的文本到图像扩散模型的推动下,经历了重大发展。这股浪潮催生了大量图像编辑和内容创建应用。基于图像的生成模型所取得的成就基础上,下一个挑战的领域必然是为其增加「时间维度」,从而实现轻松而富有创意的视频编辑。一种直接策略是使用图像模型逐帧处理视频,然而,生成式图像编辑本身就具有高变异性—即使根据相同的文本提示,也存在无数种编辑给定图像的方法。如果每一帧都独立编辑,很难保持时间上的一致性。在最近的一篇论文中,来自Meta GenAI团队的研究者提出了 Fairy——通过对图像编辑扩散模型进行「简单的改编」,大大增强了AI在视频编辑上的表现。以下是Fairy的编辑视频效果展示:




Fairy 生成 120 帧 512×384 视频(4 秒时长,30 FPS)的时间仅为 14 秒,比之前的方法至少快 44 倍。一项涉及 1000 个生成样本的全面用户研究证实,该方法生成质量上乘,明显优于现有方法。怎么做到的?据论文介绍,Fairy以基于锚点的跨帧注意力概念为核心,这种机制可隐性地跨帧传播扩散特征,确保了时间一致和高保真的合成效果。Fairy 不仅解决了以往模型在内存和处理速度等方面的局限性,还通过独特的数据增强策略提高了时间一致性,这种策略使模型等价于源图像和目标图像的仿射变换。

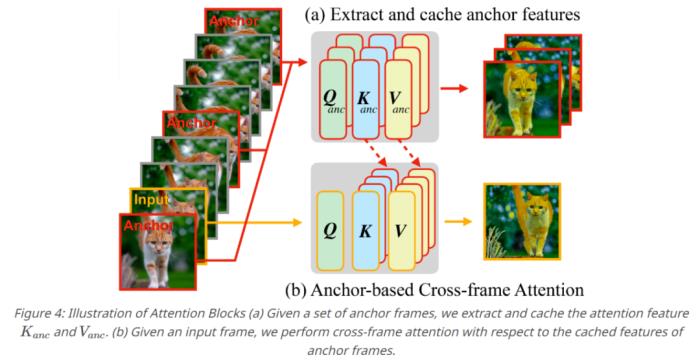
方法Fairy在扩散模型特征的背景下对以前的跟踪-传播(tracking-and-propagation)范式进行了重新审视。特别是,该研究用对应估计( correspondence estimation)架起了跨帧注意之间的桥梁,使得模型在扩散模型内可以跟踪和传播中间特征。跨帧的注意力图可以解释为一种相似性度量,用来评估各个帧中token之间的对应关系,其中一个语义区域的特征会将更高的注意力分配给其他帧中的相似语义区域,如下图3所示 。因此,当前的特征表示通过注意力帧间相似区域的加权和进行细化和传播,从而有效地最小化帧之间的特征差异。

一系列操作下来产生了基于锚点的模型,这是 Fairy 的核心组件。为了确保生成视频的时间一致性,该研究采样了K个锚点帧,从而提取扩散特征,并且提取的特征被定义为一组要传播到连续帧的全局特征。当生成每个新帧时,该研究针对锚点帧的缓存特征将自注意力层替换为跨帧注意力。通过跨帧注意力,每个帧中的 token都采用锚点帧中表现出类似语义内容的特征,从而增强一致性。
实验评估在实验部分,研究者主要基于指令型图像编辑模型来实现Fairy,并使用跨帧注意力替换模型的自注意力。他们将锚帧的数量设置为3。模型可以接受不同长宽比的输入,并将较长尺寸的输入分辨率重新扩展为512,并保持长宽比不变。研究者对输入视频的所有帧进行编辑,而不进行下采样。所有计算在8块A100 GPU上分配完成。定性评估研究者首先展示了Fairy的定性结果,如下图5所示,Fairy可以对不同的主题进行编辑。


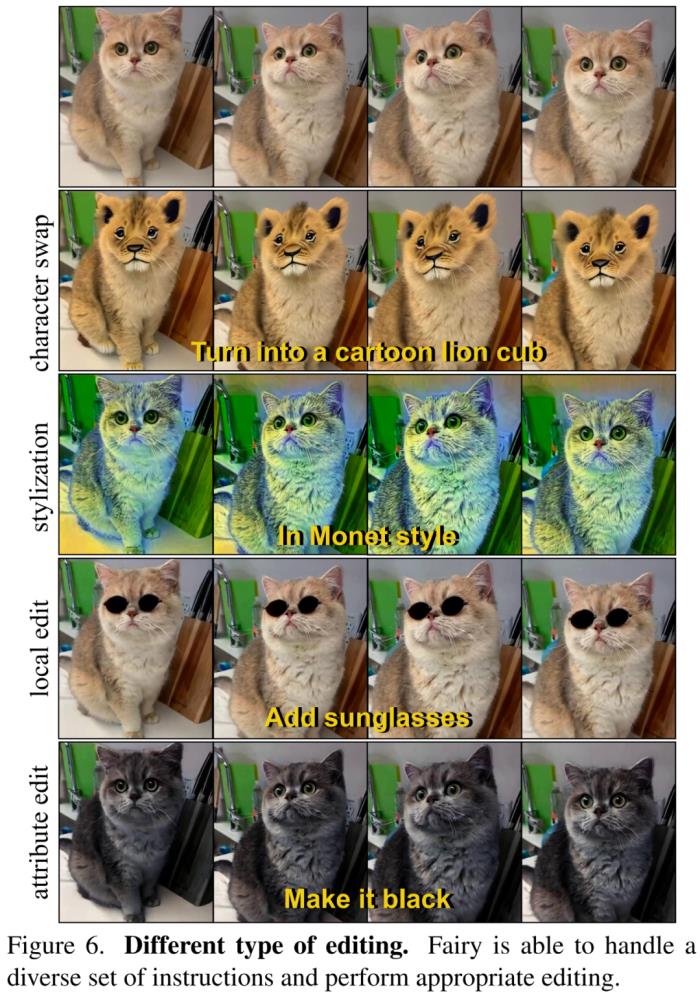
在下图6中,研究者展示了Fairy可以按照文本指令来进行不同类型的编辑,包括风格化、角色变化、局部编辑、属性编辑等。
下图9展示了Fairy可以根据指令将源角色转换为不同的目标角色。


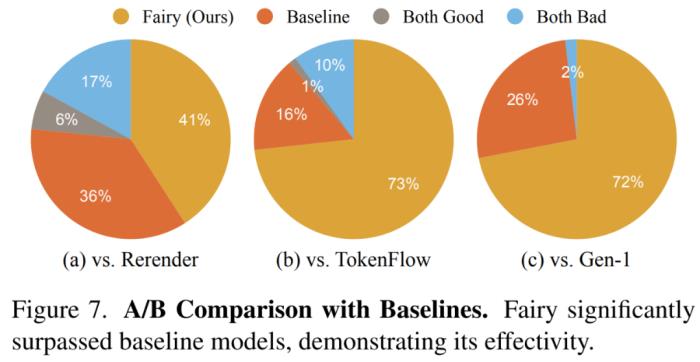
定量评估研究者在下图7中展示了整体质量比较结果,其中Fairy生成的视频更受欢迎。
下图10展示了与基线模型的视觉比较结果。

更多技术细节和实验结果参阅原论文。


 新火种
2024-01-02
新火种
2024-01-02