新火种
2023-09-09
新火种
2023-09-09 


网易云信神经网络音频降噪算法:提升瞬态噪声抑制效果
网易云信音频实验室自主研发了一个针对瞬态噪声的轻量级网络音频降噪算法(网易云信 AI 音频降噪),对于 Non-stationary Noise 和 Transient Noise 都有很好的降噪量,并且控制了语音信号的损伤程度,保证了语音的质量和理解度。

基于信号处理的传统音频降噪算法对于 Stationary Noise(平稳噪声)有比较好的降噪效果。但是对于 Non-stationary Noise(非平稳噪声),特别是 Transient Noise(突发噪声)降噪效果较差,而且有些方法对于语音也有较大的损伤。随着深度学习在 CV(Computer Vision)上的广泛应用,基于神经网络的音频降噪算法大量涌现,这些算法很好的弥补了传统算法对于 Non-stationary Noise 降噪效果不好的问题,在 Transient Noise 上也有较大的提升。
但是,基于神经网络的音频降噪在计算复杂度上存在挑战。虽然我们生活中的终端设备的计算能力在不断提升,比如个人笔记本、手机等,但是大模型的深度学习算法,很难在绝大部分设备(特别是不含 GPU 的设备)上运行。目前也有一些开源的、基于神经网络的低开销降噪算法[1,2,3],能够在大部分终端设备上达到实时运行的标准。但是这些算法的运算量对于 RTC(实时通信)的 SDK 依然太大,其原因是 SDK 中包含了大量算法,每个子算法的开销都必须严格把控,才能保证整个 SDK 的运算开销在一个合理范围,并且能够在大部分终端设备上运行。
针对上述挑战,网易云信音频实验室自主研发了一个针对瞬态噪声的轻量级网络音频降噪算法(网易云信 AI 音频降噪),对于 Non-stationary Noise 和 Transient Noise 都有很好的降噪量,并且控制了语音信号的损伤程度,保证了语音的质量和理解度。与此同时,云信的 AI 音频降噪将计算开销控制在一个非常低的量级,达到了和传统算法接近的计算量,比如 MMSE [4]。目前,网易云信的 AI 音频降噪已经成功落地在其自研的新一代音视频技术架构(NERTC)中,在大幅提升降噪效果的同时,也在大多数终端机型上成功应用,包括了大部分中低端机型。
本文介绍的内容,即网易云信音频实验室发表于 INTER-NOISE 2021 的《A Neural Network Based Noise Suppression Method for Transient Noise Control with Low-Complexity Computation》一文,本篇文章详细介绍了在基于深度学习的音频降噪算法中,如何在低计算开销的情况下,实现对不同噪声,包括 Transient Noise 的抑制。
方法
在介绍算法细节之前,我们需要先在数学上来构建一下问题模型。在公式(1)中,x (n) 、s (n) 、和 d (n)分别代表带噪信号、干净语音信号和噪声信号。

带噪信号x (n)代表麦克风在实际场景中所收集的信号,其中n代表时域采样点。我们对公式(1)做一个 STFT(短时傅里叶变化)得到(2),

其中
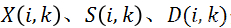
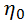

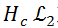
特征表示
为了要实现低计算量的目的,我们需要最大限度的去压缩模型大小,这样必然导致在同等状况下,压缩后模型的表现会更差。为了弥补模型变小后带来的效果下降,该研究从输入特征(Input Feature)入手,选择更能代表语音特性的特征,从而去区分语音和噪声。当然特征大小(Feature Size)也需要严格控制,共同保证低计算量的要求。现在开源的单通道深度学习降噪算法中,比较普遍的 Feature 是用信号的 Magnitude 和 Phase,或者直接用频域信号的 Complex Value。这样的做法好处是可以保证模型能获得所有的频域信息,没有任何信息丢失;但是缺点是这些频域信息对于语音信号和噪声信号的分离度不够,而且输入的参数量偏大。方法 [1] 中用到了 Pitch Correlation(基音相关性),
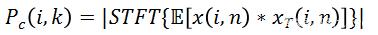
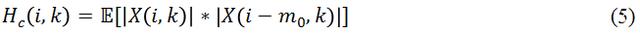
其中
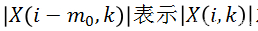
另外一个和
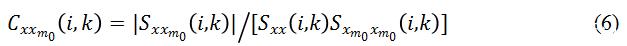
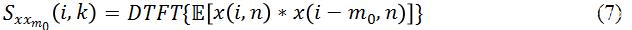
可以看出,Coherence 也可以突出信号中的谐波信息,不同之处在于它也是基于时域的相关性,而且增加了归一化处理。
损失函数
Valin 在 [1] 中提出了一种损失函数,
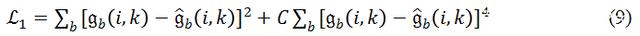
其中
在研究过程中研究发现,虽然
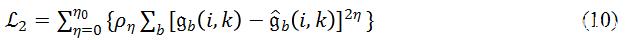
在
学习模型以及实时处理
该研究沿用了 [1] 中 RNN-GRU 模型,原因是 RNN 相比其他学习模型(例如 CNN)携带时间信息,可以学习到数据中前后在时序上的联系。该研究认为这种联系在语音信号上非常重要,特别是在一个实时的、帧长相对较短的语音算法中。模型的结构如 Fig.1 所示。训练后的模型会被嵌入网易云信的 SDK 中,通过读取硬件设备的音频流,对 Buffer 进行分帧处理并送入 AI 降噪预处理模块中,预处理模块会将对应的 Feature 计算出来,并输出到训练好的模型中,通过模型计算出对应的 Gain 值,对信号进行调整,最终达到降噪效果(Fig.2)。
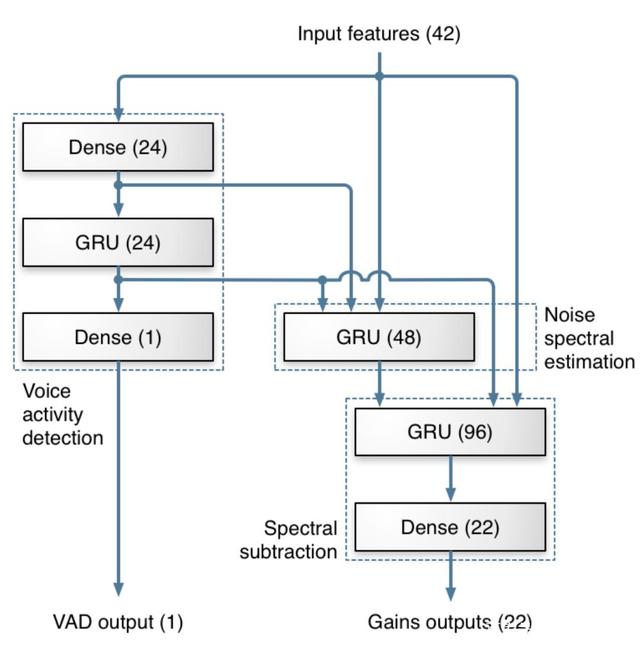
Figure 1: GRU模型。
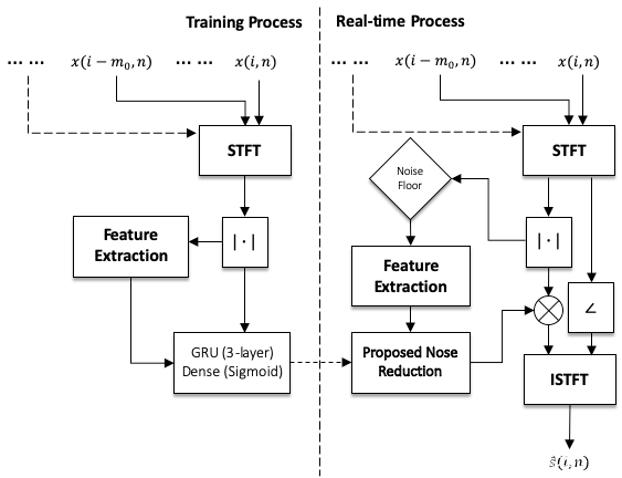
Figure 2: 训练和实时处理框图。
测量结果和讨论
在测试阶段,该研究首先建立了和 Training/Validation 完全不同的一个测试集。在对比项上,选择了 [4] 作为传统信号处理的降噪算法代表。在基于深度学习的算法中,研究者首先选择了 RNNoise[1],以此来评估优化所带来的效果提升。其次,该研究选择了 DNS-Net[2]和 DTLN[3]当下两个热度很高的实时 AI 降噪算法来作为对比项。
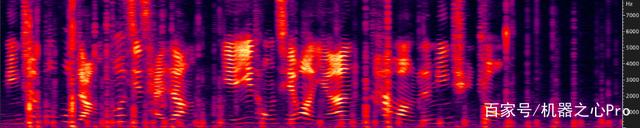
(a)Noisy signal (5dB SNR)


Fig.3 展示了一段 Keyboard Noise 下的降噪前后对比。Keyboard Noise 作为 Transient Noise 中的一种,是在 RTC 场景中非常容易遇到的噪声。比如在一个在线会议中,会议中的任意一位参会者在用键盘记录会议信息时,都会让这个会议陷入键盘噪声中。Fig.3 展示的是在 5dB SNR 场景下的情况。从图中可以看出,网易云信 AI 降噪在非语音部分,对键盘噪声的压制极大,基本全部消掉;在和语音重合部分,虽然没有完全消掉,但是也有明显抑制,并且保护了语音质量。
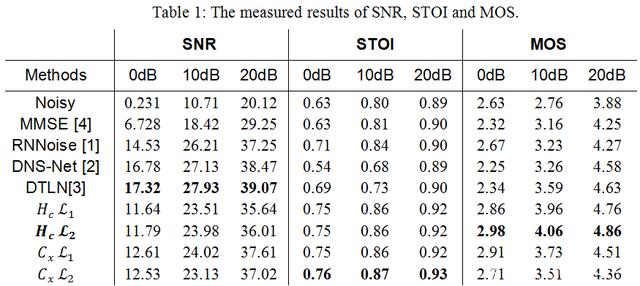
在 RTC 场景中,当降噪后 SNR 达到 20dB 以上,3-4dB 的差值对于听感来说差异较小。所以该研究在调试中把降噪量稳定在一个范围内,然后尽量去追求更高的语音理解度(STOI[5])和语音质量(MOS[6])。Table 1 展示了云信 AI 降噪和对比项之间的量化对比。从结果中可以看出,网易云信自研的 Feature 和 Loss Function 在整体上呈现对语音保护更好,降噪量略小。其中,
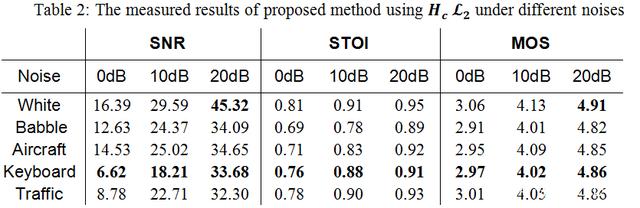
网易云信的 AI 降噪在 10ms 的音频帧数据(16kHz 采样率)中只需要约 400,000 次浮点计算,经过云信自研的 AI 推理框架 NENN 加速,在 iPhone12 上每 10ms 的运算平均时间低于 0.01ms,峰值时间低于 0.02ms,CPU 占比小于 0.02%。
总结
综上所述,网易云信 AI 降噪实现了一个轻量级的实时神经网络音频降噪算法。它在 Stationary 和 Non-Stationary Noise 上都有很好的效果,对于业界的难点 Transient Noise 也有很好的抑制效果;与此同时,相较同类 AI 降噪算法,云信 AI 降噪对语音质量有着更好的保护。
自成立以来,网易云信音频实验室除了保障产品的算法研发和优化需求之外,已提交专利数十项。接下来,网易云信音频实验室将在基础算法、模型方面加强研究,结合具体行业和应用场景,以技术创新引领产品创新。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章