新火种
2023-12-26
新火种
2023-12-26 


NeurIPS2023Spotlight|腾讯AILab绝悟新突破:在星际2灵活策略应对职业选手
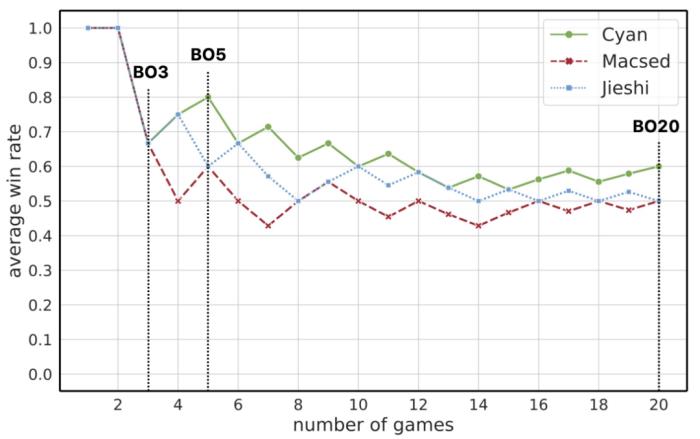
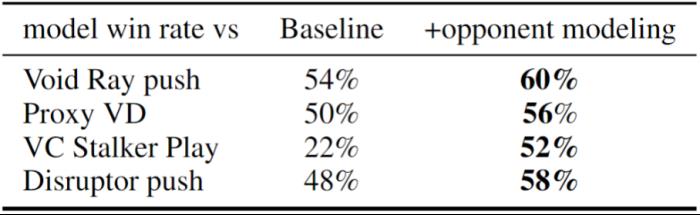
近日,腾讯 AI Lab 的游戏 AI 团队宣布了其决策智能 AI "绝悟" 在《星际争霸 2》中的最新研究进展,提出一种创新的训练方法显著提升了 AI 的局内策略应变能力,使其在考虑了 APM 公平的对战环境中,与 3 位国内顶尖的神族职业选手各进行多达 20 局神族 vs 神族的对战,稳定地保持 50% 及以上的胜率。该成果已获 NeurIPS 2023 Spotlight 论文收录。
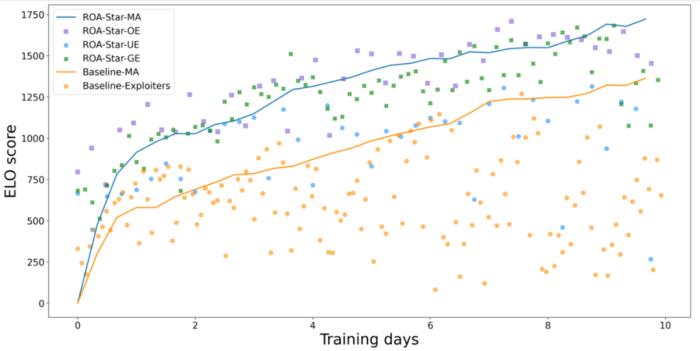
实时策略游戏(RTS)以其复杂的游戏环境更贴近现实世界,一直是 AI 研究的焦点和挑战所在。《星际争霸 2》作为其中极具代表性的游戏,因其对资源收集、战术规划和对手分析的高实时要求,已成为业内广泛用于训练和验证 AI 决策能力的理想平台。早在 2018 年,腾讯 AI Lab 研发的 AI 就已击败游戏内最高难度的 AI。业界的联盟训练方法(League)虽然在星际 AI 强度上取得了突破性进展,但其中在 AI 局内策略应变能力以及训练效率存在不足。针对这些问题,腾讯 AI Lab 研发了新的算法进行改进,一方面提出了一种基于目标条件的强化学习(Goal-Conditioned RL)方法来训练利用者(Exploiter),使利用者在有限资源下能够高效探索多样策略并击败联盟中的其他智能体(Agent);另一方面通过引入对手建模机制,有效提升了智能体面对不同对手战术的应变能力。
这项研究有助于推进 AI 智能化,增强 AI 应对复杂问题的泛化能力。在从 MOBA 到足球、RTS,再到 3D 开放世界游戏(如 Minecraft)等多样化游戏环境,“绝悟” 持续展现了其决策能力的提升。展望未来,决策智能 AI 将能更好地适应人类的真实需求,解决现实世界的复杂问题。基于目标条件的强化学习提升利用者训练效果利用者(Exploiter)是联盟训练中的重要角色,用于发现联盟中其他智能体的弱点,以丰富其他智能体陪练的对手池策略,为提升智能体策略应变能力提供基础环境。
在经典的星际 AI 联盟训练框架中,利用者并没有具体的目标策略指导,而是通过不断的随机探索来识别主智能体(Main Agent)和整个联盟的弱点。然而,考虑到《星际争霸 2》策略空间的庞大和复杂性,这种方法可能导致资源浪费和训练低效。为了在有限的计算资源下提升利用者的学习效果,本研究提出了一种新颖的基于目标条件的强化学习训练方法。该方法让利用者能够自动挑选有 “潜力” 的宏观策略,并在相应宏观策略条件下进行训练,发现联盟其他智能体的弱点。
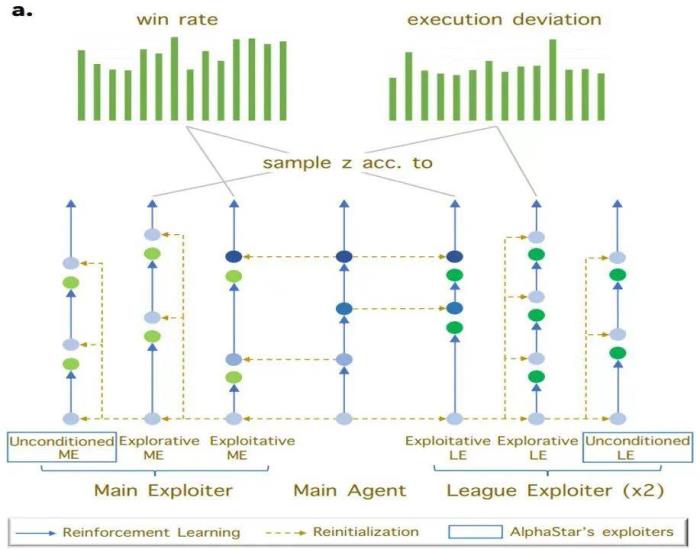
图 1: 基于 goal-conditioned rl 的 exploiter 训练示意图如图 1 所示,新方法通过评估主智能体在不同宏观策略条件下的胜率和执行偏差,来指导利用者的策略选择。从主智能体的高胜率宏观策略中采样的利用者被称为利用型利用者(Exploitative Exploiter),它的特点在于参数会重置为当前主智能体的参数,利用主智能体在该宏观策略下的高胜率能力,通过强化学习进一步提高微操技能,以击败其他智能体。同时,为了提升联盟中能够执行的宏观策略多样性,研究团队引入了探索型利用者(Explorative Exploiter)。探索型利用者专注于学习主智能体在执行上存在大偏差的宏观策略,以充分挖掘这类宏观策略的价值。
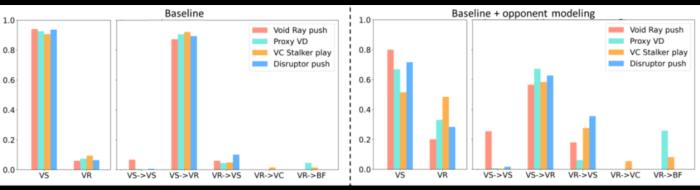
在训练过程中,新方法除了将探索型利用者的参数重置为监督学习模型的参数外,还引入了课程学习机制和目标策略引导损失函数,以帮助其有效学习主智能体难以掌握的宏观策略。基于对手建模提升 AI 局内策略应变能力局内策略应变能力在《星际争霸 2》中至关重要,同时也是 AI 研究的一大挑战。这一能力指的是 AI 根据对手的实时策略做出合理的自身策略调整。其难点在于 AI 需要在不完全的信息环境中快速准确地解读和预测对手的策略,这不仅需要对复杂场景信息做高度抽象,还对预测能力有很高的要求。本研究基于对手建模的理念,增加了一个辅助任务网络,专门用于估计对手的策略,并将这些信息的隐空间表达应用于主网络的策略调整学习。
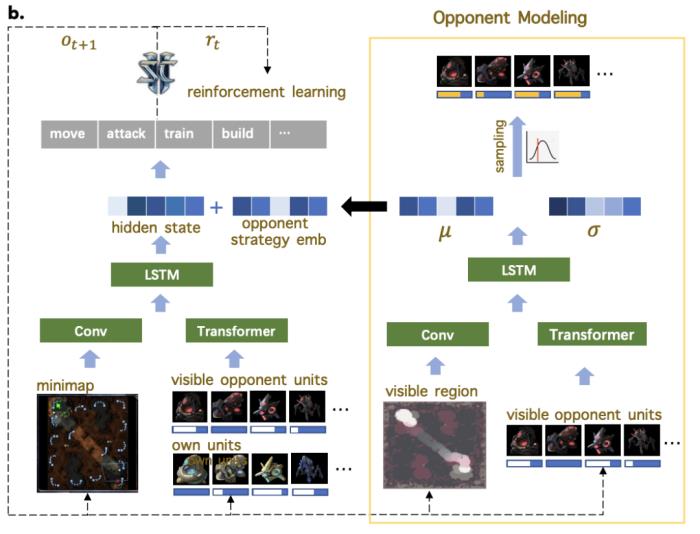
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章