

 新火种
2023-10-30
新火种
2023-10-30 


DeepMind用深度强化学习研究“人造太阳”!据说这是秘密进行了3年的工作
 “AI+物理”成功破圈,DeepMind 怕是要上天。
“AI+物理”成功破圈,DeepMind 怕是要上天。作者 | 王晔
编辑 | 陈彩娴
北京时间凌晨四点,DeepMind在官方推特上发布消息,称其与瑞士洛桑联邦理工学院(EPFL)合作研究出第一个可以在托卡马克(Tokamak)装置内保持核聚变等离子体稳定的深度强化学习系统,为推进核聚变研究开辟了新途径,工作已发表在Nature!
消息一出,立刻引起围观,收获一千多点赞、数百转发:
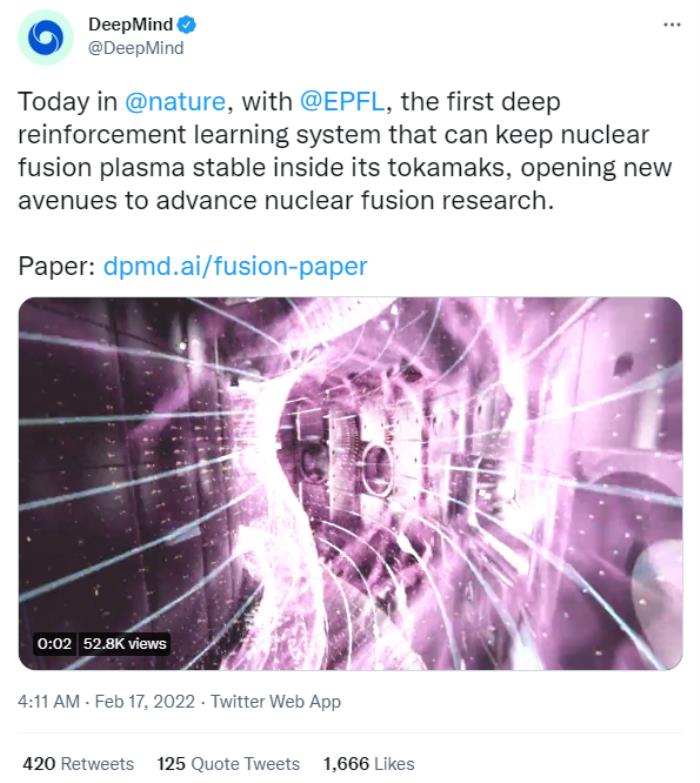
据该工作的其中一位成员@317070披露,该工作已经秘密进行了三年,并兴冲冲地表示:“它真的成功了!深度强化学习真的很擅长搞定这些人类迫切想实现的科幻想法。”
我们都知道,DeepMind是全球最早将人工智能应用于科学研究(即“AI for Science”)的研究机构之一,在过去的几年也取得了许多令人瞩目的成就,成功地在生物、化学、数学与物理模拟等等领域扎下了AI的影子,并吸引一大批学者投身“AI for Science”方向的研究工作。
此前,在DeepMind兼职担任高级研究科学家的华人学者王梦迪便曾对AI科技评论谈到,DeepMind有强大的信心将人工智能用于推动人类文明的进步,这种自信也感染了许多年轻的科学家:
DeepMind的价值观就是要推动人类文明的进步。我感觉研究人工智能的学者都非常自信,觉得自己有能力解决世界上最难的问题。这种自信非常棒,会给予自己主观能动性,也会感染其他学者,帮助不同学科的人更快、更好地联合在一起,去解决原先以为难于登天的问题。而近日DeepMind在难度更高的核物理发布突破成果,无疑更加证明、巩固了其在“AI for Science”方向的领头羊地位!
更有意思的是,AI科技评论编辑组还发现,早在五年前(2017年),就有中国网友在知乎上提出将深度强化学习系统用于学习可控核聚变装置建造技术的设想。莫非 DeepMind 的科研是跟着知乎走的……(手动狗头)
言归正传,我们来看看DeepMind这次又搞出了什么花样!
什么是托卡马克装置?
首先,为了更好地了解DeepMind此次的突破,以及“AI+核聚变”的奥妙,我们需要知道:什么是托卡马克(Tokamak)装置?
此前,知乎上还有一个关于托卡马克的讨论:“刘慈欣在《三体》中为什么不待见托卡马克装置?(托卡马克装置有什么弊端)”:
链接:https://www.zhihu.com/question/31056640/answer/56816872
当时就有网友@Shigen Chin回答:
首先,超导托卡马克的材料成本相对较高,相比之下激光核聚变只是设备一次性投资高,而超导托卡马克对于装备本身损耗比较严重,对于后续投入是不利因素(尤其是三体成为现实威胁 亟需技术突破的情况下)。其次,理论瓶颈,智子已经为物理理论研究建立壁垒,而超导托卡马克作为一种相对而言在可控核聚变研究中出现较早的思路,一直到现在没有大进展,很大程度上也是受理论研究所累,在没有取得理论突破的情况下,托卡马克装置投入实用的可能性不大再次,托卡马克本身的小型化十分困难,因为托卡马克的实用功率和约束时间和装备体积正相关,超低温制冷,磁约束需要较为庞大的设备,而实现设备小型化也需要材料等基础科学的进步,这些方面的进步又依赖于物理理论的进步(比如建立于原子尺度研究和量子力学基础上的电子计算机的发明和量子计算机概念的提出 带动了对于晶体管和光量子材料的工艺研究)。可能是基于以上的原因,大刘认为托卡马克不适于承担带领人类走入聚变时代的重任(笑)。言归正传:
托卡马克,又称“环磁机”,俄语原文“Токамак”,是一种利用磁约束来实现磁约束聚变的环形容器,最早由位于苏联莫斯科库尔恰托夫研究所(NRC KI)的物理学家伊戈尔·塔姆、安德烈·萨哈罗夫和列夫·阿齐莫维齐等人在1950年代发明。
根据百度百科的描述,托卡马克的中央是一个环形的真空室,外面缠绕着线圈(如下面动图)。通电时,托卡马克的内部会产生巨大的螺旋型磁场,将其中的等离子体加热到很高的温度,以达到核聚变的目的:
 图注:托卡马卡装置维基百科介绍,托卡马克是当前用于生产受控热核核聚变能中研究最深入的磁约束装置类型。磁场被用于约束是因为等离子体冷却会使反应停止,而超导托卡马克可长时间约束等离子体。世界上第一个超导托卡马克为俄制的T-7(托卡马克7号):
图注:托卡马卡装置维基百科介绍,托卡马克是当前用于生产受控热核核聚变能中研究最深入的磁约束装置类型。磁场被用于约束是因为等离子体冷却会使反应停止,而超导托卡马克可长时间约束等离子体。世界上第一个超导托卡马克为俄制的T-7(托卡马克7号): 听起来是不是很玄乎?一个更直白的例子是,2019年,新闻上报道中国耗资千亿的“人造太阳”,就是可控托卡马克装置:
听起来是不是很玄乎?一个更直白的例子是,2019年,新闻上报道中国耗资千亿的“人造太阳”,就是可控托卡马克装置:
AI+可控核聚变的前世事实上,早在AlphaGo击败人类世界的围棋冠军李世石后,就有网友在知乎上提问:据说AlphaGo是从零开始自学,运用了深度神经网络与蒙特卡洛树状搜索相结合的技术,那么是否能让AlphaGo从零开始学习可控核聚变装置建造技术呢?
 链接:https://www.zhihu.com/question/41295369/answer/142572075底下有网友@刘亚问回答,高温等离子体高自由能与约束的问题是托卡马克技术的主要难点,深度学习网络可能有助于解决这些问题,但难点在于:托卡马克装置在目前的约束技术条件下,难以小型化装置造价,以及氘消耗、等离子体加温等其它方面运行的成本,使实验装置的数量、运行次数均受限,难以支持盲目的反复运行实验涉及高温等离子体,目前约束技术条件下重复反复运行有安全性问题缺乏获取大样本的条件综上所述,深度学习技术不一定适合解决托卡马克可控核聚变装置。相比托卡马克,另一类核聚变装置——反场箍缩装置(Reversedfieldpinch,RFP)更适合用深度学习进行研究,因为:“其内外两套磁场方向相反的磁体合成的特殊磁场,可以稳定等离子体的边缘,体积相对小、运行成本相对低、安全性相对高。”
链接:https://www.zhihu.com/question/41295369/answer/142572075底下有网友@刘亚问回答,高温等离子体高自由能与约束的问题是托卡马克技术的主要难点,深度学习网络可能有助于解决这些问题,但难点在于:托卡马克装置在目前的约束技术条件下,难以小型化装置造价,以及氘消耗、等离子体加温等其它方面运行的成本,使实验装置的数量、运行次数均受限,难以支持盲目的反复运行实验涉及高温等离子体,目前约束技术条件下重复反复运行有安全性问题缺乏获取大样本的条件综上所述,深度学习技术不一定适合解决托卡马克可控核聚变装置。相比托卡马克,另一类核聚变装置——反场箍缩装置(Reversedfieldpinch,RFP)更适合用深度学习进行研究,因为:“其内外两套磁场方向相反的磁体合成的特殊磁场,可以稳定等离子体的边缘,体积相对小、运行成本相对低、安全性相对高。”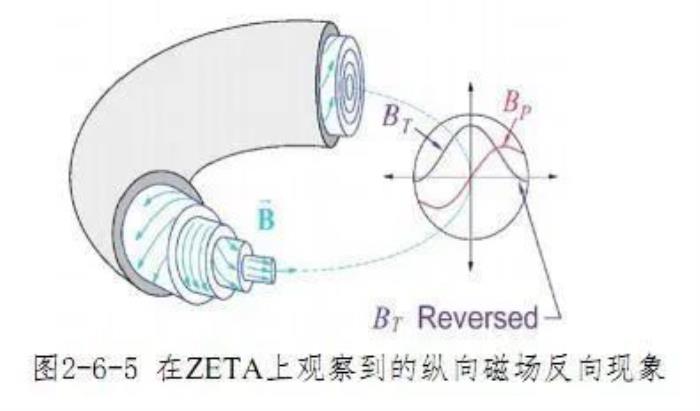 他还分享了资料,称机器学习的研究者从上世纪90年代末就开始将机器学习方法用于反场箍缩研究稳定等离子体的边缘的反馈控制:Barana O, Manduchi G, Serri A, et al. A neural network approach for the detection of the locking position in RFX[C]// Fusion Engineering, 1999. Symposium on. IEEE, 1999:575-578.Olofsson K E J. Nonaxisymmetric experimental modal analysis and control of resistive wall MHD in RFPs : System identification and feedback control for the reversed-field pinch[J]. Fusion Plasma Physics, 2012.除了以上研究,从2014年起,谷歌就和核聚变公司TAETechnology进行合作,将机器学习应用于不同类型的聚变反应堆,以加速试验数据的分析;此外英国中部欧洲环面JET联合设施也在利用人工智能来预测等离子体的行为。随着核聚变反应堆规模的增大,托卡马克设备越来越复杂,对于可靠性和准确性控制的要求也在不断提高,人工智能在其中将起到越来越关键的作用。
他还分享了资料,称机器学习的研究者从上世纪90年代末就开始将机器学习方法用于反场箍缩研究稳定等离子体的边缘的反馈控制:Barana O, Manduchi G, Serri A, et al. A neural network approach for the detection of the locking position in RFX[C]// Fusion Engineering, 1999. Symposium on. IEEE, 1999:575-578.Olofsson K E J. Nonaxisymmetric experimental modal analysis and control of resistive wall MHD in RFPs : System identification and feedback control for the reversed-field pinch[J]. Fusion Plasma Physics, 2012.除了以上研究,从2014年起,谷歌就和核聚变公司TAETechnology进行合作,将机器学习应用于不同类型的聚变反应堆,以加速试验数据的分析;此外英国中部欧洲环面JET联合设施也在利用人工智能来预测等离子体的行为。随着核聚变反应堆规模的增大,托卡马克设备越来越复杂,对于可靠性和准确性控制的要求也在不断提高,人工智能在其中将起到越来越关键的作用。DeepMind如何做?2月16日,DeepMind与EPFL合作研究的深度强化学习系统助力可控核聚变的工作在Nature上发布:
 链接:https://www.nature.com/articles/s41586-021-04301-9那么,他们是如何用深度强化学习实现在托卡马克装置内保持核聚变等离子体稳定的呢?托卡马克装置研究的一个主要方向是将等离子体的分布构建成不同配置的效果,以优化稳定性、封闭性和能量排放,并为第一个燃烧等离子体实验ITER提供通知。而要在托卡马克内限制每个配置,需要设计一个反馈控制器,通过精确控制几个与等离子体磁耦合的线圈来操纵磁场,以达到理想的等离子体电流、位置和形状。这个问题也就是著名的“托卡马克磁控制问题”。在传统方法中,要解决这个时变的、非线性的、多变量的控制问题,首先要解决一个反问题,即:预先计算一组前馈线圈电流和电压,然后设计一组独立的、单输入、单输出的PID控制器,使等离子体保持垂直位置,并控制径向位置和等离子体电流,所有这些控制器在设计时也要注意不能相互干扰。大多数控制结构都会增加对等离子体形状的外部控制回路,这就需要对等离子体平衡进行实时估计,以调制前馈线圈电流。控制器的设计建立在线性化模型动力学的基础之上,需要进行增益调度以跟踪时间变化的控制目标。尽管这些控制器在大多数情况下表现不错,但每当目标等离子体配置发生变化,就需要花费大量的工程努力、设计努力和专业知识,同时还要进行复杂的平衡估计实时计算。这时,深度强化学习就派上了用场:强化学习可以作为一种全新的方法,用来设计非线性反馈控制器,可以直观地设置性能目标,将重点转移到“应该实现什么”,而不是“如何实现”。此外,强化学习技术极大简化了控制系统,计算成本低的控制器取代了嵌套的控制结构,而内部化的状态重建消除了对独立平衡重建的要求。一句话:这些优势可减少控制器的开发周期,加速对替代性等离子体配置的研究。在这个工作中,他们提出了一个由强化学习设计的磁性控制器,可以自主学习指挥全套的控制线圈,既可以实现高水平控制,也能满足物理和操作的约束条件,在生产等离子体配置时大大减少了设计的工作量。
链接:https://www.nature.com/articles/s41586-021-04301-9那么,他们是如何用深度强化学习实现在托卡马克装置内保持核聚变等离子体稳定的呢?托卡马克装置研究的一个主要方向是将等离子体的分布构建成不同配置的效果,以优化稳定性、封闭性和能量排放,并为第一个燃烧等离子体实验ITER提供通知。而要在托卡马克内限制每个配置,需要设计一个反馈控制器,通过精确控制几个与等离子体磁耦合的线圈来操纵磁场,以达到理想的等离子体电流、位置和形状。这个问题也就是著名的“托卡马克磁控制问题”。在传统方法中,要解决这个时变的、非线性的、多变量的控制问题,首先要解决一个反问题,即:预先计算一组前馈线圈电流和电压,然后设计一组独立的、单输入、单输出的PID控制器,使等离子体保持垂直位置,并控制径向位置和等离子体电流,所有这些控制器在设计时也要注意不能相互干扰。大多数控制结构都会增加对等离子体形状的外部控制回路,这就需要对等离子体平衡进行实时估计,以调制前馈线圈电流。控制器的设计建立在线性化模型动力学的基础之上,需要进行增益调度以跟踪时间变化的控制目标。尽管这些控制器在大多数情况下表现不错,但每当目标等离子体配置发生变化,就需要花费大量的工程努力、设计努力和专业知识,同时还要进行复杂的平衡估计实时计算。这时,深度强化学习就派上了用场:强化学习可以作为一种全新的方法,用来设计非线性反馈控制器,可以直观地设置性能目标,将重点转移到“应该实现什么”,而不是“如何实现”。此外,强化学习技术极大简化了控制系统,计算成本低的控制器取代了嵌套的控制结构,而内部化的状态重建消除了对独立平衡重建的要求。一句话:这些优势可减少控制器的开发周期,加速对替代性等离子体配置的研究。在这个工作中,他们提出了一个由强化学习设计的磁性控制器,可以自主学习指挥全套的控制线圈,既可以实现高水平控制,也能满足物理和操作的约束条件,在生产等离子体配置时大大减少了设计的工作量。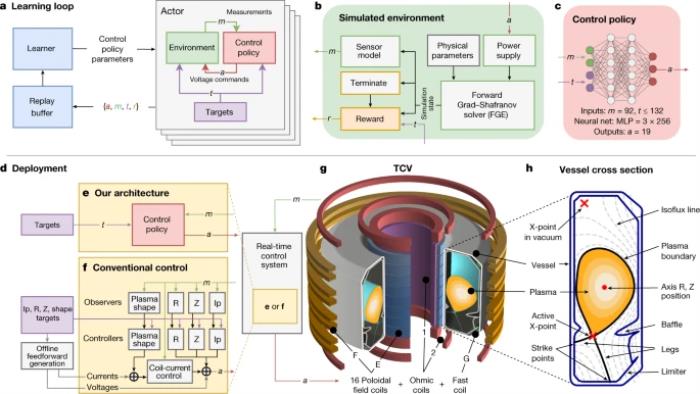
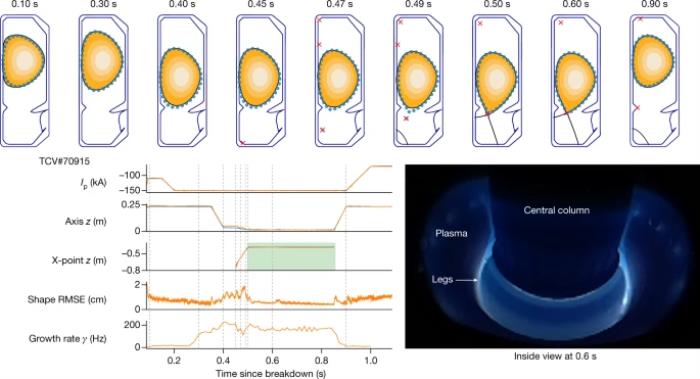 图注:通过深度强化学习,托卡马克装置中的等离子体电流、垂直稳定性、位置和形状控制情况此外,他们还介绍了TCV上的可持续“雨滴” (droplets’),其中两个独立的等离子体可同时保持在容器:
图注:通过深度强化学习,托卡马克装置中的等离子体电流、垂直稳定性、位置和形状控制情况此外,他们还介绍了TCV上的可持续“雨滴” (droplets’),其中两个独立的等离子体可同时保持在容器: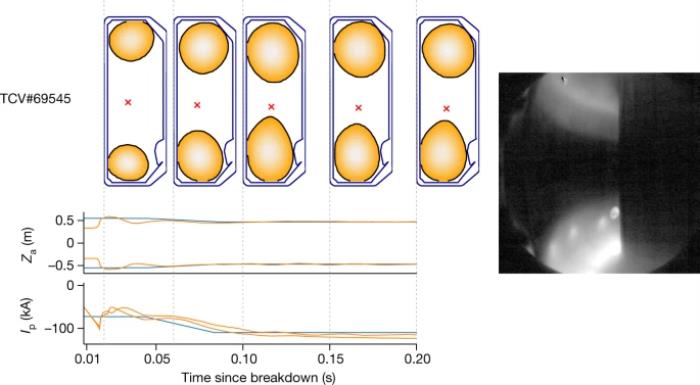 图注:在 200 毫秒控制窗口中持续控制 TCV 上的两个独立“雨滴”
图注:在 200 毫秒控制窗口中持续控制 TCV 上的两个独立“雨滴”写在最后目前为止,在可控核聚变上取得的最好成绩来自欧洲联合环状反应堆(JET),今年的2月9日,JET中的聚变反应在5秒内以中子的形式释放出总共59兆焦耳的能量——这个数值并不高,大概只能烧开几十壶开水而已。人类早已实现了输出能量小于输入能量的可控核聚变,以JET创下的世界纪录为例,其Q值(聚变能增益系数,输出能量与输入能量之比)约为0.33左右。要实现真正可用的核聚变清洁能源,需要通过新的范式的研究,不断提高核聚变的Q值。DeepMind 团队坚信:他们的深度强化学习系统为托卡马克装置中的等离子体磁约束提供了一个新的范式。更重要的是,他们的控制设计表明了基于机器学习的控制方法的优势。要实现AI+核聚变,需要科学与工程的双管齐下,硬件与算法缺一不可。他们相信,深度强化学习框架有可能塑造未来的核聚变研究与托卡马克装置的研究发展。大家怎么看?参考链接:1.https://www.zhihu.com/question/31056640/answer/568168722.https://scitechdaily.com/science-made-simple-what-is-a-tokamak/3.https://www.zhihu.com/question/41295369/answer/142572075


相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章










