新火种
2023-11-28
新火种
2023-11-28 


GPT成熟之路官方笔记|OpenAI开发者日
ChatGPT产品打造的细节,现在OpenAI自己交了个底。

并且这波干货分享真是信息量满满,包括但不限于:
ChatGPT背后的产品和研发团队如何协作大模型应用如何从原型走向成熟OpenAI如何优化大模型性能……
以上信息,依然来自今年的新晋“科技春晚”——OpenAI开发者日。
除了奥特曼惊艳全球的开幕演讲,当天还有更多分组讨论,视频也陆续被官方上传到了油管。
而这也算得上是OpenAI惊天抓马之前,其团队“内幕”的一次展示。
值得借鉴学习之处,我们已经整理好笔记,一起来看~
产品与研究团队合作“前所未有”把时间拉回到2022年10月,OpenAI的研究团队和产品团队开始围绕一个idea进行讨论:为他们的基础大模型,制作一个对话界面。
彼时还处在ChatGPT的早期阶段,但研究团队和产品团队的紧密协作已然开始,它们之间相互的影响程度更是独树一帜。
或许这种团队合作模式,可以成为其他公司参考借鉴的样本。
用OpenAI模型行为产品负责人Joanne Jang的话说:
ChatGPT本身,就是最明显的例子。
OpenAI Post-Training团队负责人Barret Zoph和Joanne共同分享了两支团队在ChatGPT开发和完善过程中的一些协作细节。
Barret团队的主要职责,是在模型能力被加入到ChatGPT和API之前,对其进行调整。具体来说,ChatGPT后期增加的联网、分析文件等功能,都是由Post-Training团队负责的。
Barret重点提到的是,正是产品团队的种种设计,让研究团队能够及时get到什么样的模型响应,对于现实世界中的用户和开发人员是真正有用的。
比如ChatGPT的点赞点踩按钮,就给研究本身带来了很多价值:

而站在产品团队的角度,Joanne同样认为,OpenAI产品经理扮演的角色有独特之处:
首先,在OpenAI做产品的目标不是收入、参与度、增长等传统产品指标,而是打造造福全人类的通用人工智能。
其次,OpenAI的产品经理往往是从技术而非用户问题的角度出发,去设计产品功能的。
最后,OpenAI研究团队和产品团队相互影响的程度非常之高,在业内可以说达到了前所未有的程度。

还是以ChatGPT诞生的过程为例。从GPT-3,到InstructGPT,再到ChatGPT,研究团队发现,直接在多轮对话上训练模型,能让教导模型新的行为这件事变得更加有效。
而具体教导(设计)模型行为的工作,就是靠产品团队来参与完成的:比如说,当用户告诉ChatGPT“你现在是一只猫”,ChatGPT应该表现出怎样的默认行为?
产品团队对此进行了大量的实验,以找出适合大多数用户的默认模式。
(p.s. 不过Joanne也提到,对于用户而言,最好的模型是个性化的模型,这也是他们对未来大模型发展方向的预判之一。)
非线性策略优化大模型性能讲完协同“内幕”,再来看技术细节。
在开发者日上,OpenAI的技术人员分享了GPT-4中使用的大模型优化技术。
划重点就是,采用非线性策略,具体包括两个维度和四个象限。
OpenAI提出了一个多层次的非线性优化框架,涉及到了提示工程、搜索增强生成(RAG)和微调这三种技术。
传统的模型优化方式往往以线性方式运用这三项技术,在OpenAI看来这种模式无法解决“真正需要解决的问题”。

OpenAI认为,大模型表现优化分为两个维度,一个是其本身的表现,一个是上下文。
根据这两个维度需求程度的不同,就形成了四个象限。
具体来说,这两个优化方向的起点都是提示工程,但接下来要用RAG还是微调(或两者兼用)则需要根据实际情况来选择。
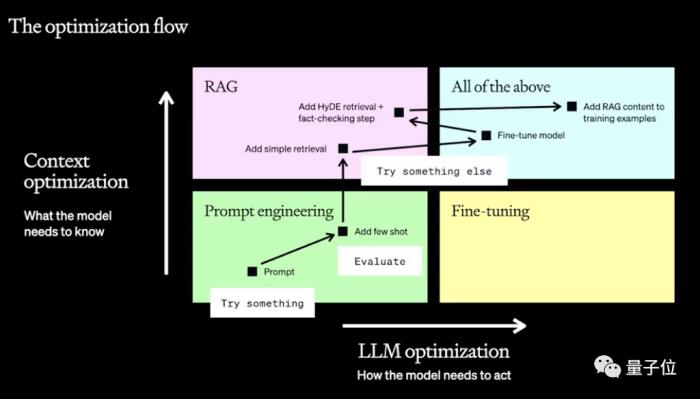
通过详细比较这三项技术各自的优势,OpenAI的两名技术人员分别做了具体解释。
首先是提示工程,它被看作大模型优化的起始点,通过设计提示词来增强模型性能,可以测试和快速迭代。
具体的策略包括,将提示词设计得更清晰、将复杂任务拆解,以及提供示例文本或调用外部工具等。

但对于让模型学习新信息,或者复刻一种复杂的方法(如学习新的编程语言),则超出了提示工程的能力范畴。
此外,任务的细化也会带来token的增加,所以提示工程对于减少token消耗来说也是不利的。

RAG和微调解决的问题则存在一些相似之处,二者的主要区别在于,RAG更适用于让模型从给定信息中获取答案(短期记忆),而微调的重点是模型的长期记忆。
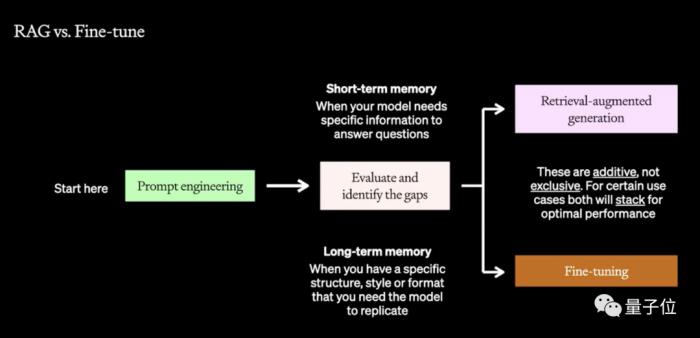
RAG的核心优势是利用知识库为模型提供上下文信息,从而减少模型幻觉。
但是这种知识信息通常局限于十分具体的领域,但对于宽泛的领域(如“法律”“医学”等)作用并不明显。
同时,提供大量上下文信息会带来比提示工程更多的token消耗,对节约token同样不利。

此外,过度应用RAG也有可能带来反效果,比如有用户要求GPT只利用文档中的信息,然后发现模型出现了“幻觉”。
但事后分析发现,这并非是模型的幻觉现象,而是用户提供的信息本身就存在错误。

而微调则是通过在小数据集上训练模型,来提高性能和效率,或者修改输出结构。
相比RAG,微调更侧重于强调模型已有的知识,并提供复杂的任务指导,对于学习新知识或迭代到新用例则不是好的选择。

总结下来就是,基于这些策略的特点和使用领域,根据实际需求有的放矢地选择优化策略。
这也是OpenAI调教GPT-4的法宝,具体到应用层面,OpenAI也为一众创业者献上了一份大礼。
为创业者送上“大礼包”OpenAI工程负责人和Applied团队成员分享了如何将基于OpenAI模型搭建的应用从原型走向完整产品。
如果你也有兴趣基于OpenAI的API搞一些应用创新,以下是官方分享的一些工程实践经验:
第一,打造以人为本的用户体验,即减少模型不确定性,增强模型的安全性和可控性。
第二,提供一致性体验。比如利用知识库等工具来减少模型的不一致性。工程师们提到,OpenAI通过控制seed来控制结果的可重现性,并且提供了当前系统的“指纹”来代表整个系统的状态。
第三,重视性能评估。并且OpenAI发现,用大模型来代替人工进行性能评估效果显著。
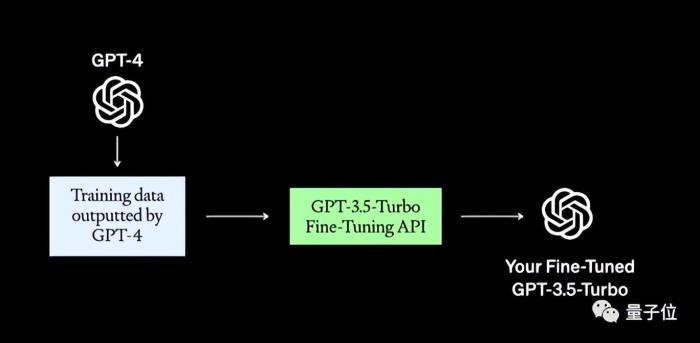
第四,管理延迟和成本。主要策略有两种:首先是加入语义缓存,来减少真实API的访问;其次是使用更便宜的模型,比如不直接使用GPT-4,而是用GPT-4的输出来微调GPT-3.5 Turbo。
而具体到产品更新,新版API也值得关注,OpenAI的广告词是可以“在开发的应用中直接构建世界级的助手”。
新版API支持调用代码解释器和外部知识,OpenAI的API工程主管Michelle进行了现场演示。
此外,在函数(第三方API)调用方面也进行了改进,新增了JSON输出模式,并允许同时调用多个函数。
One More Thing顺便提一嘴,开发者大会的开幕式上,OpenAI现场给每个人发放了500美元的账户余额,让线下观众纷纷投来羡慕的目光。
不过实际上他们只赚了50,因为还要花450美元买门票。
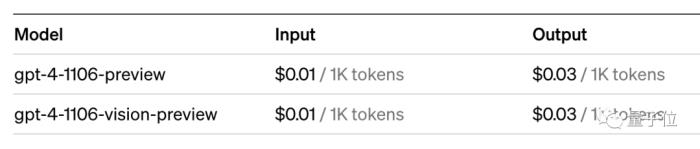
按照最新的定价,50美元可以通过API处理500万输入token或166.6万输出token。
那么,今日份的干货笔记就分享到这里了,想了解更多详细内容,可以到官方回放中一睹为快。
— 完 —
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章