新火种
2023-11-18
新火种
2023-11-18 


大幅降低GPU算力闲置率,Enfabrica获NVIDIA参投的1.25亿美元融资
原文来源:阿尔法公社

图片来源:由无界 AI生成
算力不足是目前整个AI行业都在面对的问题,就在上周OpenAI的Devday后,由于一系列新功能吸引了大量用户试用,ChatGPT和GPT的API出现了大范围长时间的宕机,而Sam Altman也宣布暂停Plus新会员的注册。
目前在AI算力领域,NVIDIA的GPU占据近乎垄断的地位,无论是A100,H100还是刚刚发布的H200,都是AI算力芯片的标杆,但是它的GPU面临一个问题:布署于数据中心的显卡算力集群,会因为连接网络无法足够快速地提供数据,在部分时间无法满负载运行,从而造成算力的浪费,进而推高总拥有成本(TCO)。
而一家叫Enfabrica的初创公司,利用专为人工智能数据中心开发的网络芯片,可以使GPU性能节点的算力利用率提升50%,降低AI推理和训练的算力成本。
近日,Enfabrica完成了由Atreides Management领投,NVIDIA作为战略投资人参投的1.25亿美元B轮融资,其他参与本轮融资的投资者包括IAG Capital Partners、Liberty Global Ventures、Valor Equity Partners、Infinitum Partners和Alumni Ventures,它的早期投资者Sutter Hill Ventures也继续加磅。
这一轮融资使公司估值较前一轮增长了5倍以上,使其累计融资达到1.48亿美元。Atreides Management的创始人Gavin Baker加入董事会,以协助公司的发展和战略方向。
瞄准AI算力领域的重大挑战,两位芯片领域资深人士联手创业
根据650集团(专注云计算供应链的研究机构)最新市场研究,AI/ML计算需求的规模可能会在每24个月内增长8到275倍,在未来十年的时间里,基于AI/ML的服务器将从市场的1%增长到近20%。
但是,因为AI计算的特点,数据和元数据在分布式计算元素之间的大量移动形成了瓶颈。SemiAnalysis的分析师Dylan Patel指出:每一代芯片/封装的浮点运算能力(FLOPs)的增长速度都超过数据输入输出速度。而且这种不匹配正变得越来越严重。
Enfabrica由Rochan Sankar和Shrijeet Mukherjee联手创建。Rochan Sankar曾是芯片巨头博通的工程总监,Shrijeet Mukherjee曾在谷歌负责网络平台和架构,他们对于芯片和网络架构有深刻的理解和丰富的经验。

在组织架构上,Sankar担任首席执行官,Mukherjee担任首席开发官,Enfabrica核心团队包括来自思科、Meta和英特尔等公司AI,网络,芯片领域的资深工程师。
Enfabrica瞄准的是AI行业对“并行、加速和异构”基础算力设施(也就是GPU)的增长需求。
Rochan Sankar表示:“当前AI革命带来的最大挑战是AI基础设施的扩展—无论是计算成本还是计算的可持续性。
传统的网络芯片,如交换机,在跟上现代AI工作负载的数据移动需求方面存在困难,这会对在训练过程中需要大量数据集的AI训练或AI微调等计算需求造成瓶颈。
AI计算领域迫切需要弥合不断增长的AI工作负载需求与计算集群的总体成本、效率、可持续性和扩展便利性之间的差距。”
Enfabrica推出了加速计算结构交换机(ACF-S)设备和解决方案,这些解决方案与GPU、CPU和加速器相辅相成,能够解决数据中心AI和高性能计算集群中的关键网络、I/O和内存扩展问题。它能使数据中心GPU和加速计算集群的计算成本降低50%,内存扩展50倍,并且在相同的性能点上将大模型推理的计算成本降低约50%,实现了总拥有成本(TCO)的降低。
根据Dell’Oro Group的数据,AI基础设施投资将使数据中心资本支出在2027年前超过5000亿美元。同时,根据IDC的预测,广义上针对AI的硬件投资在未来五年内预计将有20.5%的复合年增长率。
预计到2027年,数据中心用的互联半导体市场规模将从2022年的近125亿美元翻倍至近250亿美元。
加入Enfabrica董事会的Gavin Baker是Atreides Management的首席信息官兼管理合伙人,它曾经投资了Nutanix、Jet.com、AppNexus、Dataminr、Cloudflare和SpaceX等公司,并且担任部分公司的董事会成员。
在谈到AI的算力基础设施时,他谈到了几个重要的改进方面:“通过更快的存储、更好的后端网络(尤其是Enfabrica),以及现在正在出现的线性可插拔/共封装光学器件和改进的CPU/GPU集成(NVIDIA的GraceHopper、AMD的MI300和特斯拉的Dojo)来提高GPU利用率,这些结合在一起打破了“内存墙”,将进一步提高训练的投资回报率——既直接降低了训练成本,也间接地通过以下方式增加了利润率降低推理成本。
总结来说,在“每单位能量有用计算”具有优势的架构将获胜,我们正在快速朝着每单位能量更有用的计算迈进。”
帮助NVIDIA GPU计算集群打破“内存墙”
在AI加速计算领域,“内存壁垒”是一个实际存在的问题,它指的是处理性能与提供这种性能所需的内存带宽之间日益扩大的差距。
相对于传统CPU计算,AI普遍使用的GPU计算在这个方面表现得更严重,因为GPU拥有更多的核心,更高的处理吞吐量,以及对数据的巨大需求。
AI使用的数据必须首先被组织和存储在内存中,然后才能由GPU处理。为AI提供必要的内存带宽和容量是一个当前急需解决的问题。
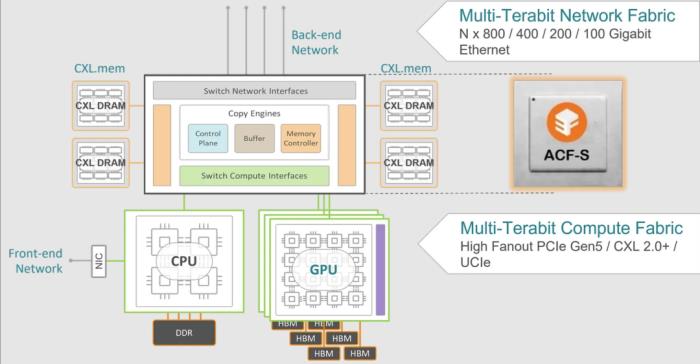
为了解决这个问题,已经有几个关键技术可以利用:之前已经在CPU和分布式集群计算中使用的内存性能/容量分层和缓存架构;支持扩展AI系统的远程直接内存访问(RDMA)网络技术;以及业界广泛认可和采用的Compute Express Link(CXL)接口标准。
Enfabrica的方案融合了CXL.mem解耦、性能/容量分层和RDMA网络等关键技术,实现了一个可扩展的、高带宽、高容量、延迟有界的内存层次结构,为任何大规模AI计算集群提供服务。
它的第一款芯片叫做ACF (Accelerated Compute Fabric)转换芯片,它能够让GPU算力池与数十TB的本地CXL.mem DRAM池直接连接,延迟极低。
具体来说,ACF进一步推动了内存分层构造,通过800GbE网络端口,实现对分布在计算集群和数据中心其余部分的PB级DRAM的高带宽访问。进而为加速计算构建一个具有近内存、近远内存、网络远内存,并在每个内存层次上都有严格延迟限制的层次化数据存储。通过ACF的帮助,执行数据处理的NVIDIA GPU能够从多个不同的地方提取数据,而不会遇到速度障碍。
Enfabrica的解决方案叫ACF-S,它由多个ACF芯片组成,具有8-Tbps人工智能基础设施网络节点,具有800G以太网、PCIe第5代和CXL 2.0+接口,与NVIDIA DGX-H100系统和Meta Grand Teton搭载八个NVIDIA H100 GPU的系统相比,它可以将I/O功耗降低高达50%(每机架节省2千瓦)。

“ACF-S是一种融合解决方案,它消除了对传统的、各不相同的服务器I/O和网络芯片的需求,如架级网络交换机、服务器网络接口控制器和PCIe交换机的需求。”Rochan Sankar解释道。

ACF-S设备能够让处理AI推理任务的公司使用尽可能少的GPU、CPU和其他AI加速器。这是因为ACF-S能够通过快速移动大量数据,更有效地利用现有硬件。
而且,Enfabrica的解决方案不仅可以用于大规模AI推理,也适用于AI训练,以及数据库和网格计算等非AI用例。
Enfabrica计划向系统构建者(云厂商,数据中心运营商)销售芯片和解决方案,而不是自己构建系统。Sankar透露,Enfabrica与NVIDIA生态系统具有较深的契合度,但是他们也计划与更多不同的AI算力公司合作。
他说:“ACF-S对用于AI计算的AI处理器的类型和品牌,以及部署的确切模型都持中立态度,这允许构建跨多个不同用例的AI基础设施,并支持多个处理器供应商,无需专有技术锁定。”
速度更快,能耗更低,新一代AI算力体系正在成型
H100刚刚出货一年时间,NVIDIA就推出了H200,这显示出它维护自己在AI算力领域领先地位的急迫。因为过去一年的生成式AI大爆发,它的竞争对手们也都推出了强力的AI算力产品,无论是AMD的MI300系列芯片还是微软推出的对标H100的Maia芯片。
AI算力是一个技术集中和资金集中的产业,面对巨头们的“神仙打架”,AI算力创业公司们如何生存?Enfabrica和此前我们介绍过的d-Matrix给出了自己的答案。
d-Matrix的做法是专注在AI推理上,推出的AI推理专用芯片比NVIDIA的同类产品更快更省电。Enfabrica却没有去直接“抢NVIDIA的饭碗”,而是作为AI算力体系的一个重要部分,帮助NVIDIA的GPU(以及其他AI算力芯片)打破“内存墙”,减少算力闲置,整体上提高算力系统的利用率。
AI算力系统与所有算力系统一样,有两个重要的因素,速度和能耗。尽管大型的AI计算(无论是训练还是推理)都由算力集群来运行,但是更快的运算速度和更低的能耗仍然是行业整体的努力方向。
NVIDIA的GPU在更快的运算速度这个方向上优势明显,而Enfabrica这样的公司则在往更低的能耗上努力。
正如Enfabrica的创始人Rochan Sankar所说:“要想让AI计算真正普及,成本曲线必须下降。关键在于GPU的算力是否得到更好,更高效的利用。”
显然,NVIDIA对于Enfabrica的投资也是基于这个逻辑,随着Enfabrica技术让NVIDIA的GPU算力利用率进一步提高,它在行业中的领先优势有望进一步稳固。
不过,面对这个显而易见又迫切的需求,行业中并不止Enfabrica一家在做,行业巨头思科也已经推出了Silicon One G200和G202系列AI网络硬件,博通也在这个领域耕耘。Enfabrica想要进一步成长,仍然面临着竞争。
如果说海外的AI行业已经面临着暂时的算力不足问题,那么中国的AI行业更要面对长期的AI算力不足问题,随着NIVDIA的GPU被进一步的限制,行业对本土的AI算力产品产生了强烈的需求。目前已经有华为,阿里,百度,摩尔线程,寒武纪等公司在AI算力领域发展,希望他们,以及更多的公司,能够帮助建立起中国自己的AI算力体系。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章