新火种
2023-11-28
新火种
2023-11-28 


语音识别全新的端到端模型结构,百度发布技术重要进展SMLTA2
10月15至18日,2021年第十六届全国人机语音通讯学术会议(NCMMSC2021)在江苏徐州举行。作为我国人机语音通讯领域研究中最具有权威性的学术会议之一,NCMMSC受到国内语音领域广大专家、学者和科研工作者的关注。
其中,百度语音团队对外重磅发布基于历史信息抽象的流式截断conformer建模技术——SMLTA2,解决了Transformer模型用于在线语音识别任务中面临的问题,引发瞩目。
自2012年以来,百度语音识别技术一直不断深入探索、创新突破,引领着行业发展的技术路径。2018年,百度语音发布的Deep Peak 2模型突破了沿用十几年的传统模型,大幅提升各场景下识别准确率。2019年初,百度语音技术团队公布在线语音领域全球首创的流式多级的截断注意力模型SMLTA(Streaming Multi-Layer Truncated Attention), 相对准确率提升15%。如今,随着SMLTA2的发布,百度语音实现了在线语音识别历史上的又一次重大突破。
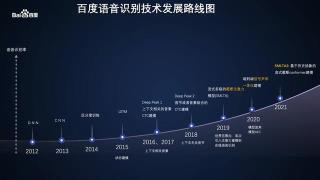
百度语音识别技术发展路线图
Transformer模型用于 在线语音识别 领域 的三大障碍
人工智能的终极目标是让机器具备人类智慧,帮助人类实现各种任务的分析和决策。近年来,随着深度学习技术的不断发展,特别是Transformer模型结构的提出,为通用人工智能技术的实现指出了一种可行的方向。OpenAI的研究人员根据Transformer模型的特点,提出了一种预训练语言模型(Generative Pre-trained Transformer,GPT)。通过不断提升模型的容量和数据的规模,GPT模型从GPT-1逐步迭代到GPT-3,模型的能力也在稳定提升。在特定任务上,GPT-3模型的性能已经接近甚至超过了人类的平均水平。Transformer模型在NLP领域的成功应用,显示出Transformer模型结构的建模潜力,激发了研究人员把该模型用于诸如语音识别和图像识别等领域的巨大热情。但是到目前为止,还没有看到Transformer结构在在线语音识别系统的成功应用。
在线语音识别任务相比文本任务有其独有的特点。从输入数据的长度上看,文本数据的长度一般在几十到几百之间,而语音数据的长度经常是在一千帧以上。对于一些重要的长语音识别任务,音频数据的长度甚至达到了一万帧以上。区别于LSTM模型的逐帧递推机制,Transformer模型的核心采用self-attention(自相关)的机制。由于语音识别任务的语音长度远远长于文本任务的字数,使得以自相关操作为基础的Transformer模型在用于在线语音识别时,存在如下难以逾越的障碍:
“计算爆炸”问题。 由于Transformer模型的Encoder各层都需要做自相关。从理论上说,在中间语音识别结果需要实时展现的场合,这个自相关操作随着每一帧新的语音信息的输入,需要和全部历史输入的语音帧进行自相关运算。面对超长的音频数据,每次输入都循环往复的进行自相关运算,极大地消耗了系统的计算资源。
“存储爆炸”问题。 由于Transformer模型的Encoder的每一层都需要保留整句话的特征编码后,才能进行后续网络层中做自相关操作。为了把网络做的更深更大,通常会引入残差结构。在这种情况下,保留神经网络各层输入就成为训练和解码时候必须的要求。而随着网络层数的加深,网络隐层维度的增大以及语音长度的增加,对训练和解码时的显存消耗造成巨大压力。
“焦点丢失”问题。 超长的音频数据大大增加了Transformer模型的建模难度。区别于NLP任务,语音任务的特点是很短的声音信息夹杂在较长的背景噪音或者静音中。这些语音中的噪音或者静音虽然不包含语言信息,但是会干扰注意力机制,导致注意力难以聚焦到有效的包含语言信息的声音特征上,最终影响系统的建模精度。
此外,在线语音识别服务还需要流式解码。也就是说在语音输入的同时就要启动音频解码,话音一落立刻就能拿到整句的识别结果。而且在说话的过程中,屏幕上实时显示语音识别的中间文字。如果等音频完全输入后才开始解码,会延长用户的等待时间,而且看不到输入的中间文字,严重影响用户的使用体验。
百度于2019年初在业界首先提出的流式多级截断注意力SMLTA模型,成功解决了端到端注意力模型的流式建模问题。SMLTA1主要采用的是LSTM模型结构。LSTM模型的时序递推的方式造成了该模型在建模能力和训练效率上都弱于Transformer模型。但是,Transformer模型应用于在线流式语音识别任务时,需要同时解决流式解码和上述 “计算爆炸”、“存储爆炸”以及“焦点丢失”三大问题。
百度语音新突破:基于历史信息抽象的流式截断conformer建模
通过对Transformer模型的深入研究,百度的研究人员在SMLTA1的基础上,进一步提出了基于历史特征抽象的流式语音识别建模方法SMLTA2。SMLTA2模型不仅保留了SMLTA1流式、多级、截断的特点,还通过引入基于Attention的历史特征抽象以及从Decoder到Encoder各层的注意力机制,解决了Transformer模型用于在线语音识别任务中面临的问题。其核心结构和历史特征抽象的原理如下图所示。
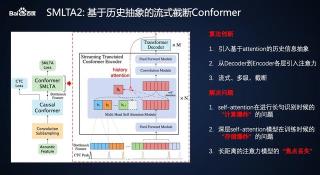
SMLTA2 模型结构和历史特征抽象原理
由于卷积增强(Convolution Augmented)的Conformer模型同时具有Transformer模型的全局建模和卷积模型的局部建模的能力,SMLTA2采用Conformer模型作为其主要结构。从图中可以看到,SMLTA2首先根据CTC模型的尖峰信息对连续语音特征进行截断,然后在截断的特征片段上利用Conformer Encoder对输入特征逐层编码,最后使用Transformer Decoder得到相应的识别结果。在对当前建模单元编码时,历史的语音特征片段被逐层抽象成固定长度的特征向量,然后和当前的语音特征片段一起进行注意力建模。这里的历史特征抽象是指根据Decoder输出的隐含特征对当前语音特征片段的Encoder各层进行相关性建模。
通过CTC特征截断和历史特征抽象的方式,SMLTA2在保证建模精度的同时,克服了传统Transformer模型在长音频识别上面临的“计算爆炸”和“存储爆炸”问题。并且通过流式动态截断的方式,把注意力缩小到一个合适的范围,进一步解决了Transformer模型在语音识别任务的“焦点丢失”问题。
为了解决Transformer模型应用于流式语音识别任务的各种问题,其他研究学者采用对Encoder各层进行启发式的截断和抽象。Google的Transformer Transducer模型对Encoder的上下文限制了固定长度范围,可以看作在输入特征上进行加窗截断的方法。Facebook的记忆增广(Augmented Memory)方法把音频特征切分为等长的片段,然后通过平均池化等方法得到固定长度的向量。这种截断和抽象是先验进行的,最终的识别结果无法反馈信息给这种截断和抽象过程。而且在此基础上得到的特征向量只是一种数学上的简化,其本身并没有实际的物理含义。SMLTA2通过特征抽象得到的特征向量对应着一个输出的文字信息。这些特征向量拼接起来组成的历史特征向量,实际上形成了一种声学特征层面的语言模型,进而有效提升SMLTA2模型的建模能力。
目前几乎所有的基于Encoder-Decoder结构的端到端模型在建模时,Encoder和Decoder之间的关系是Encoder的输出是Decoder的输入,Decoder的解码过程并不和Encoder内部各层的编码信息发生任何联系。Decoder只能在端到端联合建模的训练过程,通过误差传递的方式间接地影响Encoder的编码过程。尽管这种传统的Encoder-Decoder协同工作的方式更简单,但是却存在Decoder对Encoder内部各层信息的反馈和使用不够直接的问题。
通过前文分析,Transformer模型应用于语音识别领域,必须对历史信息进行必要的截断和近似。如果不引入从Decoder到Encoder各层的反馈机制,而简单武断地对Encoder的各层信息进行截断或者近似,难免发生信息丢失,影响建模能力。SMLTA2通过Decoder到Encoder各层的注意力特征选择机制来引入反馈,使得最外层识别结果信息可以直接作用于编码器内部的每一层的编码过程,通过历史信息抽象充分提取有效特征信息,显著改善了Transformer模型从NLP领域应用到语音识别领域面临的各种问题。SMLTA2的这种全新的端到端建模方法,是对传统Encoder-Decoder结构的端到端建模的结构性创新。
语音识别模型的迭代 和工业化落地
从基于 LSTM 和 CTC 的上下文无关音素组合建模Deep Peak 2到流式多级截断注意力SMLTA1,再到基于历史特征抽象的流式语音识别建模SMLTA2,百度一直坚持在语音识别模型上的创新迭代。
多年来,百度语音不仅在技术路线上持续引领行业,还一直坚持在产品上可使用、让用户真正可体验。百度的上一代流式多级的截断注意力模型SMLTA1就成功上线语音输入法全线产品,服务中国数亿用户,是世界范围内已知的第一次大规模部署的用于在线语音输入的注意力模型。
此次发布的SMLTA2依旧保持了流式识别的特点,具备工业产品落地的能力。目前在实验室内,模拟线上环境进行测试,SMLTA2在同等计算资源消耗的情况下,相对于上一代技术错误率降低大约12%。SMLTA2的提出,是百度在语音识别领域的又一技术突破,也是百度AI技术继续领跑行业的重要技术创新。期待SMLTA2的产品上线应用,实现语音识别准确率的再度提升,给用户带来全新的交互体验。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章