蒙娜丽莎打哈欠,小鸡学会举铁……谷歌VideoPoet大模型表现很亮眼。
2023 年底,科技公司都在冲击生成式 AI 的最后一个关卡 —— 视频生成。本周二,谷歌提出的视频生成大模型上线,立刻获得了人们的关注。这款名为 VideoPoet 的大语言模型,被人们认为是革命性的 zero-shot 视频生成工具。VideoPoet 既可以文生视频、图像生视频,又能风格迁移,视频转语音。从效果上看,它可以构建多样化且流畅的运动。

消息一出,有很多人表示欢迎:看看目前的几个成品效果不错,大模型技术发展的速度也太快了。
有人对于这个大模型生成视频的长度表示惊讶:

来源:
twitter还有人表示这是一个革命性的大语言模型。
也有人呼吁,谷歌需要赶紧把 VideoPoet 开源了,大趋势不等人。随着生成式 AI 的发展,最近出现了一波新的视频生成模型,这些模型展示了令人惊叹的画面质量。当前视频生成的瓶颈之一是产生连贯的大动作。但在许多情况下,即使是领先的模型也只能产生较小的运动,或者当产生较大的运动时,会表现出明显的伪影。为了探索语言模型在视频生成中的应用,来自谷歌的研究者引入了一种大语言模型(LLM)VideoPoet,能够执行各种视频生成任务,包括文本到视频、图像到视频、视频风格化、 视频修复和扩展,以及视频转音频。VideoPoet 效果展示文本生成视频提示:一只狗戴着耳机听音乐,细节丰富,8k。

提示(从左到右):一条从嘴里射出激光束的鲨鱼;泰迪熊手牵着手走在雨天的第五大道上;举铁的小鸡。

提示(从左到右):黄色蒲公英花瓣制成的狮子在咆哮;地球表面发生大规模爆炸;一匹马在梵高的星夜中驰骋;穿着盔甲的松鼠骑着鹅;熊猫在自拍。

图像生成视频对于图像到视频,VideoPoet 可以获取输入图像并通过提示将其动画化。蒙娜丽莎开始打哈欠,只要输入一张图片,外加一句提示:一个女人打哈欠。就会得到下面的效果。

提示(从左到右):一艘船在波涛汹涌的大海上航行,有雷暴和闪电,油画风格;飞过有许多闪烁星星的星云;大风天,一个拄着拐杖站在悬崖上的流浪者,俯视着下面浮动的云海。

将视频风格化VideoPoet 还能够根据文本提示对输入视频进行风格化。提示(从左到右):泰迪熊在干净的冰湖上滑冰;一只金属色的狮子在熔炉的光芒下咆哮。

生成音频VideoPoet 还能够生成音频。首先让模型生成 2 秒的剪辑,然后尝试在没有任何文本指导的情况下预测画面的音频。这样一来,VideoPoet 能够从单个模型生成视频和音频。
长视频VideoPoet 还能生成长视频,默认是 2 秒。通过调节视频的最后 1 秒并预测接下来的 1 秒,这个过程可以无限地重复,以生成任意时长的视频。下面是 VideoPoet 从文本输入生成长视频的示例展示。提示:FPV 镜头展示了丛林中一座非常锋利的精灵石城,有明亮的蓝色河流、瀑布和大而陡峭的垂直悬崖面。

扩展视频用户可以改变提示,从而扩展视频。原始视频是两只浣熊骑着摩托车在松树环绕的山路上行驶,8k。扩展后的视频是两只浣熊骑着摩托车,浣熊身后落下流星,流星撞击地球并爆炸。

交互式视频编辑对于提供的输入视频(最左边),用户可以改变物体的运动来执行不同的动作。如下所示,中间三个没有文本提示,最后一个文本提示为:烟雾背景下启动。

视频修复VideoPoet 可以在视频被遮住的部分添加细节,也可以选择通过文本引导进行修复。


为了展示 VideoPoet 的功能,谷歌还制作了一部由 VideoPoet 生成的多个短片组成的小短片。剧本是 Bard 编写的,是关于一只旅行浣熊的短篇故事,并附有逐个场景的分解和附带的提示列表。然后,谷歌为每个提示生成视频剪辑,并将所有生成的剪辑拼接在一起以生成最终视频。
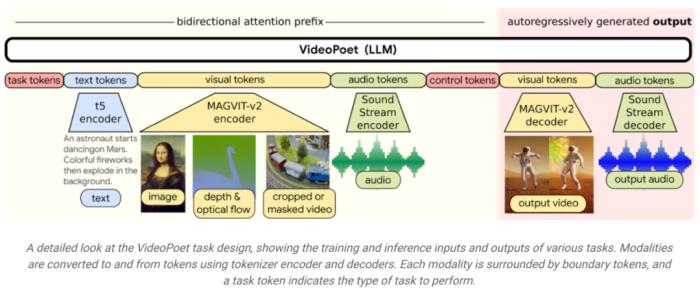
方法简介如下图所示,VideoPoet 可以将输入图像动画化以生成一段视频,并且可以编辑视频或扩展视频。
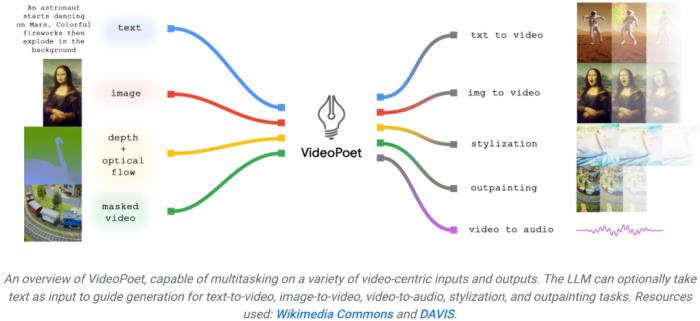
在风格化方面,该模型接收表征深度和光流的视频,以文本指导的风格绘制内容。视频生成器使用 LLM 进行训练的一个关键优势是,可以重复使用现有 LLM 训练基础设施中引入的许多可扩展的效率改进。然而,LLM 是在离散 token 上运行的,这使得视频生成具有挑战性。而视频和音频 tokenizer 可以用来将视频和音频剪辑编码为离散 token 序列,并且也可以转换回原始表征形式。通过使用多个 tokenizer(用于视频和图像的 MAGVIT V2 和用于音频的 SoundStream),VideoPoet 训练自回归语言模型来学习跨视频、图像、音频和文本的多个模态。一旦模型生成以某些上下文为条件的 token,就可以使用 tokenizer 解码器将它们转换回可视化的表征形式。
评估结果研究团队使用各种基准来评估 VideoPoet 在文本到视频生成方面的表现,以将结果与其他方法进行比较。为了确保中立的评估,该研究在各种不同的 prompt 下运行了所有模型,没有挑选示例,并要求人类评估者进行偏好评分。
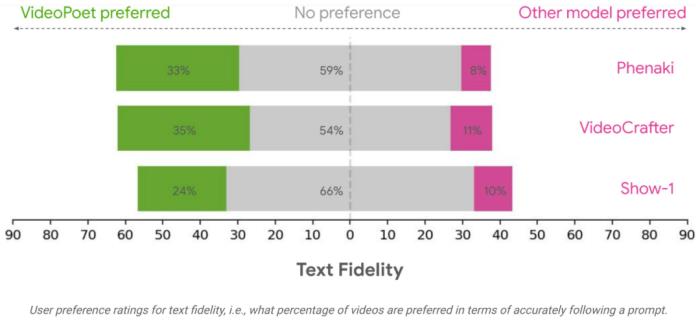
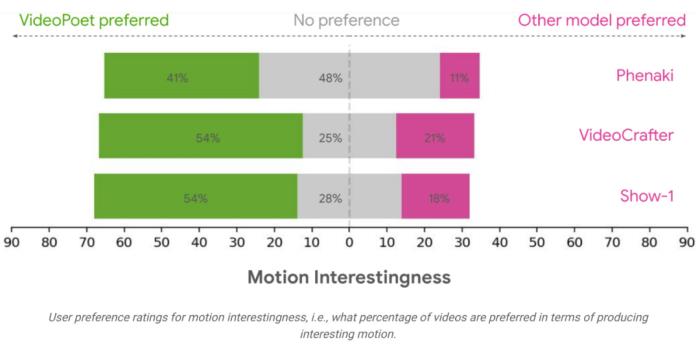
平均而言,在遵循 prompt 方面,人们认为 VideoPoet 中 24-35% 的示例比竞争模型更好,而竞争模型的这一比例为 8-11%。评分者还更喜欢 VideoPoet 中 41-54% 的示例,因为生成视频的动作更有趣,而其他模型的这一比例为 11-21%。


 新火种
2023-12-26
新火种
2023-12-26 
















