一文详解多模态技术在 QQ 浏览器视频搜索上的实践经验。
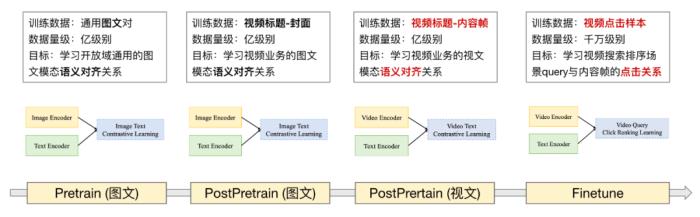
引言视频搜索作为搜索中最大的横向垂类,在约 50% 的搜索词下都会有视频结果的展现。然而,视频资源又不同于文本网页资源,在视频理解、视频匹配排序,以及交互行为等方面都会带来新的技术挑战。多模态技术近年逐步走进人们的视野,特别是 Transformer 结构在 NLP 领域的大放异彩后,也向视觉、音频等多模态领域延伸,为跨模态融合带来更大的便利和可能。多模态预训练(比如 ViLBERT/VisualBERT/VL-BERT/ERNIE-ViL 等)、多模态融合技术(比如基于矩阵、基于普通 NN、基于 attention 等)、多模态对齐技术、对比学习技术(如 CLIP)的发展,也为视频搜索业务效果的快速提升带来了可能。作为一款每天服务千万人的工具,腾讯 QQ 浏览器的搜索功能承担着重要角色。伴随着过去几年的视频生产 / 消费的趋势,人们也在习惯消费视频,搜索视频。本文作者来自腾讯搜索应用部,旨在分享多模态技术在 QQ 浏览器视频搜索上的实践经验。包括:多模态技术在视频搜索整个架构中的逻辑位置,以及其中的技术难点;介绍多模态技术的整体框架,包括封面模态匹配技术,视频内容帧匹配技术,多模态融合等技术的演进和实践经验。1.1 视频搜索场景难点在 QQ 浏览器的搜索入口进行搜索,在综搜结果页或视频 tab 页下,有 50% 左右的搜索词下会有相关的视频结果展示:

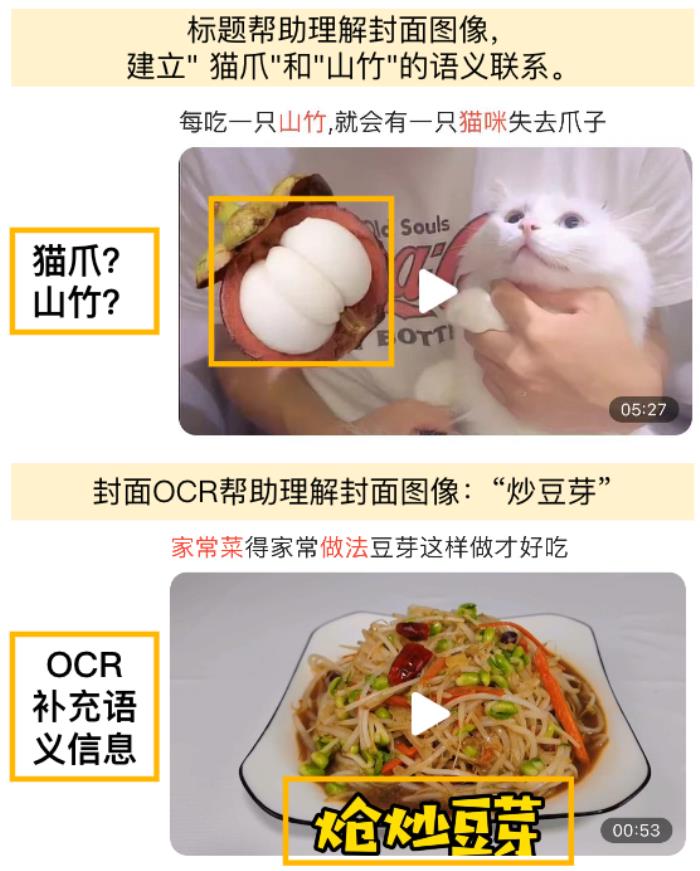
(图 1:QQ 浏览器搜索入口,以及视频搜索场景)不同于文本网页搜索,视频搜索有其自身独特性:视频封面作为丰富的视觉呈现,对用户有很大的吸引力,同时视频帧也蕴含巨大的信息,并且视频还有封面 OCR 文本、字幕文本等有信息增益的特征(如图 2、3 所示)。最后,视频资源作为众多模态的综合载体,如何把它们进行对齐融合也存在挑战。

(图 2:视频示例:query = 好看高级的围巾系法)

(图 3:视频是多种模态信息的综合载体)
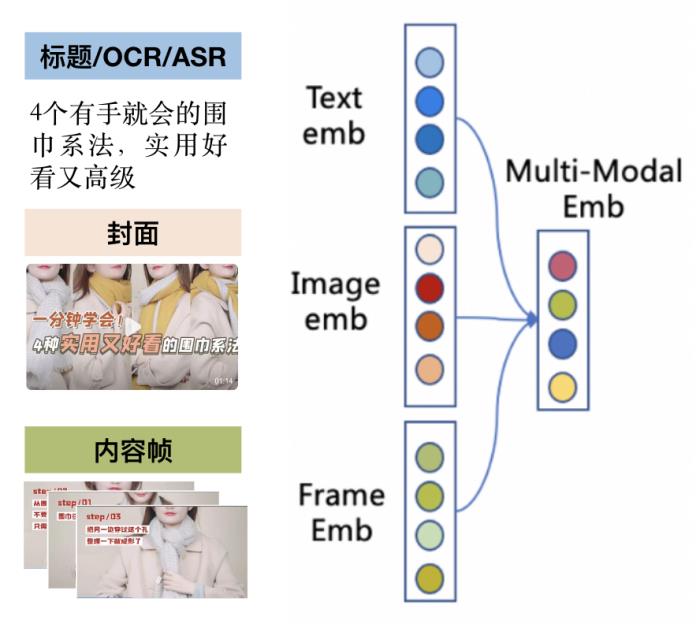
(图 4:视频多模态的融合)1.2 多模态技术的位置视频多模态技术即要解决上述提及的相关问题,包括 query - 视频封面匹配、query - 视频内容帧匹配、query - 视频融合态匹配、query - 感知域融合匹配。这些匹配信息生效在视频精排阶段,起到非常高的权重作用。同时视频多模态技术还涉及质量价值、ASR/OCR 识别、tag 标记、索引等逻辑场景。
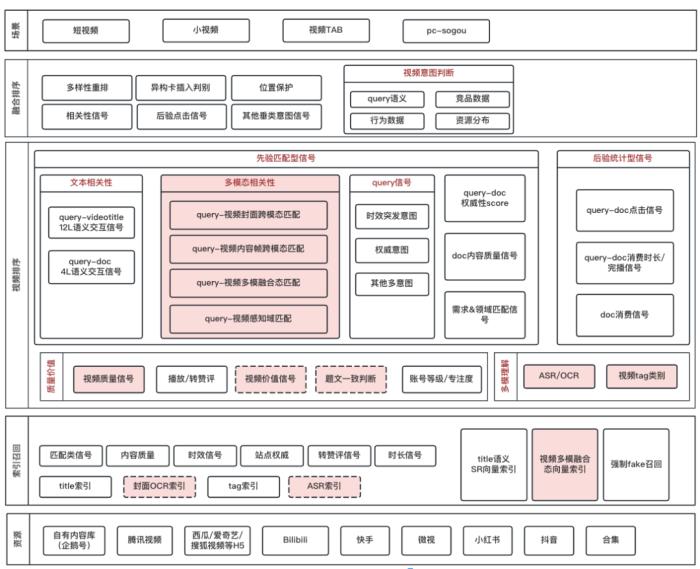
(图 5:视频多模态技术生效的逻辑位置示意 (红))接下来,本文将着重阐述在视频搜索排序中的相关技术实践。2 关键技术2.1 背景视频搜索多模态技术围绕以下三个技术关键点:模态表征:对视频的文本 / 图像 / 帧序列进行更好的表征,是后续模态融合 / 匹配的基础。模态融合:视频本身是多模态的信息载体(包括文本 / 图像 / 音频等),而多模态的表征和建模的核心在于如何对不同模态的表征进行有效的融合。模态匹配:传统搜索引擎以 query 和 doc 文本匹配信息为主(即文本相关性),而视频搜索场景下如何进行更好的跨模态匹配则是关键。在分享视频搜索多模态技术实践之前,我们会对这些技术的发展演进进行梳理和总结,以方便读者后续更好的理解。2.1.1 模态表征技术2.1.1.1 图像模态的表征学习整体而言,图像模态表征学习技术的发展和演进,可以从以下两个角度看:表征模型:CNN 时期(2020 年之前):以 VGG、ResNet 等为代表。我们在第一版本时就是使用了 ResNet 方案。
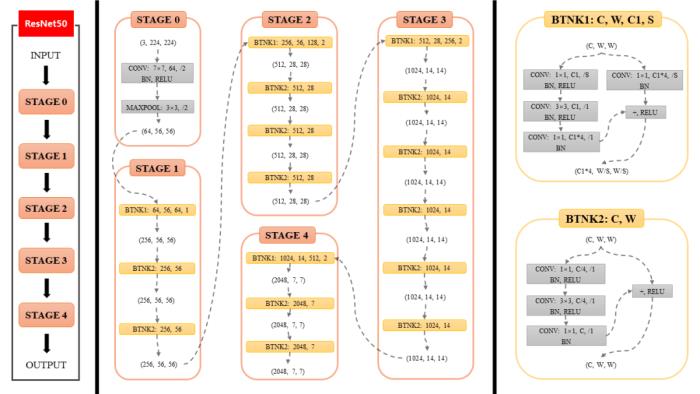
(图 6:CNN 时期的图像模态表征模型代表 --ResNet)Transformer 时期(2020 年至今):以 Vision Transformer (简称 ViT) 和 Swin Transformer 等为代表。后来我们逐步将方案由卷积迁移到注意力方案上来。
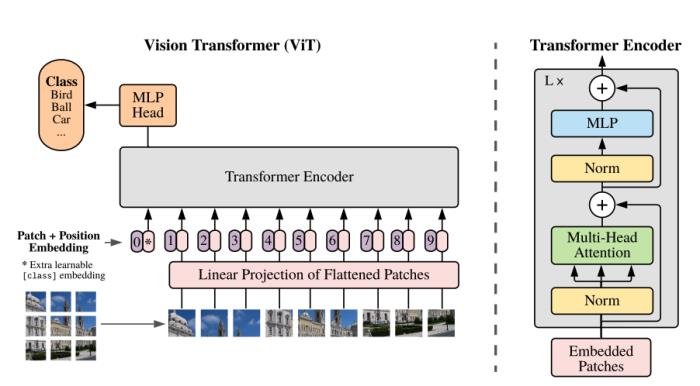
(图 7:Transformer 时期的图像模态表征模型代表 --Vision Transformer (ViT))2.1.1.2 内容帧模态的表征学习从视觉角度上看,视频可以认为是由一组时间序列连续的图像模态构成。表征内容帧模态的经典模型方法包括:以 CNN 为 backbone 的代表模型:I3D、X3D 等。
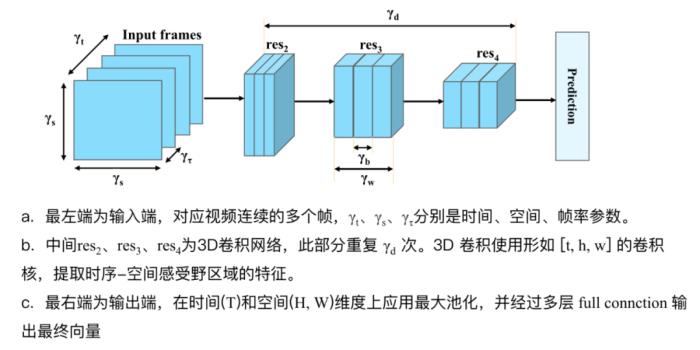
(图 8:以 CNN 为 backbone 的视频表征模型 --X3D)以 Transformer 为 backbone 的代表:ViViT、Video Swin Transformer 等。
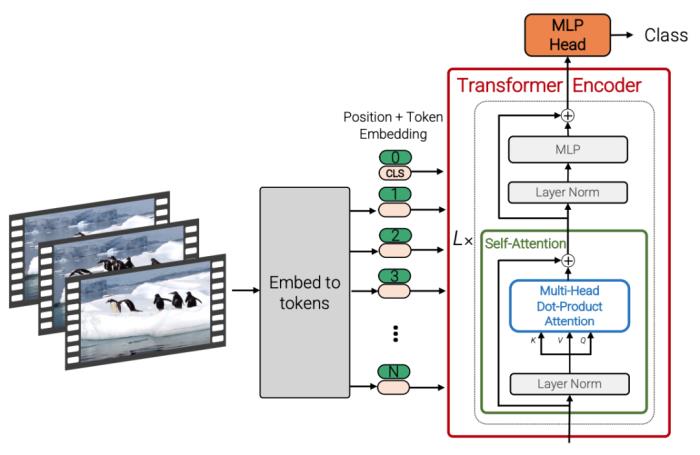
(图 9:以 Transformer(ViT)为 backbone 的视频表征模型 --ViViT)2.1.2 模态融合技术多模态表征的核心在于如何对不同模态进行有效融合。基于不同模态信息的冗余性和互补性特性,有效的多模态融合能够显著提升多模态表征效果。从技术方法的角度,模态融合可以分为:简单融合的方法:如对多种模态特征进行拼接,加权求和等。基于张量分解的方法:如 TFN、LMF 方法等;LMF 是 TFN 的改进方法,通过将张量和权重并行分解,利用模态特定的低阶因子来执行多模态融合,显著提升了训练效率。基于注意力机制的方法:如 cross-attention、modal-attention 方法等;ALBEF 模型里图文模态的融合采用的就是 cross-attention 的方法。
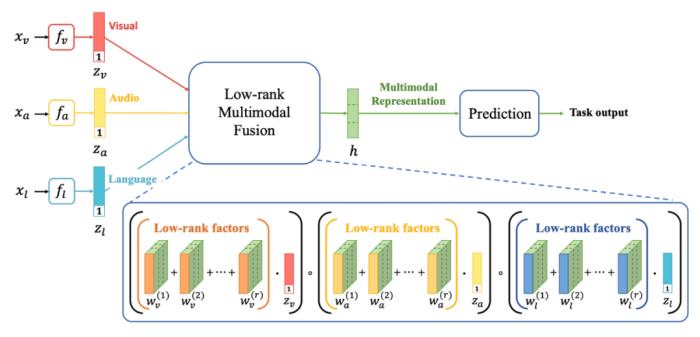
(图 10:基于张量分解的融合方法 --LMF)
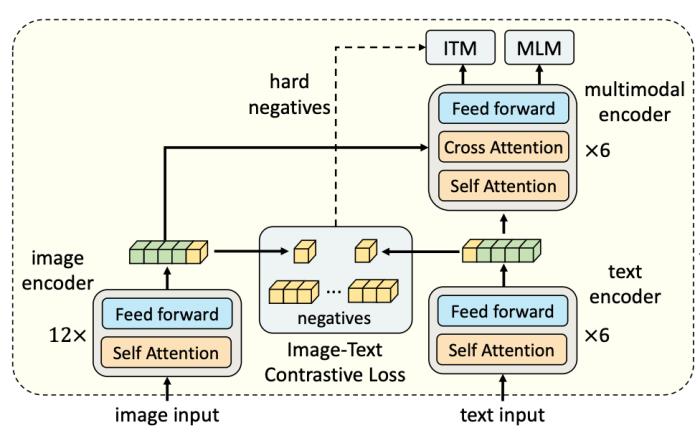
(图 11:基于 cross-attention 的融合方法 --ALBEF 模型)2.1.3 模态匹配技术这里我们主要针对多模态匹配,其中典型代表是视觉 - 语言模态的匹配任务。从模型结构区分,多模态匹配模型结构通常有两种:单流结构模型:在模型输入层时对各个模态进行融合,后续输入到模型 encoder 中进行充分的交互学习。典型模型有 VL-BERT、ImageBERT、VisualBERT 等工作。
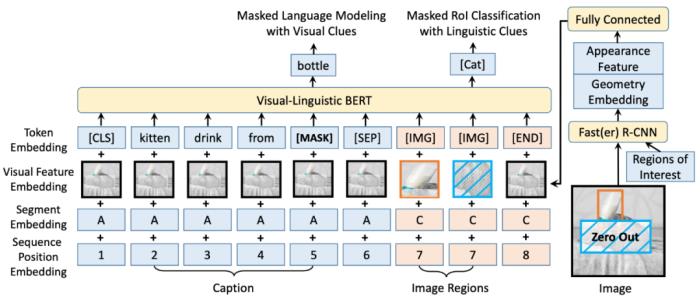
(图 12:单流模型结构代表 --VL-BERT)双流结构模型:对不同模态采用独立的 encoder 得到各自的单模态表征,然后进行浅层的交互计算。典型模型有 ViLBERT、MCAN、CLIP 等工作。
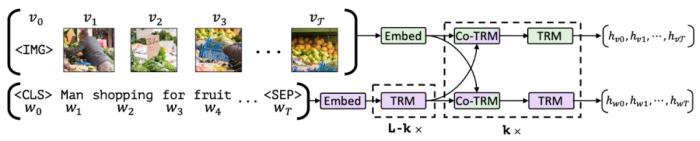
(图 13:双流模型结构代表 --ViLBERT)2.2 视频搜索里的多模态技术框架QQ 浏览器视频搜索里多模态技术整体框架如下图:
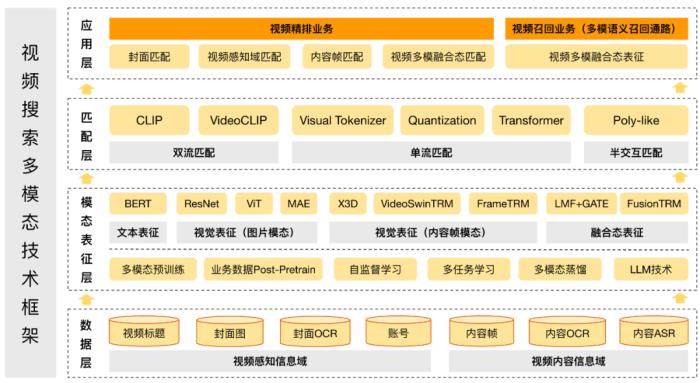
(图 14:视频搜索多模态技术框架)数据层:视频有丰富的模态数据,包括视频标题、封面、OCR、账号、内容帧和 ASR 等。模态表征层:通过大模型预训练技术、引入业务数据 Post-Pretrain 多阶段训练和 LLM 技术能力,结合业务需求引入多任务学习和多模态蒸馏技术,提升模态表征和后续匹配的效果。匹配层:直接进行在线部署计算,业界常见做法为 query 侧在线计算特征,doc 侧则离线刷特征入正排索引,双塔方式应用生效。为了进一步提升匹配的效果,我们引入了 Poly-like 的半交互匹配技术进行优化,同时也在积极探索在线单流匹配模型。应用层:精排阶段通过构建 query 与封面模态、视频感知模态、内容帧模态和多模融合模态的匹配特征,提升视频搜索效果和用户体验。2.3 封面模态的表征和匹配技术2.3.1 核心问题视频封面是视频资源最重要的摘要,体现在引入封面模态能够解决传统相关性技术依赖标题文本存在的局限性。同时,封面对用户的吸引和点击行为有着至关重要的影响。

(图 15:视频标题文本相关但感知不相关的问题示例)2.3.2 技术实践2.3.2.1 图像表征能力的升级:从 ResNet 到 ViT (引入 MAE 预训练)QQ 浏览器早期的封面模态表征模型为 ResNet,采用有监督的训练方式。存在两个问题:CNN 网络结构更加注重局部表征,同时图像局部表征之间缺少交互学习。有监督学习依赖数据标注。因此,我们后续引入了 ViT 模型结构和 MAE 预训练技术来解决这些问题:一方面,ViT 提出的图片 patch 化操作和引入 transformer 结构能够增加图像局部表征之间的交互学习,最终得到全局表征能力更好的图像表征。同时,随着训练数据和模型参数规模的提升,ViT 模型的效果上限更高。另一方面,我们引入 MAE 预训练技术对 ViT 进行大规模的业务数据预训练。最终在业务场景取得了明显的收益:单特征排序指标:PNR 指标提升 34%,小流量实验视频卡 CTR +0.76%。我们发现,开源模型预训练的数据分布和业务数据存在较大的差异,通过预训练阶段引入大规模业务数据训练能够显著提升模型在业务数据上的适配效果。以 MAE 为例,其开源模型的预训练数据主要来源于 ImageNet 数据集,数据主要分布在动物、植物、交通工具、建筑物等常识物品等,其表征能力更加偏向于通用领域的常识性视觉元素。但视频搜索场景的封面数据以人脸、影视画面,带有 OCR 文字等居多,两者数据分布存在较大的差异。

(图 A:ImageNet 开源图片示例) (图 B:视频搜索业务封面图片示例) (图 16:ImageNet 开源图片和视频搜索业务封面图片对比)通过引入业务数据的预训练,在封面测试集上 PNR 指标有显著的提升(提升 39%)。同时,通过可视化掩码像素重建,能够验证确实提升了模型在业务数据上的表征能力。
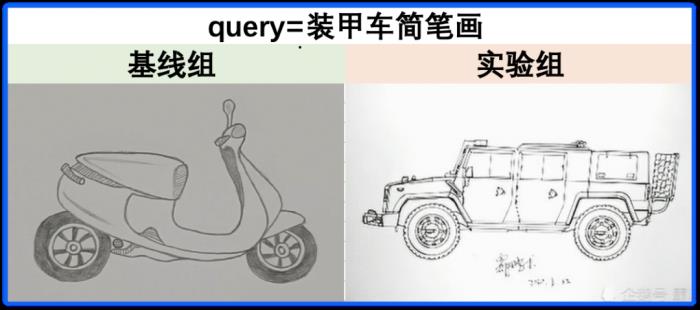
(图 17:实验组 MAE 的效果对比)2.3.2.2 图文匹配能力的升级:引入中文领域的图文匹配预训练模型封面模态的表征是后续视频多模态表征的基础,同时作为视频精排阶段重要特征之一,在排序阶段,我们更加关注如何做好图文跨模态匹配。早期的匹配方案是先各自得到图文单模态的表征,然后基于点击数据和人工标注相关性数据做跨模态的对齐。这种方案的问题在于:预训练阶段和最终的应用阶段目标存在 gap,即预训练阶段的目标为模态的表征学习,后续微调阶段为匹配学习。逻辑上如果我们在早期的预训练阶段就引入图文匹配和对齐的任务,对于业务中 query - 封面模态匹配效果应该有较大的提升。于是,我们引入了 CLIP 的模型结构,实现预训练阶段与微调阶段的目标统一,并在业务里验证了方案的有效性。
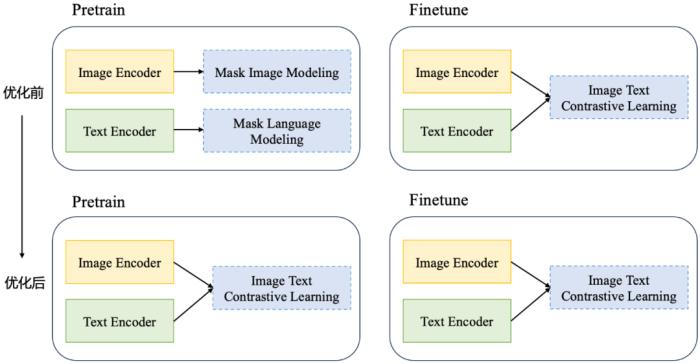
(图 18:query - 封面匹配引入 CLIP 模型结构)具体而言,我们引入当时在中文检索任务取得 SOTA 的中文预训练 CLIP 模型 -- ChineseCLIP 作为基底模型。并测试了 ChineseCLIP 模型在 ZeroShot 下的业务数据样本上的 PNR 指标情况,如下:
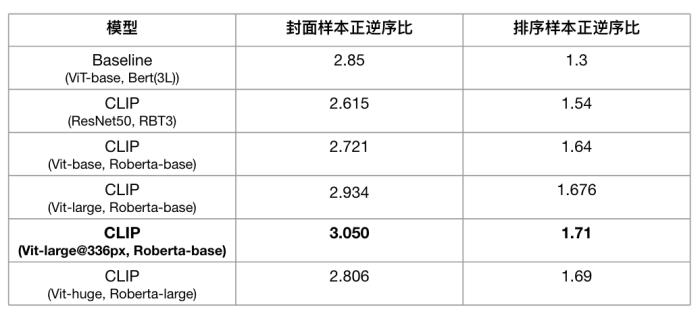
(表 1:ChineseCLIP 模型 ZeroShot 下封面样本和排序样本测试集的 PNR 指标)基于 ZeroShot 指标结果,我们引入其中效果最佳的模型,即对齐后的 12 层文本 RoBERTa 和 24 层图像 ViT-Large-336 作为后续 query 封面匹配模型的基底模型。在此基础上,通过引入大规模的业务数据(标题 - 封面)进行 Post-Pretrain,点击样本(query - 封面)和人工标注相关性样本(query - 封面)等多个阶段的训练手段,更好地让模型适配业务场景。
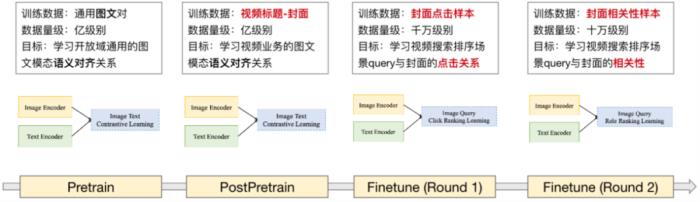
(图 19:深度适配视频业务的多阶段训练流程)相比 ZeroShot,经过上述的训练流程后,排序 test 样本 PNR 指标:1.71->1.926(提升 12.6%)。2.3.2.3 多模态蒸馏技术的探索和实践受到资源和成本的约束,封面匹配模型 query 侧 12 层模型难以直接部署,于是我们探索针对多模态匹配场景的蒸馏方案。由于主要针对 query 侧的模型(12 层 RoBERTa)进行蒸馏,目标蒸馏到 3 层小模型。我们参考 BERT-PKD 的做法,等间隔抽取大模型参数初始化。相比在传统的 BERT 上做蒸馏,我们的场景下还需要额外考虑小模型和图片 encoder 的对齐。因此,我们对比了几种不同的蒸馏方案:方案一(两阶段训练和蒸馏方案):首先训练大模型,效果收敛后 “冻住” 大模型参数,蒸馏小模型;蒸馏阶段的 Loss 包含与文本小模型和图片表征的对比学习损失和文本表征蒸馏损失。
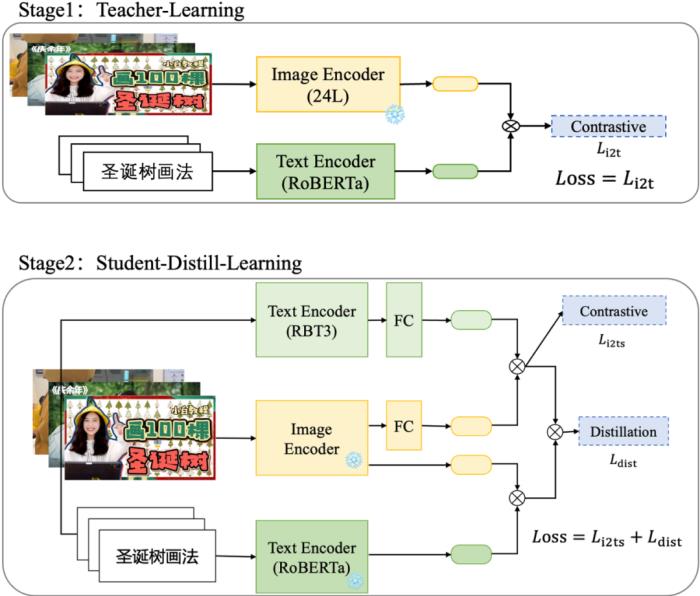
(图 20:两阶段训练和蒸馏方案)方案二(蒸训一体的方案):训练大模型和蒸馏小模型的过程同时进行,这里的 Loss 为两个尺寸的文本模型表征和图片表征的对比学习损失和文本表征蒸馏损失。
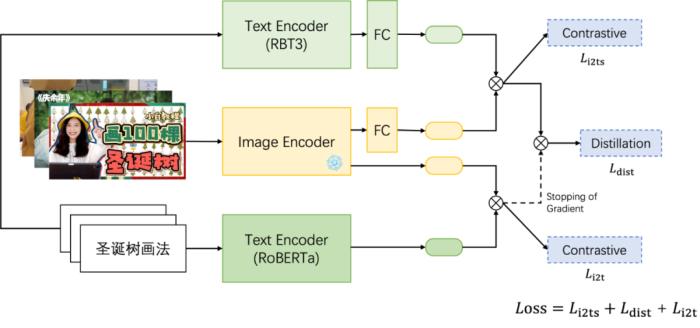
(图 21:蒸训一体的方案)实验对比两种蒸馏方案的效果后,我们发现蒸训一体的方案效果更佳:蒸馏损失相比两阶段蒸馏方案在封面测试集和排序测试集上分别减少 2.22% 和 1.03%。
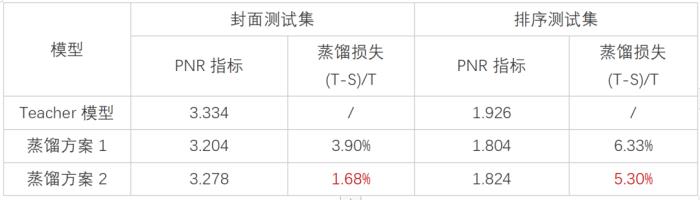
(表 2:两种蒸馏方案的效果指标对比)蒸训一体的方案思路也同样应用于后续视频内容帧模型的训练和其他项目里。
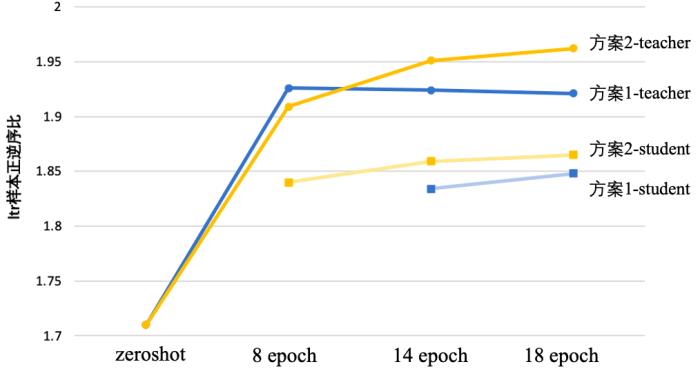
(图 22:两种方案大小模型在训练过程中的指标变化情况)通过引入中文预训练的图文模型、多轮业务数据训练和多模态蒸馏等手段,我们取得了明显的收益:单特征 PNR 指标提升 40.63%;小流量实验视频卡 CTR +1.33%;线上模型 encoder 参数、部署成本减小至之前 1/4。2.4 内容帧模态的表征和匹配技术2.4.1 核心问题搜索结果摘要相关不代表真实内容相关,例如搜索场景下的题文不符作弊类型的低质结果。我们需要重点关注内容真实相关性,提升视频的长点和消费时长。

(图 23:视频感知相关而内容不相关的问题示例)内容帧是视频内容最重要的视觉模态信息,也是用户对视频内容感知直接的信息源。引入内容帧的表征,并与用户需求 query 进行匹配计算相关性,是解决上面问题的主要手段之一。2.4.2 技术实践2.4.2.1 视频帧模态表征的升级:从 X3D 到 Video Swin Transformer业务早期的视频帧模态表征模型为 X3D,输入多个连续的视频帧,通过卷积核进行特征提取,得到视频帧模态的表征,在空间、时间、宽度和深度上沿多个网络轴扩展。但 Conv 算子感受野比较局限,为了扩大网络的关注区域,需要堆叠多个卷积层和池化层,在全局表征能力上有所欠缺。我们后续引入了 Video Swin Transformer,其将 Conv 算子的滑窗机制和 Transformer 的自注意力机制进行结合,能够实现 Transformer 全局表征能力的同时兼具训练参数量和训练效率的优势。通过将视频帧模态表征从 X3D 模型升级到 Video Swin Transformer,在实际业务上取得了明显的收益:单特征 PNR 指标提升 11%;小流量实验指标:视频长有点率 + 1.1%(代表内容更加满足)。2.4.2.2 视文匹配能力的升级:引入 VideoCLIP视频搜索业务的核心问题是如何对搜索 query 和视频内容做匹配。对于视频帧而言,视频内容的体现主要在各个帧的图像模态信息,而非帧之间的时序模态信息。视频帧的表征与封面模态的应用方式相同,如何做好 query - 视频帧之间的跨模态匹配十分重要,早期的匹配方案是先得到单模态的表征模型,然后基于点击数据和人工标注相关性数据做跨模态的对齐,这种方案的缺点在上文已经说明。因此,我们引入了 VideoCLIP 的模型结构,实现预训练阶段与微调阶段的目标统一。在视频帧模型的表征上使用 ChineseCLIP + 多帧融合的方式,视频帧时序建模这块我们采用常见的 Transformer 建模,即将各个时序的内容帧依次输入到 Transformer 里。与封面模态匹配类似,我们需要蒸馏出一个文本小模型用于在线 query 特征推理,沿用蒸训一体的方案,模型训练的 Loss 包括文本大小模型与视频模型的对比学习损失、文本模型与视频帧的对比学习损失和蒸馏损失。
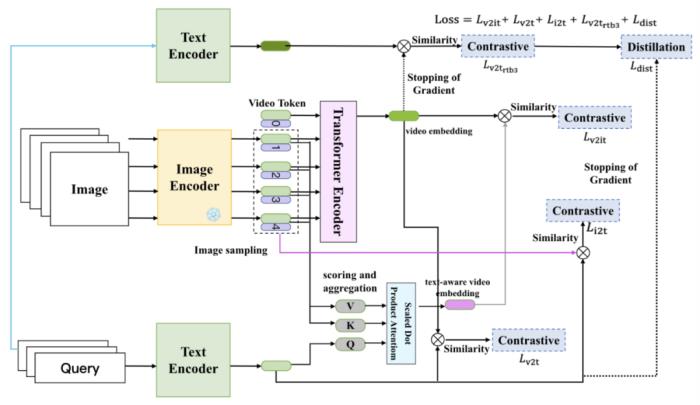
(图 24:VideoCLIP 的模型结构)在基于图文 PostPretrain 的模型基础上,引入了在业务数据上针对视文匹配的多阶段训练,实现模型效果更好的适配业务场景。
(图 25:VideoCLIP 模型的多阶段训练过程)通过视文匹配模型的升级,在实际业务上取得了明显的收益:单特征 PNR 指标提升 42.3%;小流量实验视频长有点率 + 1.5%。2.5 视频多模态的融合和匹配技术2.5.1 核心问题视频是多模态信息载体,包括标题、封面、OCR、内容帧和音频等信息域,不同模态存在信息的互补性。视频表征的核心问题在于如何有效进行多模态融合。
(图 26:视频载体不同模态的信息互补性示例)2.5.2 技术实践基于不同模态之间信息的互补特性,通常多模态融合能取得较单模态更好的效果。在视频搜索业务中多模态融合技术体现在两个方面:视频感知域融合:目标是建模 query - 视频感知相关性,我们将视频感知定义为用户点击播放视频前能看到视频展现结果的所有信息,它是消费视频的前提,因此我们希望产生更多的用户点击分发。视频内容域融合:目标是建模 query - 视频内容相关性,刻画满足用户 query 的真实相关性,视频内容域包括视频所有可获取到的模态信息域,即在视频感知信息域的基础上,还有内容 OCR,内容帧,音频 / ASR 等。视频内容相关性是视频排序的重要依据,也是影响用户体验 / 深度消费最重要的维度。两者的区别在于目标的不同,目标的差异导致弱监督阶段训练数据的不同,视频感知域融合采用点击样本为主,而视频内容域融合则在点击样本的基础上引入视频播放时长、完播率等指标进行样本的优化,旨在过滤出内容真实相关的视频结果。下面我们重点介绍视频内容域融合方面的技术实践,体现在两个方面:信息域:引入更多的内容域(如 ASR),实现信息域完备的内容相关性建模。融合方式:升级多模态融合的方式,提升融合效果。2.5.2.1 构建全面的视频内容模态表征:引入 ASRASR 是视频音频的文本模态,也是表征视频内容信息的重要模态。短视频时长一般在 1-5 分钟左右,视频 ASR 普遍偏长,平均长度在 600 字左右。直接将原始的 ASR 输入模型对性能开销有很大的挑战,因此需要解决如何对长文本进行建模和表征。早期的 ASR 建模方法是基于 title-based 的贪心策略抽取方法,做法是通过视频标题的分词词权和紧密度对 ASR 的分句进行核心句筛选,同时考虑多样性问题。然而基于贪心抽取核心句的方法问题在于:1. 视频标题存在信息量低、作弊结果的情况,对应抽取出的核心句有偏。2. 抽取出的语义片段可能联系较弱,对整体的内容表征效果较差,常出现语义理解不通顺、错字等问题。随着 ChatGPT 等大模型技术的兴起,我们尝试引入 LLM 技术来抽取核心句,具体的做法是基于开源的 LLM 模型进行通用 NLP 任务的微调对齐,输入调优后的 prompt 指令,对 ASR 进行核心句的抽取。实验发现,LLM 能够抽取更加表征视频内容核心主题、通顺 & 文本质量高的核心句,基于 LLM + 微调的方案相比贪心的方案在核心句的质量上有显著的提升(其中 2 档核心句从 16.67% 提升到 80%)。
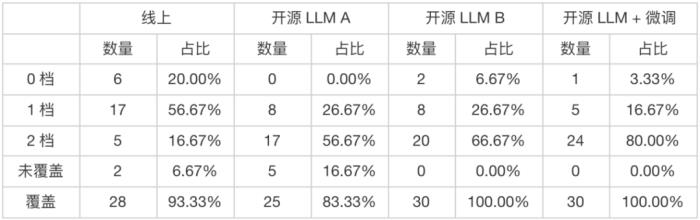
(表 3:基于 LLM 的 ASR 核心句抽取效果对比)

(图 27:基于 LLM 的 ASR 核心句抽取效果对比示例)同时,我们也评估了两种 ASR 抽取方式对端到端融合效果的影响,基于 LLM 抽取的方式相比贪心的方式在排序测试集的 PNR 指标有相对 4% 的提升,验证了 LLM 抽取核心句的有效性。2.5.2.2 多模态融合方式的优化:从 LMF+GATE 到 Fusion Transformer早期的多模态融合方法采用 LMF+GATE,通过对各个模态的权重参数进行低秩矩阵分解降低参数,GATE 网络控制各个模态的权重,进行轻量级的模态融合。然而,这种方法的问题在于 LMF 对输入的模态特征维数敏感,而特征降维势必对效果产生影响,因此我们引入基于 Fusion Transformer 的融合方法,通过输入各个模态的原始模态表征并基于 attention 的方式进行充分的融合交互,进一步提升效果。
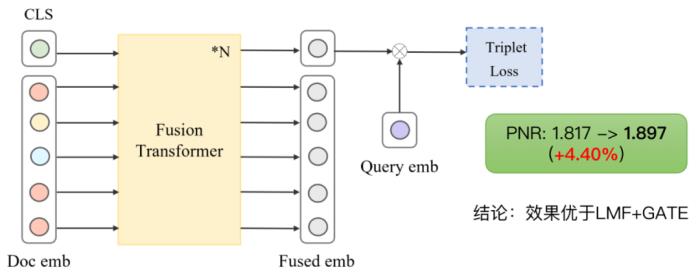
(图 28:基于 Transformer 的模态融合方式)我们在视频内容相关性业务场景,对比了几种常见多模态融合方法的效果,可以发现,基于 Transformer 的融合方法能够取得最佳的效果。

(表 4:视频内容表征任务上几种常见多模态融合方法的效果)2.5.2.3 多模态匹配方式的优化:引入 Poly-Like 半交互方法目前业界普遍采用双塔交互的方式计算多模态匹配特征,然而双塔的方式由于交互阶段比较晚期,效果较单塔的方式有较大的差距。Poly encoder 提出一种基于半交互的方式,通过引入 query 信息指导 doc 侧最后一层的加权融合,实现较双塔匹配更好的效果。
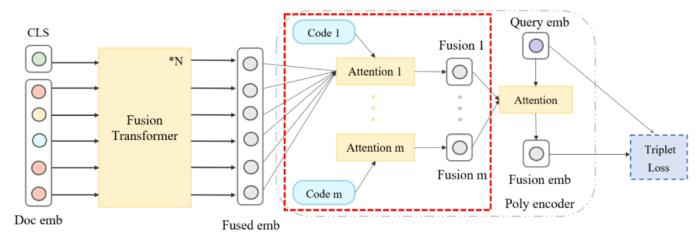
(图 29:基于 Poly encoder 的多模态融合交互方式)在 Poly encoder 的基础上,我们还尝试了多种对多模态融合向量的选取方案,包括:方案 1:基于 query emb 选取余弦相似度最大的 fusion emb;方案 2:基于 query emb 选取余弦相似度最小的 fusion emb;方案 3:多个 fusion emb 取平均。我们发现相比原始的 Poly encoder,方案 1 在测试集的 PNR 指标有相对 0.6% 的提升,而其他方案有所下降。我们推测是:方案 1 相比加权融合的方式,更加容易选出融合效果更佳的表征向量结果,指导模型训练。
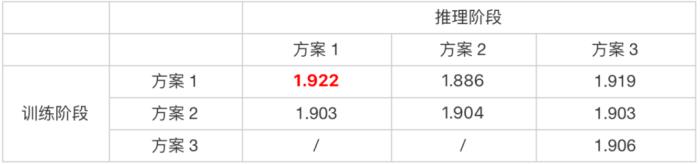
(表 6:不同多模态融合向量选取方案指标对比)
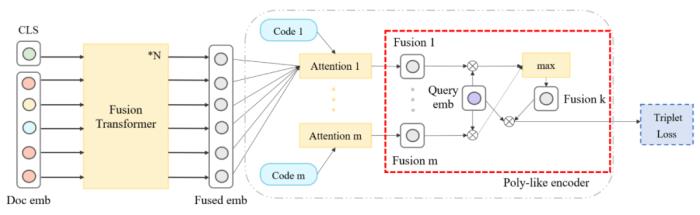
(图 30:基于 Poly like 的多模态融合交互方式,改进训练过程中融合向量的选取方式)在推理阶段,我们采用平均加权融合方式,出于两方面考虑:效果层面,相比训练过程采用的融合向量选取方式,平均加权的融合方式在测试集 PNR 指标下降极低(-0.15%)。性能层面:保留双塔的性能优势,同时将特征存储成本下降至原来的 1/5。视频内容融合态项目通过引入 LLM 抽取的 ASR 构建更为全面的内容模态表征、融合方式的优化升级和引入 Poly like 半交互匹配方法等技术手段,构建了基于多模态的 query - 视频内容相关性匹配特征应用于视频的召回和排序阶段,取得了明显的业务收益:离线评估:单特征排序指标:PNR 指标提升 57.5%;多模态融合特征 PNR 指标远高于各个单模态(验证多模态融合的有效性):

(表 6:多模态 vs 单模态 PNR 指标对比) 小流量实验:视频消费时长 + 4.31%,视频长点率 + 2.18%。总结以上的内容从模态表征、匹配和融合等角度,分享了 QQ 浏览器在视频搜索业务场景多模态技术的实践和经验。通过不断引入和升级迭代视频搜索业务场景里的多模态技术能力,充分考虑视频载体的多模态信息,深度适配视频业务场景,多模态方向项目显著地提升了视频搜索结果的相关性和用户体验,较大程度上解决了传统搜索场景里依赖文本相关性解决不好的问题。后续 QQ 浏览器将持续积极地优化和升级业务多模态技术能力,同时持续关注学业界多模态新技术发展并探索新技术在搜索场景的落地应用,进一步提升视频搜索效果和用户体验。(注:本文部分工作是与腾讯多模理解、相关性计算、应用研究中心、上层排序等团队合作完成)。参考资料[1] Attention is all you need[2] Deep residual learning for image recognition[3] Masked autoencoders are scalable vision learners[4] Align before fuse: Vision and language representation learning with momentum distillation[5] Learning transferable visual models from natural language supervision[6] Efficient low-rank multimodal fusion with modality-specific factors[7] Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation[8] An image is worth 16x16 words: Transformers for image recognition at scale.[9] Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring[10] Auxiliary tasks in multi-task learning[11] An overview of multi-task learning in deep neural networks[12] X3d: Expanding architectures for efficient video recognition[13] Video swin transformer[14] Chinese clip: Contrastive vision-language pretraining in chinese[15] Neural discrete representation learning[16] Beit: Bert pre-training of image transformers[17] Beit v2: Masked image modeling with vector-quantized visual tokenizers[18] Qwen-vl: A frontier large vision-language model with versatile abilities


 新火种
2023-11-01
新火种
2023-11-01