新火种
2023-11-03
新火种
2023-11-03 


英伟达推出定制版大模型ChipNeMo,专攻芯片设计

图片来源:由无界 AI生成
半导体芯片虽然体积微小,但其设计之难度在全世界都是极具挑战性的。昨天苹果的半小时发布会上,全新的M3系列就此亮相,虽然难免又被人说挤牙膏,但事实一再表明,即使是挤牙膏也不是人人都会的。对半导体芯片的设计与制造之难,可能比航空母舰更甚,虽然直观上看二者的体量完全不在一个水平线上。
在刚刚开幕的ICCAD 2023大会上,英伟达(NVIDIA)展示了用大模型测试芯片的能力,引发了外界的一片啧啧称奇。之前曾说过,一根头发的横截面就能容纳200万个晶体管,其精密可见一斑。在显微镜下,像M3这样的顶级产品,看起来就像是许多精心规划的街区组成的城市,数百亿个晶体管则连接在比头发丝还要细一万倍的街道上。为了建造这样一座数字街区,需要多个工程团队坚持不懈的合作努力,短则数月长则数年。其中有的小组负责确定芯片的整体架构,有的小组负责制作和放置各种超小型电路,还有的小组负责进行测试。每项工作都需要专门的方法、工具、软件程序和电脑编程语言。
最近,来自英伟达的研究团队开发了一种名为ChipNeMo的定制大模型,以自家内部数据为基础进行训练,用于生成和优化软件,并为人类设计师提供帮助。论文链接:https://research.nvidia.com/publication/2023-10_chipnemo-domain-adapted-llms-chip-design
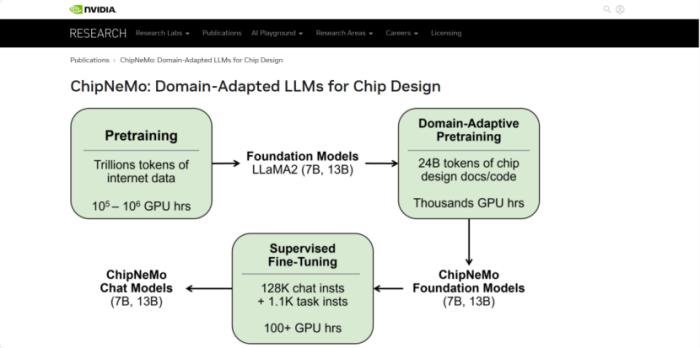
英伟达团队并没有直接部署现成的商业化或开源大模型,而是采用了以下领域适应技术:自定义分词器、领域自适应持续预训练(DAPT)、具有特定领域指令的监督微调(SFT),以及适应领域的检索模型。最终结果表明,与通用型基础大模型如700亿级参数的Llama 2相比,这些领域适应技术能够显著提高大模型的性能,不仅在一系列设计任务中实现了类似或更好的性能,而且还使大模型的规模缩小了许多,定制的ChipNeMo大模型是130亿参数级。
具体来说,英伟达团队在三种芯片设计应用中进行了评估:工程助理聊天AI、EDA代码生成,以及错误总结和分析。其中聊天AI可以回答各类关于GPU架构和设计的问题,并且帮助工程师快速找到了技术文档;代码生成器已经可以用芯片设计常用的两种专业语言,创建大约10到20行的代码片段了;而分析工具可以自动完成维护更新错误描述这一非常耗时耗力的任务。
对此,英伟达首席科学家Bill Dally(比尔·戴利)表示,即使只将生产力提高5%也是一个巨大的胜利,而ChipNeMo便是大模型在复杂的半导体设计领域,迈出了重要的第一步。这也意味着,对于高度专业化、精细化的领域,完全可以利用其内部数据来训练有用的AIGC大模型。
虽然参数量级更大的Llama 2也可能达到与ChipNeMo差不多的精度,但考虑较小的大模型及其附加的成本效益也同样重要。英伟达的ChipNeMo可以直接加载到单个A100 GPU的显存中,且无需任何量化,这就直接使得它的推理速度可以得到大幅提升。同时也有其他相关研究表明,参数量相对较小的大模型推理成本要比更大的大模型低几倍,甚至十几倍。
距今两个多世纪的第一次工业革命为世界带来了工业时代,最终以“机器可以制造机器”为结束的标志。如果以此类推,AI 2.0时代应该能实现“AI可以训练AI”。虽然听起来仍然遥不可及,但现在AI已经可以用于科研产业,特别是芯片制造这样的天花板级产业了,或许未来的曙光也就从此开始。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。