新火种
2023-10-28
新火种
2023-10-28 


专注E2E语音识别,腾讯AILab开源语音处理工具包PIKA
机器之心报道
作者:魔王、杜伟
PyTorch + Kaldi,腾讯 AI Lab 开源轻量级语音处理工具包 PIKA,专注于端到端语音识别任务。
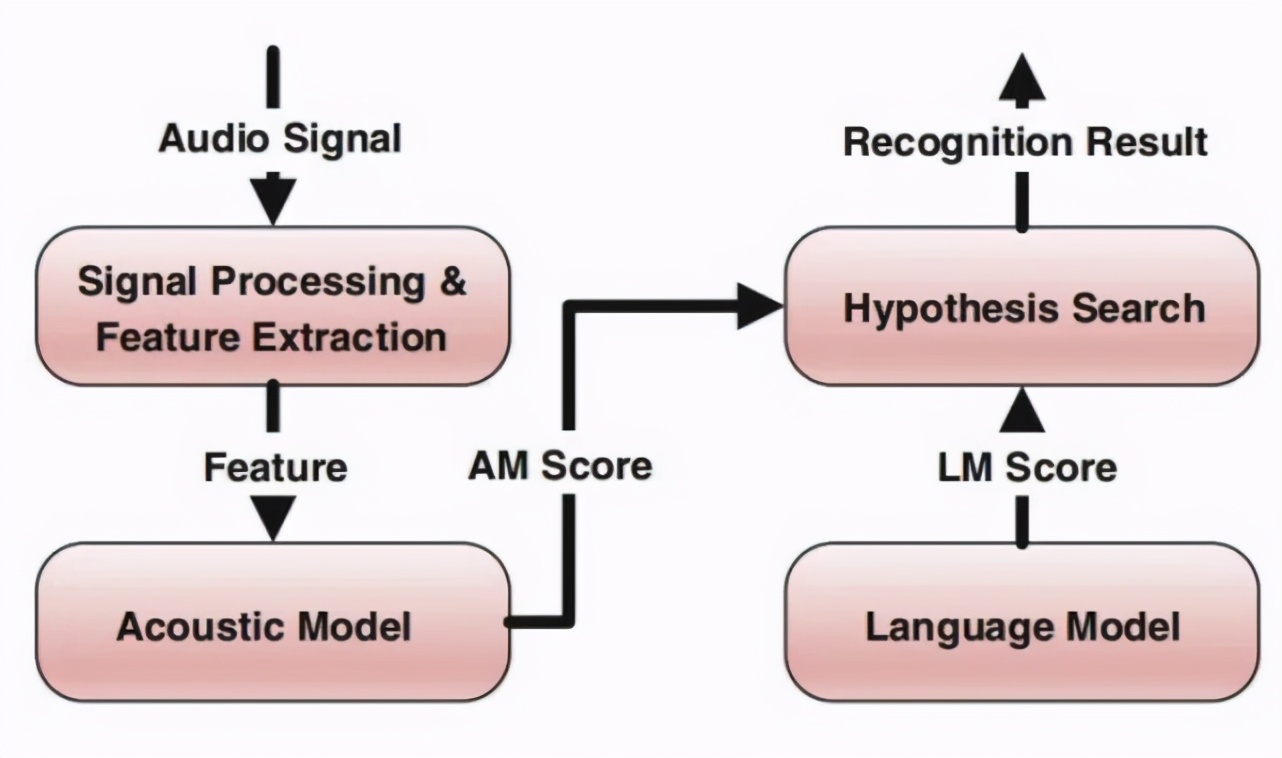
Kaldi 是一个开源的语音识别系统,由 Daniel Povey 主导开发,在很多语音识别测试和应用中广泛使用。但它依赖大量脚本语言,且核心算法是用 C++ 编写的,对声学模型的更新和代码调试带来一定难度。
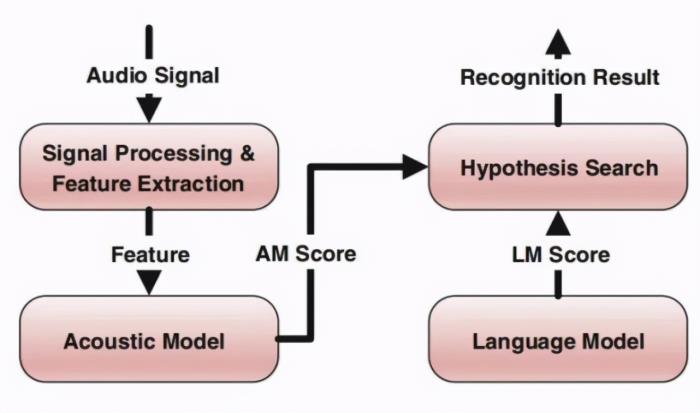
语音识别系统架构
「Kaldi 之父」Daniel Povey 表示正在打造下一代 Kaldi。去年夏天在 WAIC 开发者日上,Daniel 分享了他对下一代 Kaldi 的期望,希望能够基于 PyTorch 甚至 TensorFlow 构建语义识别模型。
学术界和业界也都在努力改进语音识别流程,加快技术迭代。此前,Yoshua Bengio 团队成员 Mirco Ravanelli 等人开发了一个新型开源框架——PyTorch-Kaldi,试图继承 Kaldi 的效率和 PyTorch 的灵活性,弥补 PyTorch 和 Kaldi 之间的鸿沟:在 PyTorch 中实现声学模型,在 Kaldi 中执行特征提取、标签 / 对齐计算和解码。
近日,腾讯 AI Lab 开源了一个基于 PyTorch 和 (Py)Kaldi 的轻量级语音处理工具包 PIKA。PIKA 首个版本专注于端到端语音识别,开发团队以 PyTorch 作为深度学习引擎,使用 Kaldi 进行数据格式化和特征提取。

项目地址:https://github.com/tencent-ailab/pika
具体而言,PIKA 具备以下特征:
即时数据增强和特征加载器;
TDNN Transformer 编码器,以及基于卷积和 Transformer 的解码器结构;
RNNT 训练和批解码;
利用 Ngram FST 的 RNNT 解码(即时重评分、aka 和 shallow fusion);
RNNT 最小贝叶斯风险(MBR)训练;
用于 RNNT 的 LAS 前向与后向重评分器;
基于高效 BMUF(块模型更新过滤)的分布式训练。
安装和依赖
PIKA 开发团队推荐使用 Anaconda,因为它包含大多数的依赖项。其他主要依赖如下:
PyTorch
用户可前往 PyTorch 官网自行安装,代码和脚本应能够在 PyTtorch 0.4.0 及以上版本运行。但为了确保与 RNNT 损失模块兼容,PIKA 开发团队推荐使用 PyTorch 1.0.0 以上版本。
Pykaldi 和 Kaldi
开发团队使用 Kaldi 和 PyKaldi(Kaldi 的 python 包装器)进行数据处理、特征提取和 FST 操作。用户可前往 Pykaldi 网站自行安装,为提升效率请确保使用 ninja 构建 Pykaldi。完成所有 pykaldi 安装流程后,Kaldi 和 Pykaldi 依赖项即准备完成。
CUDA-Warp RNN-Transducer
对于 RNNT 损失模块,开发者采用了 warp-rnnt(https://github.com/1ytic/warp-rnnt)项目中的 pytorch 绑定。
使用方法
在使用 PIKA 之前,我们需要先检查 egs 目录中的所有训练和解码脚本。
数据准备和 RNNT 训练
egs/train_transducer_bmuf_otfaug.sh 包括数据准备和 RNNT 训练。用户需要准备训练数据并指定训练数据目录:
继续 MBR 训练
有了 RNNT 训练模型后,用户可以使用 egs/train_transducer_mbr_bmuf_otfaug.sh 继续 MBR 训练(假设使用的训练数据相同,则可以省略数据准备步骤)。用户需要确保指定初始模型:
训练 LAS 前向与后向重评分器
用户可以利用 egs/train_las_rescorer_bmuf_otfaug.sh 为 RNNT 模型训练 LAS 前向与后向重评分器。LAS 重评分器将与 RNNT 模型共享编码器部分,并使用两层 LSTM 作为额外的编码器。用户需要确保指定编码器共享:
该工具还支持双向 LAS 重评分,即前向与后向重评分。后向重评分(自右至左)通过训练 LAS 模型时反转序列标签来实现。通过以下代码,用户可以轻松执行 LAS 后向重评分训练:
解码
egs/eval_transducer.sh 是主要的评估脚本,包含解码 pipeline。指定以下两个模型可以实现 LAS 前向与后向重评分:
PIKA 工具包中的所有训练和解码超参数都基于大规模训练和内部评估数据。用户可能需要调参以获得最优性能。此外,WER (CER) 评分脚本基于中文普通话任务,处理不同语言的用户可以重写评分脚本。
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章