新火种
2023-10-31
新火种
2023-10-31 


一个开源库搞定各类文本到音频生成,Meta发布AudioCraft
近来,Meta 发布并开源了多个 AI 模型,例如 Llama 系列模型、分割一切的 SAM 模型。这些模型推动了开源社区的研究进展。现在,Meta 又开源了一个能够生成各种音频的 PyTorch 库 ——AudioCraft,并公开了其技术细节。
代码地址:https://github.com/facebookresearch/audiocraft
项目主页:https://audiocraft.metademolab.com/?utm_source=twitter&utm_medium=organic_social&utm_campaign=audiocraft&utm_content=card
AudioCraft 能够基于用户输入的文本生成高质量、高保真的音频。我们先来听一下生成效果。
AudioCraft 可以生成一些现实场景中的声音,例如输入文本 prompt:「Whistling with wind blowing(风呼啸而过)」
还能生成有旋律的音乐,例如输入文本 prompt:「Pop dance track with catchy melodies, tropical percussions, and upbeat rhythms, perfect for the beach(流行舞曲,具有朗朗上口的旋律、热带打击乐和欢快的节奏,非常适合海滩)」
甚至还可以选择具体的乐器,生成特定的音乐,例如输入文本输入文本 prompt:「Earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves(朴实的曲调,环保理念,尤克里里,和声,轻松,随和,有机乐器,柔和的节奏)」
AudioCraft 简介
相比于文本、图像,音频生成是更具挑战性的,因为生成高保真音频需要对复杂的信号和模式进行建模。
为了高质量地生成各类音频,AudioCraft包含三个模型:MusicGen、AudioGen和EnCodec。其中,MusicGen使用Meta具有版权的音乐数据进行训练,基于用户输入的文本生成音乐;AudioGen使用公共音效数据进行训练,基于用户输入的文本生成音频;EnCodec用于压缩音频并以高保真度重建原始信号,保证生成的音乐是高质量的。
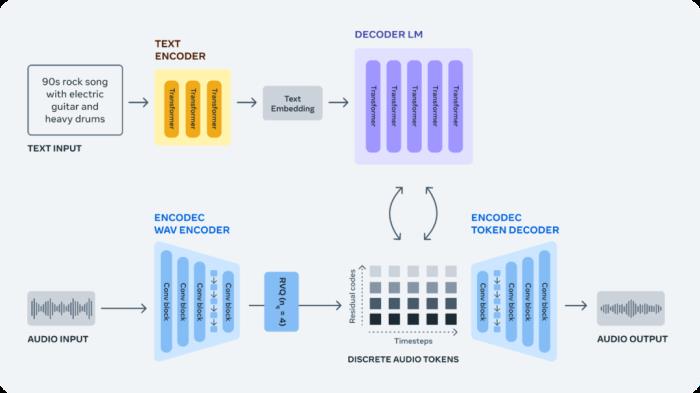
从原始音频信号生成音频需要对极长的序列进行建模。例如,以 44.1 kHz 采样的几分钟音乐曲目由数百万个时间步(timestep)组成。相比之下,Llama 和 Llama 2 等基于文本的生成模型是将文本处理成子词,每个样本仅需要几千个时间步。
MusicGen 是专门为音乐生成量身定制的音频生成模型。音乐曲目比环境声音更复杂,在创建新的音乐作品时,在长程(long-term)结构上生成连贯的样本非常重要。MusicGen 在大约 400000 个录音以及文本描述和元数据上进行训练,总计 20000 小时的音乐。
AudioGen 模型可以生成环境声音及声效,例如狗叫声、汽车喇叭声或脚步声。
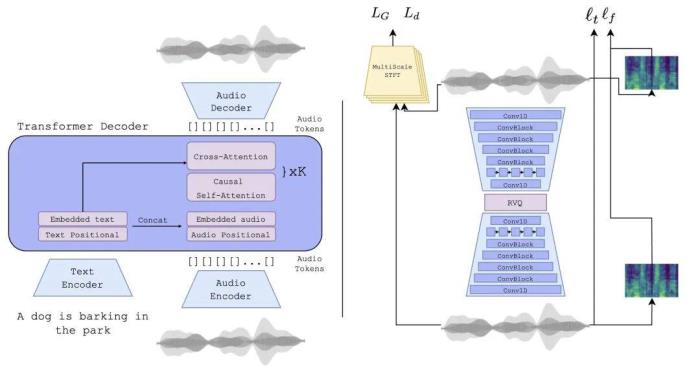
AudioGen 模型架构。
EnCodec 神经音频编解码器从原始信号中学习离散音频 token,这相当于给音乐样本提供了新的固定「词汇」;然后研究团队又在这些离散的音频 token 上训练自回归语言模型,以在使用 EnCodec 的解码器将 token 转换回音频空间时生成新的 token、声音和音乐。
总的来说,AudioCraft 简化了音频生成模型的整体设计。MusicGen 和 AudioGen 均由单个自回归语言模型组成,并在压缩的离散音乐表征流(即 token)上运行。AudioCraft让用户可以使用不同类型的条件模型来控制生成,例如使用预训练的文本编码器完成文本到音频生成。
参考链接:https://ai.meta.com/blog/audiocraft-musicgen-audiogen-encodec-generative-ai-audio/
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章