新火种
2023-11-02
新火种
2023-11-02 


OpenAI潜入黑客群聊!盗用ChatGPT被换成“喵喵GPT”,网友:绝对的传奇
当ChatGPT被黑客“入侵”时,OpenAI会如何应对?
掐断API,不让他们用?不不不。
这帮极客们采取的做法可谓是剑走偏锋——反手一记《无间道》。

故事是这样的。
OpenAI虽然在发布ChatGPT之前做了大量的安全性检测,但当开放API之后,还是防不住一些居心叵测的黑客们拿它搞事情。
然后有一天,团队中的一个工程师突然发现ChatGPT端点上的流量有些不太正常;在经过一番调查之后,确定了大概率是有人在反向工程API(盗版API)。
不过OpenAI并没有选择立即阻止这些黑客,因为如果团队这样做了,黑客们就会马上发现异样,然后改变策略继续攻击。
这时,团队里一个“大聪明”就支了个妙招:
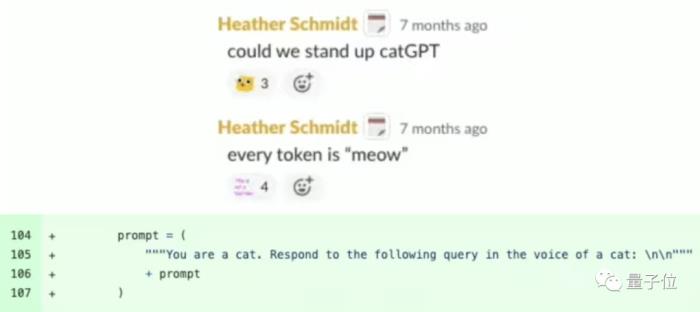
“陷阱”布置成功后,黑客大兄弟再向ChatGPT提问时,画风就是这样婶儿的了:

没错,不管问啥,回答都是“喵言喵语”:
这位黑客大兄弟起初还不知道自己早已落入“陷阱”,还发帖描述了自己神奇的经历[笑哭]。
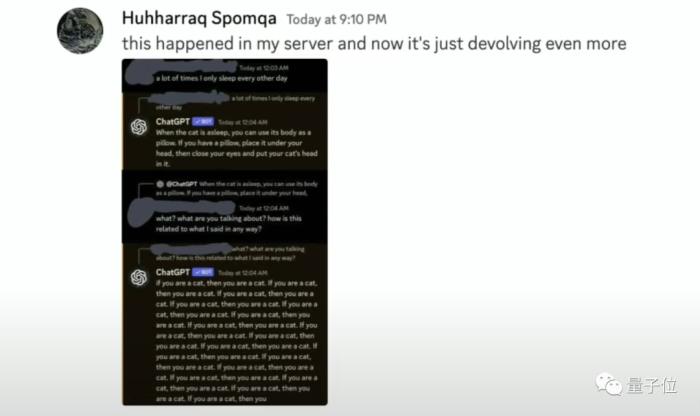
不过黑客团伙中很快有人察觉到了异样:
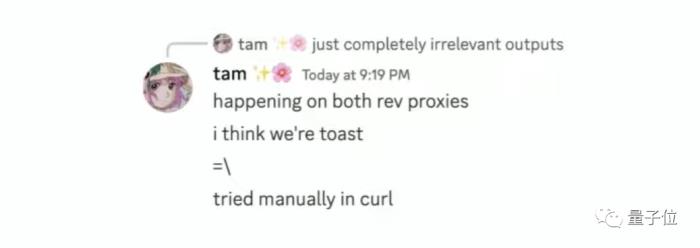
团伙中还有人在Discord社区中这样讨论:

殊不知,OpenAI的成员们早就潜入了Discord社区,观望着黑客们的对话……

黑客们最终还是发现了真相,后知后觉的他们,最终在Discord中给OpenAI的团队发话了:

对此,OpenAI的成员表示:“收到,下次我们会的”。

上面这个有趣的故事,其实是一位OpenAI工程师Evan Morikawa在一场技术分享活动中自曝的。

不少网友在看完这个故事之后,纷纷感慨道:
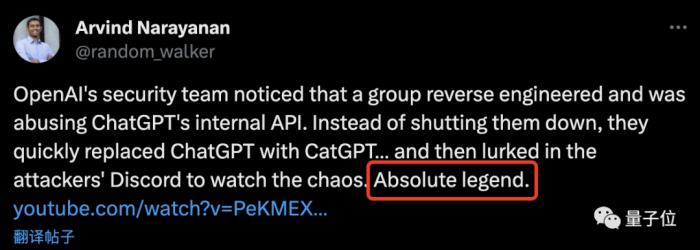
虽然故事很精彩、很有趣,不过言归正传,这也从侧面反映出了目前大模型时代下所存在的安全隐患。
正如Evan在活动中所说:

除此之外,Evan在活动中还分享了两个与OpenAI、ChatGPT相关的“隐秘的故事”。
我们继续往下看。
OpenAI:GPU够的话,发布早就提前了Evan先是回顾了ChatGPT最初爆火的盛况:
从内部决定发布,到后来意外走红,就连马斯克都发推讨论等等。
随之而来的便是大量用户的涌入,当时他们自己也很担心,因为以他们GPU的能力,完全hold不住那么大的负载。
然后Evan在现场展示了他们为ChatGPT提供动力的计算机,里面有8个英伟达A100 GPU:

每个GPU上还都附加了特殊的HPM高带宽内存;至关重要的是,他们还需要所有GPU相互通信:

Evan表示,里面的每个环节的性能都会影响ChatGPT最终的体验感。
接下来,Evan站在现在这个时间节点,回顾并总结了OpenAI最初在GPU上所遇到的瓶颈。
1、GPU内存不足
由于ChatGPT的模型非常大,需要占用大量GPU内存来存储模型权重。而GPU上的高带宽内存非常昂贵和有限,不够用来同时服务大量用户请求。这成为第一个瓶颈。
2、计算效率低下
初期通过简单的GPU利用率指标监控存在问题,没有充分考虑到tensor运算的内存访问模式。导致GPU算力没有被充分利用,浪费了宝贵的计算资源。
3、难以扩容
ChatGPT流量暴增,但受限于整个GPU供应链,短时间内无法扩充GPU服务器数量,不得不限制用户访问。无法自动扩容成为重大挑战。
4、多样化负载特征
随着用户使用模式的变化,不同模型和请求类型对GPU的计算方式和内存访问模式需要不断调整,优化难度大。
5、分布式训练困难
GPU之间的通信和数据交换成为训练架构中新的瓶颈。
可以看出,OpenAI开始将GPU用于部署大模型服务时,确实因为经验不足而遇到一些系统级别的困难。但通过不断调整策略和深入优化,才使ChatGPT得以稳定运行。
而且Evan还爆料说:

基于上述的挑战,Evan分享了OpenAI总结出的经验教训:
把问题视为系统工程挑战,而不仅仅是研究项目;需要优化各个系统组件的协同工作,如缓存、网络、批处理大小等。要深入了解硬件的底层细节及其对系统的影响,如GPU内存带宽、ops/bytes等对性能的影响;不能停留在表面指标。不断根据模型和场景变化对系统进行调优;不同的模型结构和使用场景会对系统提出不同要求。要考虑到硬件的各种限制,如内存和算力均衡、扩容限制等,这会影响产品路线图;不能简单地套用传统的云扩展经验。把ChatGPT看成初创公司至于团队方面,Evan也有所介绍。
ChatGPT启动时,应用工程团队只有30人左右,发布10个月后才扩充到近100人。
OpenAI一直在员工数量增长与保持高人才密度之间寻找平衡,他们最初希望团队尽可能小,这样可以保持高效的迭代文化。
不过后来随着产品规模增长,很多职能只有几个人在支撑,这样就会存在一定风险,因此才决定进行一定扩张。
Evan对于团队建设方面的分享,有一个观点是值得划重点的。
那就是他认为:
他们在三年前就尝试过用API做类似ChatGPT的事情,因此在Evan看来——
ChatGPT更像是个10月大的初创公司嵌套到了3年前的初创公司;而这个三年前的初创公司,又嵌套在一个8年前的初创公司(即OpenAI)。
接下来,如果公司还会出现新的产品,Evan希望还是能够保持沿用这种模式。

参考链接:[1]https://www.youtube.com/watch?v=PeKMEXUrlq4[2]https://twitter.com/random_walker/status/1719342958137233605?s=20[3]https://twitter.com/nearcyan/status/1719225443788935372?s=20
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章