新火种
2023-10-20
新火种
2023-10-20 


华为的大模型终于来了,我的评价是:相当震撼

老被人说在大模型竞赛中掉队的华为,这次终于带着它的家伙事儿来了。
这不,在昨天的华为开发者大会 2023 上,华为就狠狠地秀了一把。
将近三个小时的发布会,还是继承了华为以往大杂烩的风格,看得世超是眼花缭乱。
不过,总结下来其实也就突出了一个主题:盘古大模型 3.0 。

其实就在前几天,当别的大模型还在比各种评分的时候,盘古靠着世界顶级期刊 Nature 认证的金字招牌,以一种别具一格的方式进入了大家的视野。

据说,加入了盘古大模型,气象预测的速度提高了 10000 倍以上,几秒钟就能出结果,台风打哪来,几点来,啥时候走,都能给你预测得明明白白的。
最主要的是,它的预测精度甚至超过了号称全球最强的欧洲气象中心的 IFS 系统,算是头一个 AI 预测赢了传统数值预测的产品。
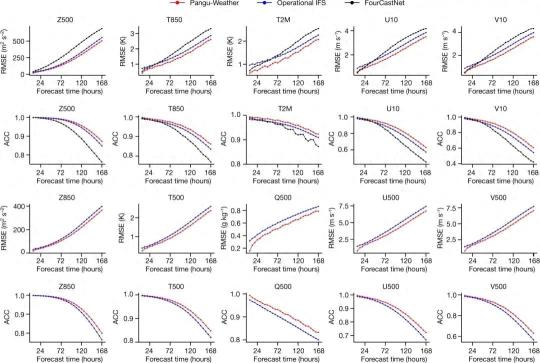
要知道,以往的 AI 气象预测多是基于 2D 神经网络开发,但气象这玩意实在是太复杂了,2D 着实有点儿吃不消。
而且,之前的 AI 模型会在预测的过程当中不断累计迭代的误差,容易影响到结果的精确性。
所以 AI 预测方法一直都不咋受待见。
而盘古气象大模型牛就牛在,他们用了个叫 3DEST 的三维神经网络来处理气象数据, 2D 干不了的那就换 3D 来。
3DEST 的网络训练和推理策略
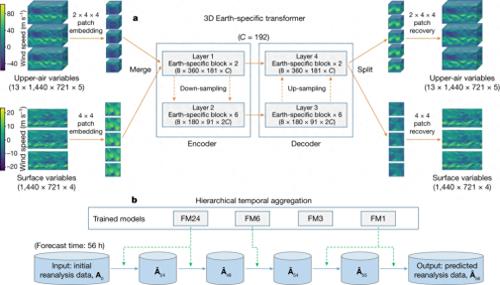
针对迭代误差的问题,模型还用了个 “ 层次化时域聚合策略 ” 来减少迭代误差,从而提高预报的精度。
这词儿虽然听起来挺容易被唬住的,但其实很好理解。
就比如,之前的 AI 气象预测模型 FourCastNet ,在台风来之前,它会提前 6 小时进行预测,在这 6 个小时里,模型会多次计算台风到底啥时候来。
可能一会儿算出来 5 个小时,一会儿又算出来 4 个半小时,这些结果加到一起误差就大了。
但盘古气象大模型想了个法子,训练了 4 个不同预报间隔的模型,分别是 1 小时迭代 1 次,还有 3 小时、 6 小时和 24 小时迭代 1 次。
再根据具体的气象预测需求,选择相应的模型进行迭代。
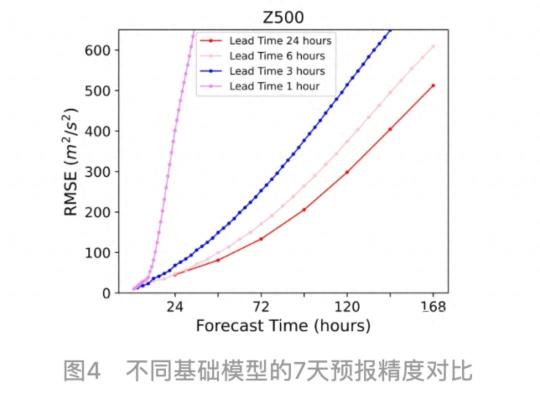
就比如说,咱们如果要预测未来 7 天的天气,那就让 24 小时的模型迭代 7 次;预测 20 个小时就是 6 小时的模型迭代 3 次 +1 小时的迭代 2 次。
迭代次数越少,误差也就越小。
这波操作,让天气预报又迈向了一个新的 level 。
不过,可能有差友开始犯嘀咕了,人家的大模型都是生成图像和文字,怎么到华为这就变成了天气预报了?
有一说一啊,这盘古大模型跟咱之前接触到的 ChatGPT 、 Midjourney 的确不太一样,人家做的是行业的生意。

简单来理解,就是盘古大模型咱个人一般用不上。
它并不是大家期待的 ChatGPT“ 克星 ” ,而是针对平时不太能接触到的To B 市场。
咱先不提难与不难,至少华为这么多年积累下来的企业客户资源,确实很容易变现。
而且华为这次的发布会可不止带来了气象预测模型这一个狠角色。
40 多年都没发现新的抗生素,盘古药物分子大模型一来就找着了超级抗菌药 Drug X ,而且药物的研发周期从数年缩短至几个月,研发成本降低 70% 。
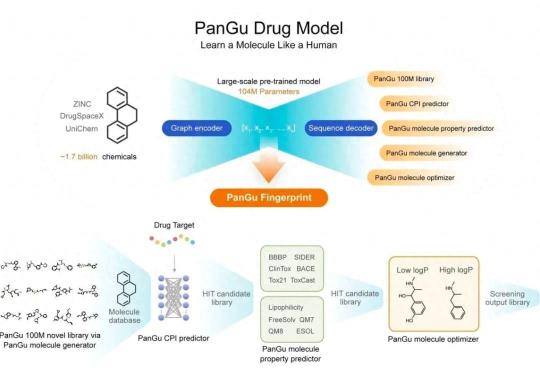
盘古矿山大模型也能深入到采煤的 1000 多个工序之中,而且光是里头挑选精煤的这一个环节,就能让精煤回收率提升 0.1% 到 0.2% 。
要知道,一家年产 1000 万吨焦煤的选煤厂,每提升 0.1% 精煤产率,每年就能多 1000 万的利润。
这可都是白花花的银子啊。。。
事实上,除了上边儿咱提到的天气预测、药物研发和选煤,盘古大模型在很多行业里都已经用起来了。

发布会上,华为云人工智能首席科学家田奇就表示,华为云人工智能项目已经应用在了超过 1000 个项目中,其中 30% 用在客户的核心生产系统里,平均推动客户盈利能力提升了 18% 。
而华为能够量产这些各不相同的行业大模型,要归功于华为盘古大模型 3.0 的 5+N+X 三层架构。

正是这种结构,让盘古能够快速落地到各个行业里。
为什这么说呢?
因为 AI 落地行业,数据是一大难点。
张平安在发布会上就说, “ 由于行业数据获取难,技术与行业结合难,大模型在行业的落地进展较慢。 ”
而盘古则很巧妙,通过 5+N+X 的三层架构,直接把这个大难题拆成了 3 个小问题来解决。
首先,是先让盘古 L0 层的 5 个大模型,学习了上百 TB 的百科知识、文学作品、程序代码等文本数据,以及数 10 亿张带文本标签的互联网图像。

咱们可以理解为,先让第一层 L0 的大模型( 自然语言大模型、视觉大模型、多模态大模型、预测大模型、科学计算大模型这 5 个基础大模型 )建立起基本的认知,也就是有点像咱们大学前的素质教育阶段。
然后,在第二层 L1 中的模型,则是让 L0 中的某一个基础大模型学习 N 个相关行业的数据形成的。这就像大学的本科阶段,需要选择各种专业去学习。

打个比方,医院里的 CT 影像检测跟工厂的图像质检虽说用的都是视觉大模型。
但毕竟一个是医院,一个是工厂,使用场景完全不一样,光靠基础大模型那肯定行不通,但如果把行业数据加进去,可能就有惊喜了。

最后的 L2 ,则类似研究生,会在具体行业的基础上再细化到某个场景。比如在仓储物流行业里,货物的运输、入库、出库可能都需要用到不一样的部署模型。
与此同时呢,华为还在里头加入一个反馈环节,有点进公司实习内味了。
根据他们的说法,过去开发一个 GPT-3 规模的行业大模型,通常需要 5 个月;而有了这套东西,开发周期能缩短至原来的 1/5 。
同时很多行业数据集小的限制也能被解决。比如造大飞机这种很细很细的行业,也能有大模型。

除了这一套大模型,华为这次还提出了个非常有意思的东西——算力国产化。
众所周知,咱们在 AI 算力方面,确实是比较尴尬。
一来, AI 行业的核心设备英伟达的 H100/A100 咱们买不到,二来,即使英伟达 “ 贴心 ” 出了平替 H800 ,但是也有所保留。比如,在传输速率上就砍了不少。
在大模型动辄几个月训练时间的背景之下,这就很容易被算力更强的国外同行弯道超车。
而这一回,针对这个问题,华为还是掏了些真家伙出来的。
比如,在纸面性能上,华为的昇腾 910 处理器已经够上了英伟达 A100 。
不过实际应用起来,还是有一些差距的。而且 A100 这也不是英伟达的终极武器。
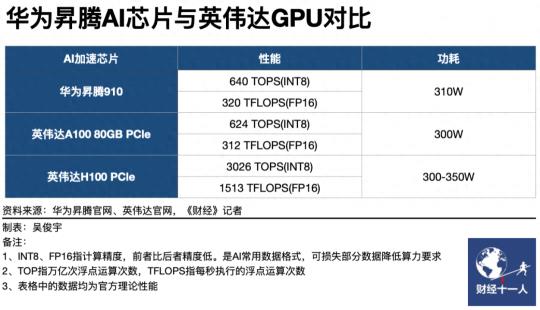
但是,昇腾已经受到了不少友商的认可。华为甚至在发布会上,直接表示 “ 中国一半大模型的算力都是由他们提供的 ” 。

当然,华为这会儿在算力上的亮点,更像是整个软件生态带来的。
比如,根据发布会的说法,算上 AI 昇腾云算力底座、计算框架 CANN 。。。等环节,华为在训练大模型方面,效率是业界主流 GPU 的 1.1 倍。

还有,他们给用户制定好了全套的应用套餐。

例如,美图仅用 30 天就将 70 个模型迁移到了华为生态。同时华为还表示,在双方的努力下,AI 性能较原有方案提升了 30% 。
还是挺可观的。
而且华为还说,他们现在有近 400 万的开发者,这个数量,是和英伟达 CUDA 生态对齐了。
这一系列的动作,算是把短板补上了一部分。
总的来说,一场华为发布会看下来,差评君觉得华为在 AI 方面的布局是很深刻的,他们早就开始思考 “AI 真正能带给我们什么 ” 这个问题了。
过去半年里, AI 行业虽然掌声雷动,但是真正落到行业层面,多少有些尴尬。
而华为的这一次动作,恰好印证了如任正非说的:
“ 未来在 AI 大模型方面会风起云涌的,不只是微软一家。人工智能软件平台公司对人类社会的直接贡献可能不到 2% , 98% 都是对工业社会、农业社会的促进。 ”
AI 领域,真正的大时代还在后头。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章