新火种 2023-11-30
新火种 2023-11-30 

秒出图!StabilityAI推出开源文生图大模型SDXLTurbo

图片来源:由无界 AI生成
图生文大模型技术再次卷起来,现在开始卷实时出图了。
11 月 28 日,开源大模型公司 Stability AI 正式发布了一种新的开源文生图模型 SDXL Turbo,并已发布在了 Hugging Face 平台上公开可用。用户输入提示词之后,该工具能够几乎实时生成图像。就目前的实测结果显示,图像生成质量有时候有些不足,但这种生成速度绝对颠覆目前市场上的所有产品,包括 Midjourney,DALL-E3等,带来更多想象空间。
SDXL Turbo 采用了被称为对抗扩散蒸馏 (Adversarial Diffusion Distillation,ADD) 的新技术,该技术使模型能够一步合成图像输出并生成实时文本到图像输出,同时保持高采样保真度。该技术的论文已经公开发布。不过,SDXL Turbo 目前还未开放商业使用。
研究论文地址:https://stability.ai/research/adversarial-diffusion-distillation
体验链接:http://clipdrop.co/stable-diffusion-turbo
Hugging Face 下载链接:https://huggingface.co/stabilityai/sdxl-turbo
扩散模型取得新进展
SDXL Turbo 是 Stability AI 在扩散模型技术方面取得的新进展,它在 SDXL 1.0 的基础上进行迭代,并为文本到图像模型实现了一种新的蒸馏技术:对抗扩散蒸馏 (Adversarial Diffusion Distillation,ADD) 。 通过整合 ADD,SDXL Turbo 获得了与 GAN(生成对抗网络)共有的许多优势,例如单步图像输出,同时避免了其他蒸馏方法中常见的伪影或模糊。
什么是 ADD
ADD 是一种新的模型训练方法,只需 1-4 个步骤即可有效地对大规模基础图像扩散模型进行采样,同时保持高图像质量。 通过使用积分蒸馏来利用大规模现成的图像扩散模型作为一种教师信号,并结合对抗性损失,以确保即使在一两个采样步骤的低步骤状态下也能确保高图像保真度。 分析结果显示,这种方法明显优于现有的几步方法(GAN,潜在一致性模型),并且仅用四个步骤就达到了最先进的扩散模型(SDXL)的性能。 ADD 是第一种利用基础模型实现单步实时图像合成的方法。
与其他扩散模型相比的性能优势
扩散模型在合成和编辑高分辨率图像和视频方面取得了显着的性能,但其迭代性质阻碍了实时应用。
潜在扩散模型试图通过在计算上更可行的潜在空间中表示图像来解决这个问题,但它们仍然依赖于具有数十亿参数的大型模型的迭代应用。
除了利用更快的采样器进行扩散模型之外,关于模型蒸馏的研究也越来越多,例如渐进蒸馏和引导蒸馏。 这些方法将迭代采样步骤的数量减少到 4-8 个,但可能会显着降低原始性能。 此外,它们需要迭代训练过程。 一致性模型通过在 ODE 轨迹上实施一致性正则化来解决后一个问题,并在少样本设置中展示了基于像素的模型的强大性能。 LCM 专注于提取潜在扩散模型,并在 4 个采样步骤中实现令人印象深刻的性能。 最近,LCM-LoRA 引入了低秩自适应训练,用于高效学习 LCM 模块,可以插入 SD 和 SDXL 的不同检查点。 InstaFlow 建议使用整流流来促进更好的蒸馏过程。
所有这些方法都有共同的缺陷:在四个步骤中合成的样本通常看起来模糊并表现出明显的伪影。 如果采样步骤较少,这个问题就会进一步放大。 GAN 也可以被训练为用于文本到图像合成的独立单步模型。 它们的采样速度令人印象深刻,但性能落后于基于扩散的模型。在某种程度上,这可以归因于稳定训练对抗目标所需的精细平衡的 GAN 特定架构。 在不破坏平衡的情况下扩展这些模型并集成神经网络架构的进步是众所周知的挑战。
此外,当前最先进的文本到图像 GAN 没有像无分类器指导这样的方法,这对于大规模的 DM 至关重要。
方法
我们的目标是以尽可能少的采样步骤生成高保真样本,同时匹配最先进模型的质量。 对抗性目标自然有助于快速生成,因为它训练一个模型,该模型在单个前向步骤中输出图像流形上的样本。 然而,尝试将 GAN 扩展到大型数据集时发现,不仅要依赖判别器,还要采用预训练的分类器或 CLIP 网络来改善文本对齐。 正如中所述,过度利用判别网络会引入伪影,并且图像质量会受到影响。 相反,我们通过分数蒸馏目标利用预训练扩散模型的梯度来提高文本对齐和样本质量。 此外,我们不是从头开始训练,而是使用预训练的扩散模型权重来初始化模型; 众所周知,预训练生成器网络可以显着改善对抗性损失的训练。 最后,我们采用了标准扩散模型框架,而不是利用用于 GAN 训练的纯解码器架构。 这种设置自然可以实现迭代细化。

采样步骤的定性效果。 我们展示了使用 1、2 和 4 步对 ADD-XL 进行采样时的定性示例。 单步采样通常已经是高质量了,但增加步骤数可以进一步提高一致性(例如第二个提示,第一列的效果,明显 4 步要比 1 步强很多)和对细节的关注(例如第二个提示,第二列的效果,同样 4步更强)。 每一列中的种子是恒定的,我们看到总体布局在采样步骤中得到保留,允许快速探索输出,同时保留细化的可能性。
为了选择 SDXL Turbo,研究团队通过使用相同的提示词生成输出来比较多个不同的模型变体(StyleGAN-T++、OpenMUSE、IF-XL、SDXL 和 LCM-XL)。 然后,人类评估者会随机看到两个输出,并被要求选择最符合提示方向的输出。 接下来,用相同的方法完成图像质量的附加测试。 在这些盲测中,SDXL Turbo 能够以一步击败 LCM-XL 的 4 步配置,并且仅用 4 步击败 SDXL 的 50 步配置。 通过这些结果,我们可以看到 SDXL Turbo 的性能优于最先进的多步模型,其计算要求显着降低,而无需牺牲图像质量。
为了选择 SDXL Turbo,我们通过使用相同的提示生成输出来比较多个不同的模型变体(StyleGAN-T++、OpenMUSE、IF-XL、SDXL 和 LCM-XL)。 然后,人类评估者会随机看到两个输出,并被要求选择最符合提示方向的输出。 接下来,用相同的方法完成图像质量的附加测试。 在这些盲测中,SDXL Turbo 能够以一步击败 LCM-XL 的 4 步配置,并且仅用 4 步击败 SDXL 的 50 步配置。 通过这些结果,我们可以看到 SDXL Turbo 的性能优于最先进的多步模型,其计算要求显着降低,而无需牺牲图像质量。
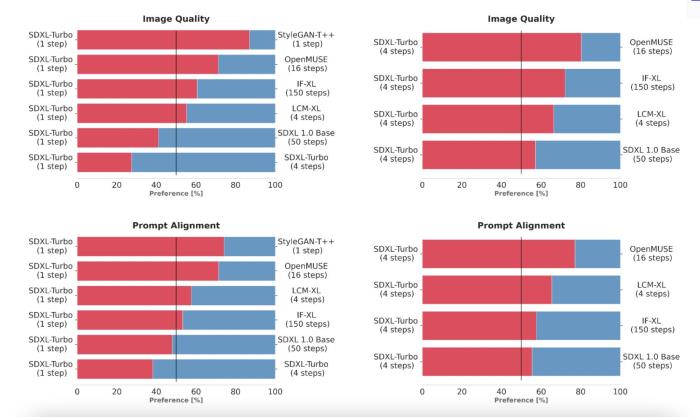
用户偏好研究(单步)。 将 ADD-XL(1 步)的性能与既定基线进行比较。 在人类对图像质量和即时对齐的偏好方面,ADD-XL 模型优于除 SDXL 之外的所有模型。 使用更多的采样步骤进一步改进了我们的模型(底行)。
接近实时的速度
社区用户已经开始上手体验 SDXL Turbo,效果让人惊叹。有用户使用消费级 4060TI 显卡运行该大模型,能够以 0.3 秒/张的速度生成 512x512的图像。这种几十倍的速度提升,正在给创作者带来了新的想象空间。
链接:https://twitter.com/hylarucoder/status/1729670368409903420
SDXL Turbo 速度之快甚至能够让用户边输入提示词边生成图像。用户还扩展了功能,可以增加参考图来生成图片。
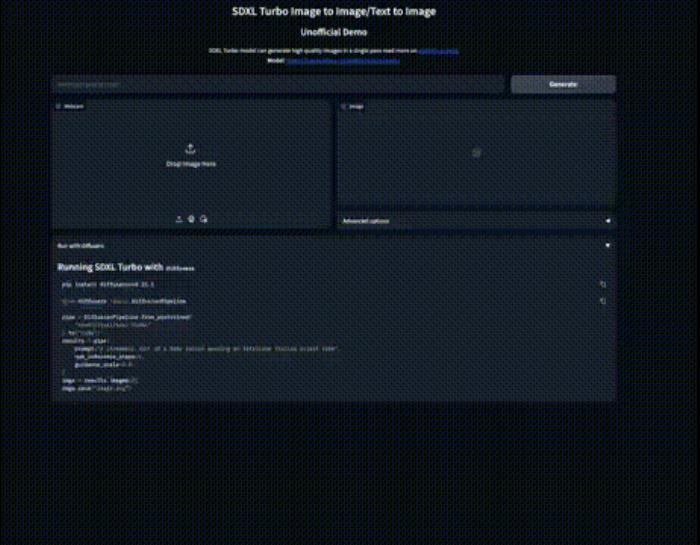
用户设计的体验地址:https://huggingface.co/spaces/diffusers/unofficial-SDXL-Turbo-i2i-t2i
此外,SDXL Turbo 还显着提高了推理速度。 通过使用 A100 AI芯片,SDXL Turbo 可以在 207 毫秒内生成 512x512 图像(即时编码 + 单个去噪步骤 + 解码,fp16),其中单个 UNet 前向评估占用了 67 毫秒。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章