

 新火种
2024-01-30
新火种
2024-01-30 


深度解析!ControlNet模型的工作原理与应用场景(附案例解析)
一、川言川语
大家好,我是言川。本期文章是 2024 年的第一篇文章,也是 2023 年农历的最后一篇文章。截至这篇文章完成时,距离春节也只有最后一周的时间了,我无法单独向支持我的朋友们传达祝福之意。所以在本篇文章的开头,向大家说一些祝福之词:
2024 年,祝大家在新的一年里事业有成,大展宏图,前程似锦。同时在事业之外,祝大家健康、快乐以及幸福。
2024 年,辰龙年,祝大家龙飞凤舞,事业腾飞;祝大家金龙献瑞,好运连连;祝大家龙年吉祥,幸福安康。
最后,新年快乐,准备准备回家吃饺子咯~

二、生成式 AI 回顾
开始我们本篇文章的主题吧。生成式 AI 开始在国内爆发的时间是 2023 年 2 月底(炒的最热阶段),当时是在的 ChatGPT 引领下,一众 AI 生成式工具被我们所知晓。在图像生成领域,最为出名的几个工具是 Midjourney、StableDiffusion 和 Dall -E3。
尽管当时 Midjourney V4 版本模型生成的图片质量已经是非常的惊艳,但是还远远没有让大多数设计师引起足够的重视,原因也很简单,对于设计师来说,可商业化的工作流才是核心。
直到在 2023 年 3 月中下旬时,StableDiffusion 的教程开始如雨后春笋般拔地而起,相信你一定看到过类似的教程:二次元线稿上色、模特换装、二维图像转三维等等。这相比于 Midjourney 给设计师们带来的惊艳,StableDiffusion 的这些操作可谓是震惊了设计圈,让会 AI 和不会 AI 的设计师们都坐不住了,当然也包括我。之后我也是赶紧开始投入 StableDiffusion 的研究中。
而这一切都得益于一个插件:Controlnet。它可以对图像进行精准控图,相比于 Midjourney,它似乎更适合大多数设计场景。

以上为个人观点,不喜勿喷
在 StableDiffusion 设计中几乎每一个商业场景都离不开 Controlnet 插件的加持,对此我想再写一篇 Controlnet 详细教程,本篇教程会详细的介绍大部分常用的 Controlnet 模型,如果你还不知道如何操作使用 Controlnet,我建议你看看我在 2023 年 5 月份写的这篇文章:

三、Controlnet 模型详解
1. 电脑配置单
在正式开始我们 controlnet 的讲解之前,我为大家准备了 3 套不同的电脑配置单。
之前也有大部分的朋友都来问我,如何搭配一台能玩 StableDiffsion 的电脑。所以在本篇文章中我就直接公布出来,只作为建议参考。
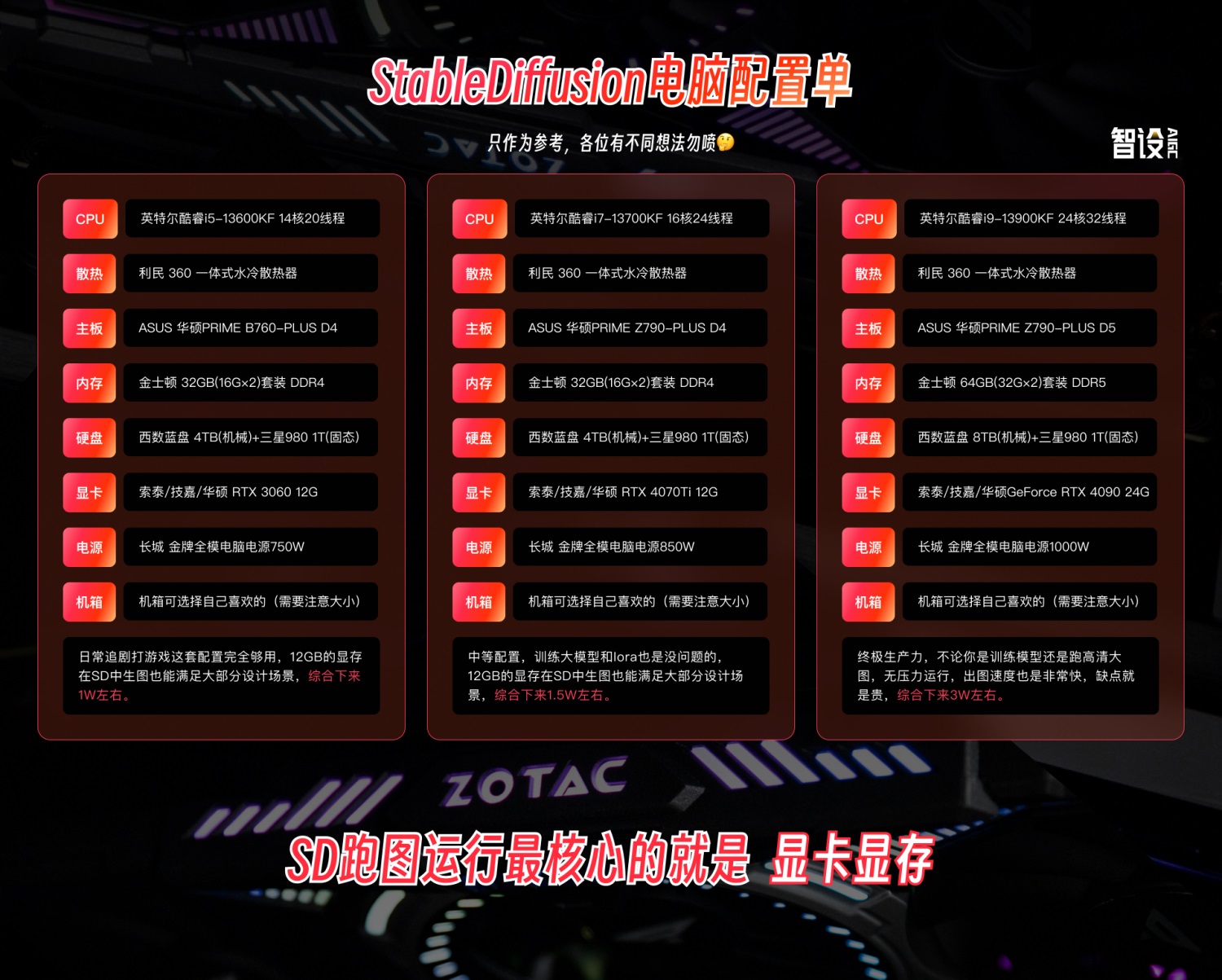
其实能稳定的运行 StableDiffsion 进行生图,最重要的配置就是显卡显存,我们在使用 controlnet 的时候,也会加大显存的占用,所以最核心的就是显存。其他配置都是围绕着该显卡进行搭配,毕竟要使显卡能完美的发挥出它的性能,其他配置也得跟上。
2. 官方模型
目前最新的controlnet模型分为ControlNet 1.1模型和ControlNet XL模型。
ControlNet 1.1模型支持基于SD1.5、2.1训练的大模型上。而ControlNet XL模型支持基于SD XL训练的大模型上。
它们虽然是属于两个不同版本的模型,但是使用方法和原理都是一样的。所以本文只介绍ControlNet 1.1模型,Controlnet XL模型大家对应着预处理器和模型看即可。
目前 ControlNet 1.1 官方发布的模型有 14 个模型,其中包含 11 个完整模型以及 3 个测试模型。下面我就开始详细介绍一下这些模型的作用。
以下所有的模型演示案例,固定参数为:
负面关键词用大家常用的模板即可;迭代步数 30、采样方法 DPM++ 2M Karras;尺寸与上传 controlnet 图一致
①ControlNet 1.1 Depth
Stable Diffusion的深度图模型文件:control_v11f1p_sd15_depth.pth
介绍:生成一张立体深度图,白色越亮的地方越靠前,越灰的地方越靠后,记录原图的空间信息,可作用在生成图上,如下图。

实操案例:
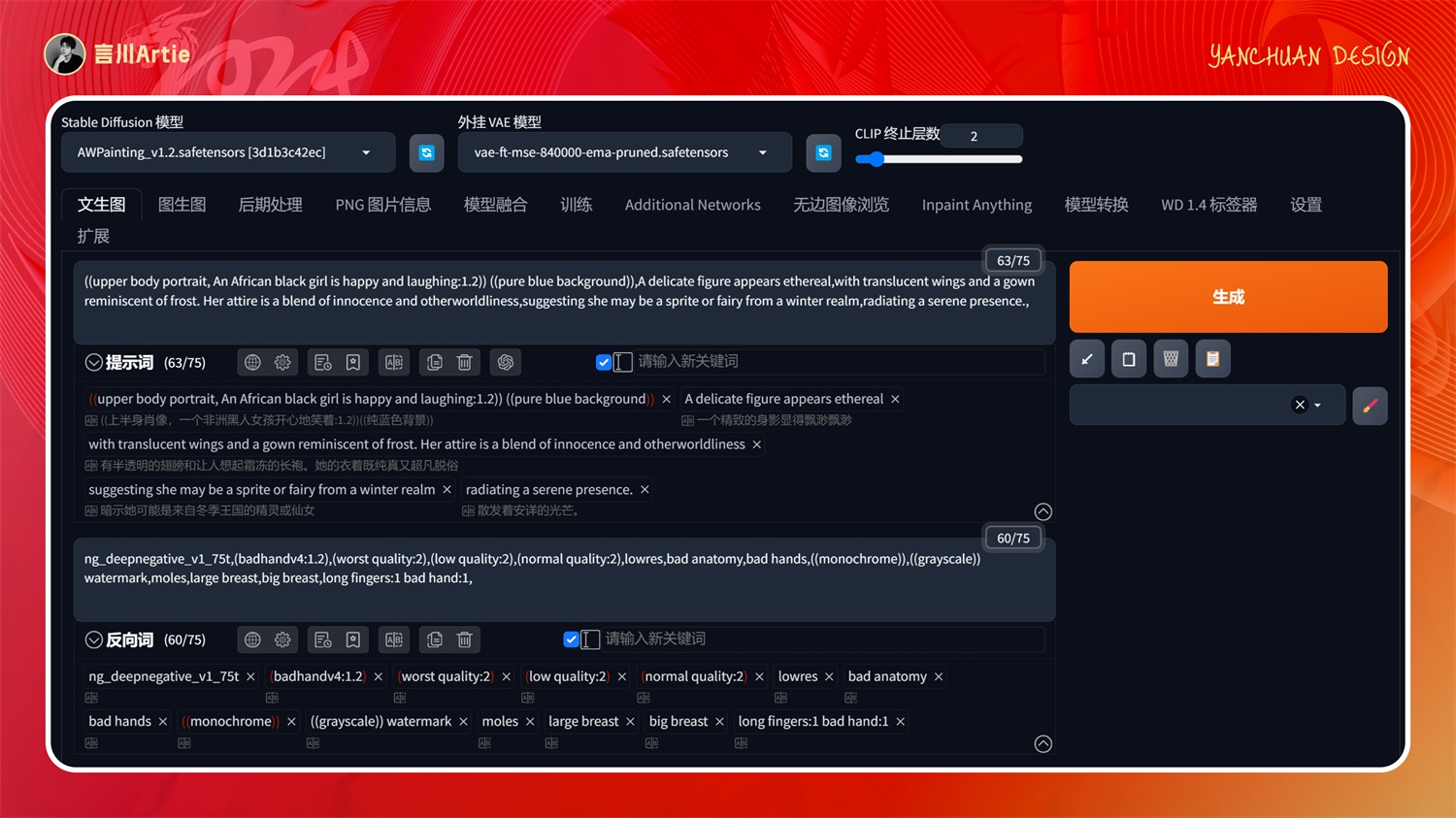
大模型:AWPainting_v1.2.safetensors
正向关键词:((upper body portrait, An African black girl is happy and laughing:1.2)) ((pure blue background)),A delicate figure appears ethereal,with translucent wings and a gown reminiscent of frost. Her attire is a blend of innocence and otherworldliness,suggesting she may be a sprite or fairy from a winter realm,radiating a serene presence.,
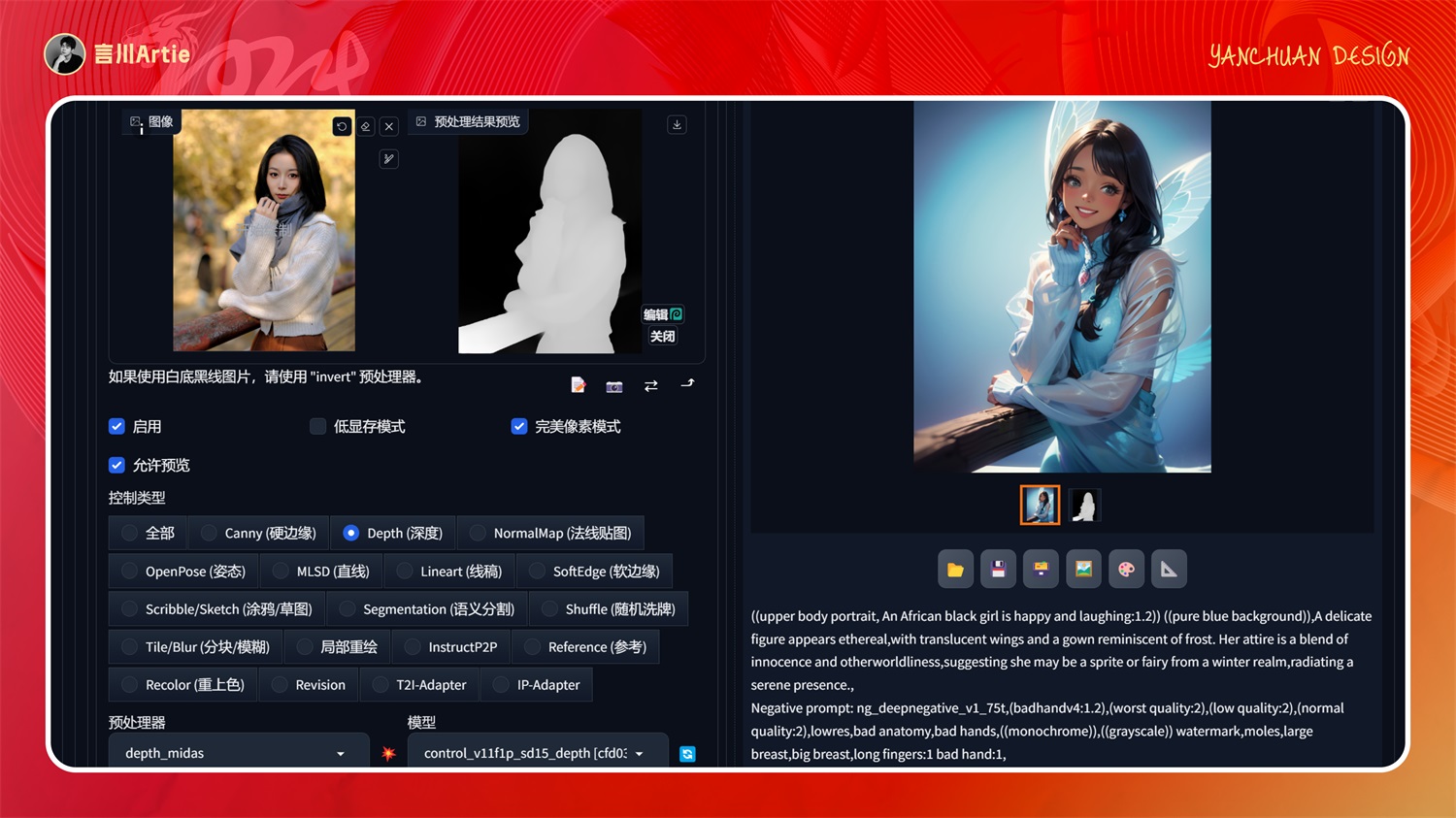
上传原图,并且使用 Depth midas 预处理器,切换 depth 模型,保存默认的 controlnet 设置,即可通过深度图生成一张与原图人物姿势类似的图。人物细节和图片风格可以通过大模型和关键词控制。
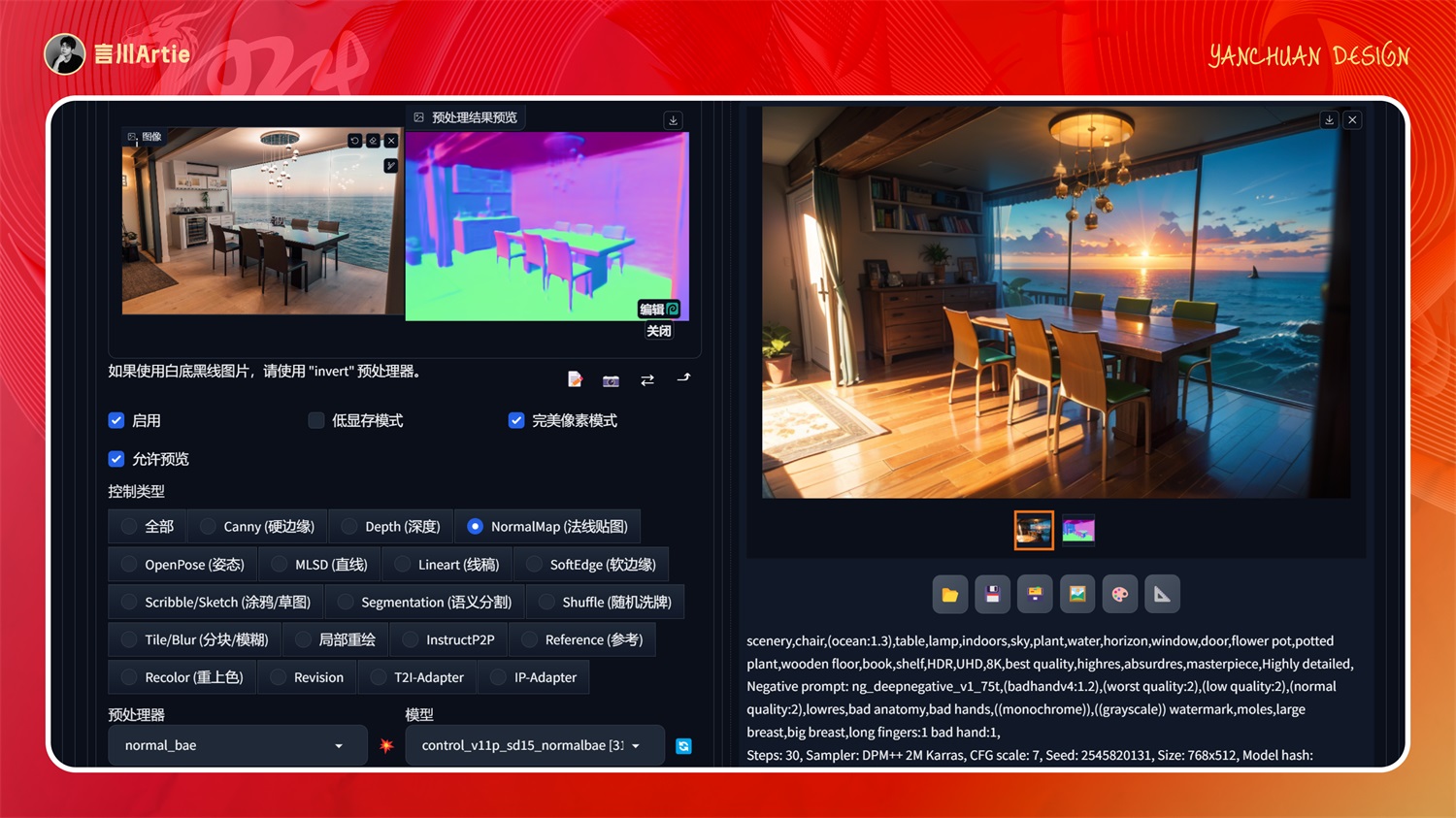
②ControlNet 1.1 Normal
使用法线图控制Stable Diffusion模型文件:control_v11p_sd15_normalbae.pth
介绍:与 depth 类似,预处理出来的图片在 3D 里叫法线贴图。通过凹凸的法线贴图记录空间信息,适合细节信息比较多的图片。
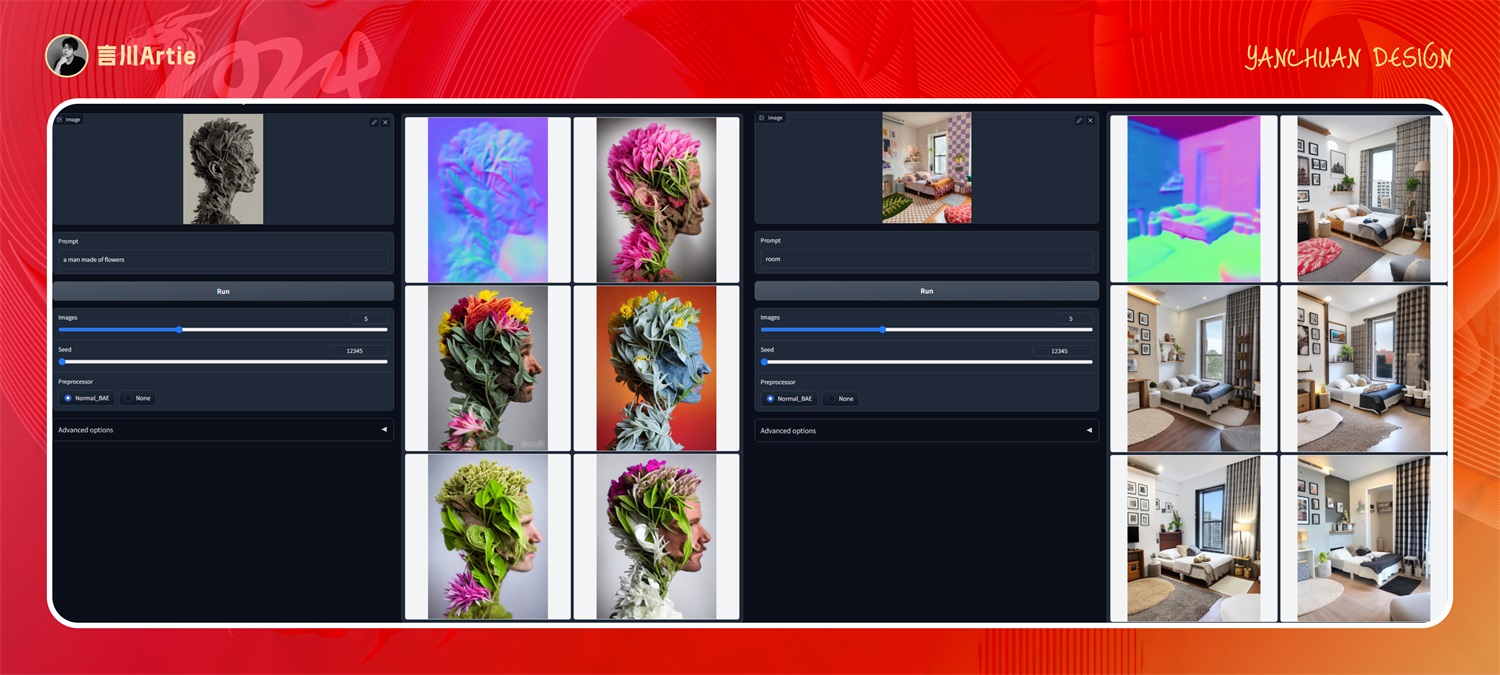
实操案例:
大模型:AWPainting_v1.2.safetensors
正向关键词:scenery,chair,(ocean:1.3),table,lamp,indoors,sky,plant,water,horizon,window,door,flower pot,potted plant,wooden floor,book,shelf,HDR,UHD,8K,best quality,highres,absurdres,masterpiece,Highly detailed,
上传真实的室内设计场景,通过 Normal 模型获取原图的空间信息和物体信息,用二次元风格的大模型即可完成图片风格的次元转换,Normal 的控制效果可谓是非常精准了。
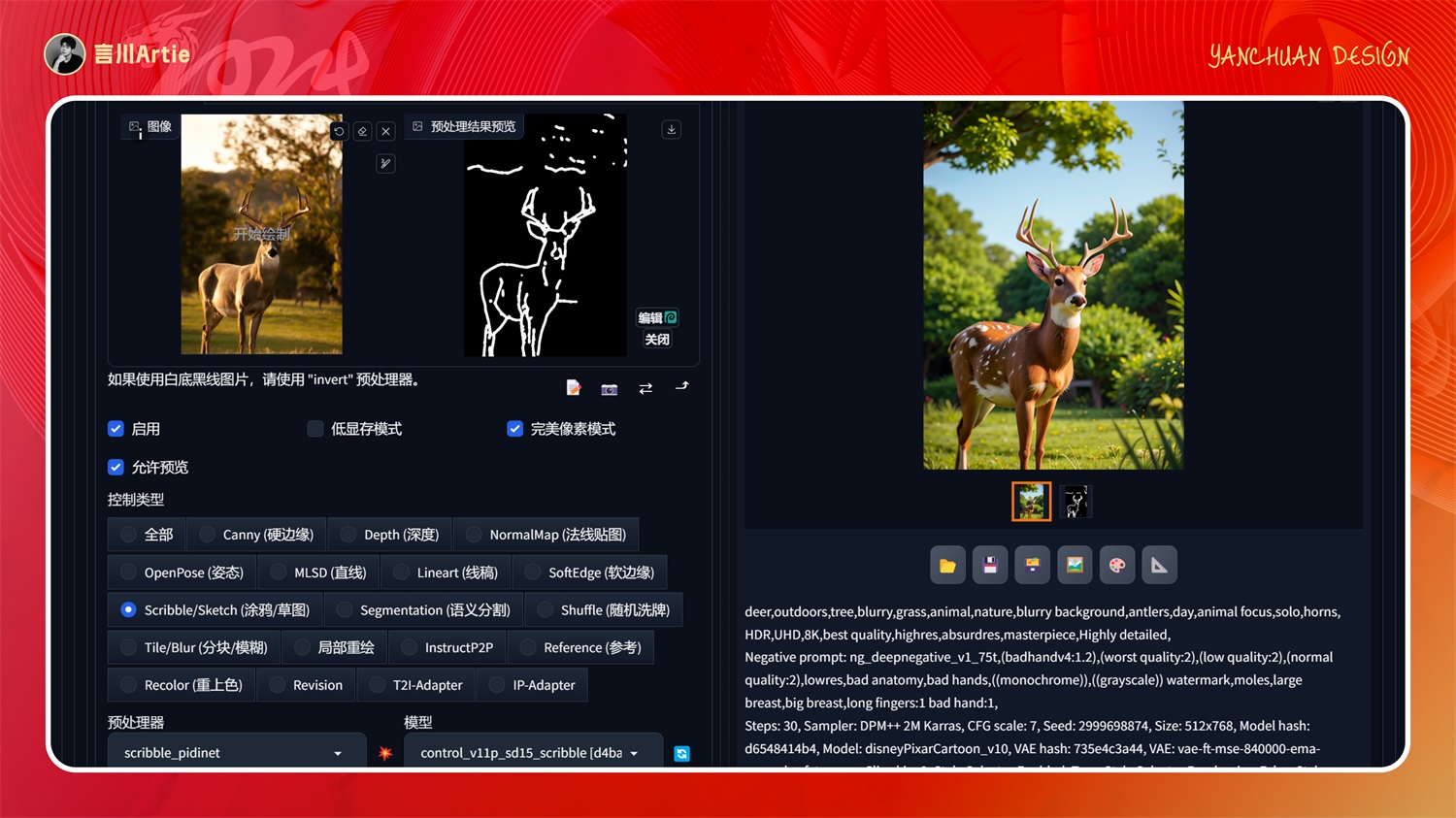
③ControlNet 1.1 Canny
使用Canny图控制Stable Diffusion模型文件:control_v11p_sd15_canny.pth
介绍:提取图片中物体的轮廓线,AI 根据提取的轮廓重新生成一张与原图细节类似的图片。
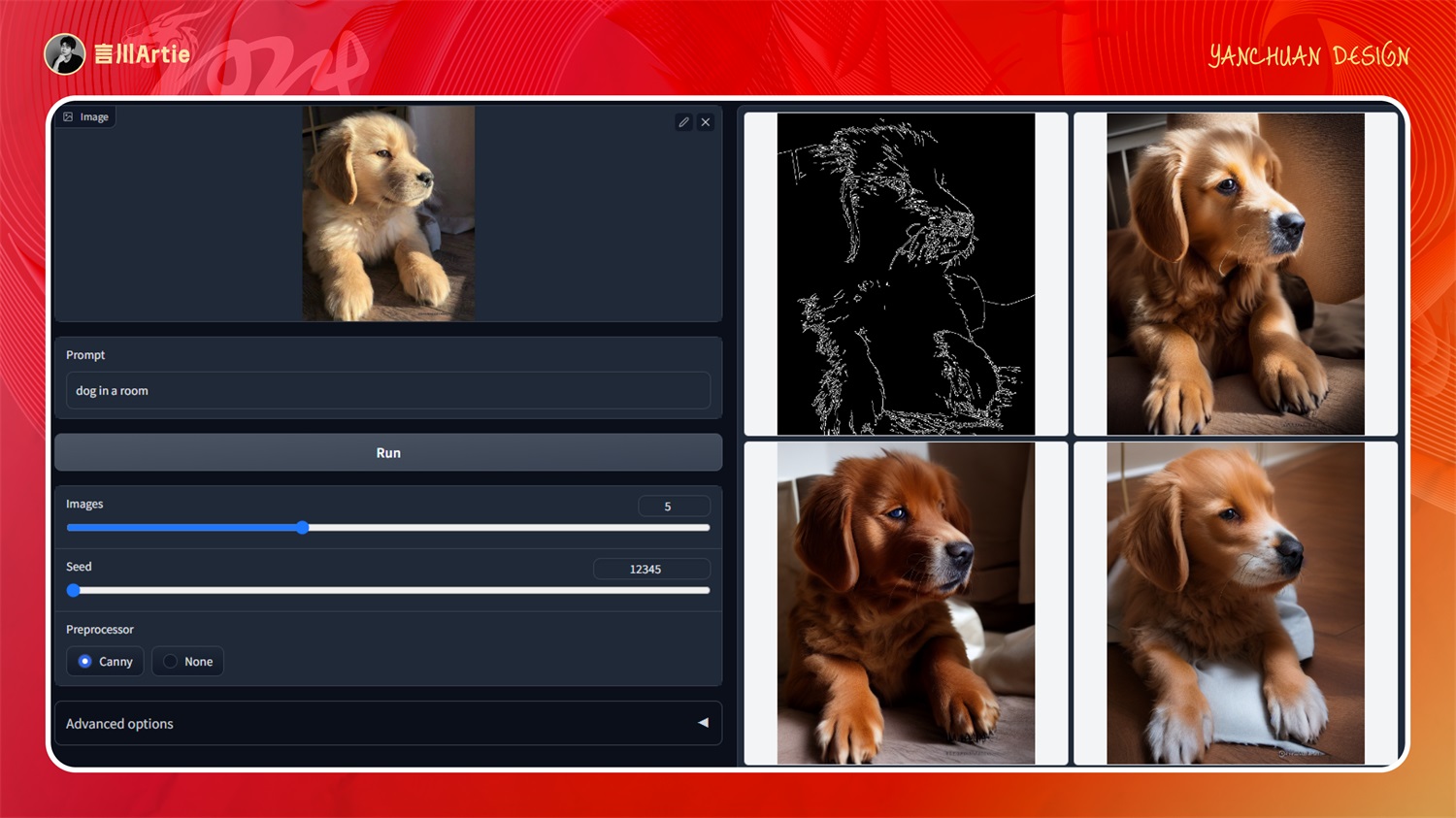
实操案例:
大模型:disneyPixarCartoon_v10.safetensors
正向关键词:deer,outdoors,tree,blurry,grass,animal,nature,blurry background,antlers,day,animal focus,solo,horns,HDR,UHD,8K,best quality,highres,absurdres,masterpiece,Highly detailed,
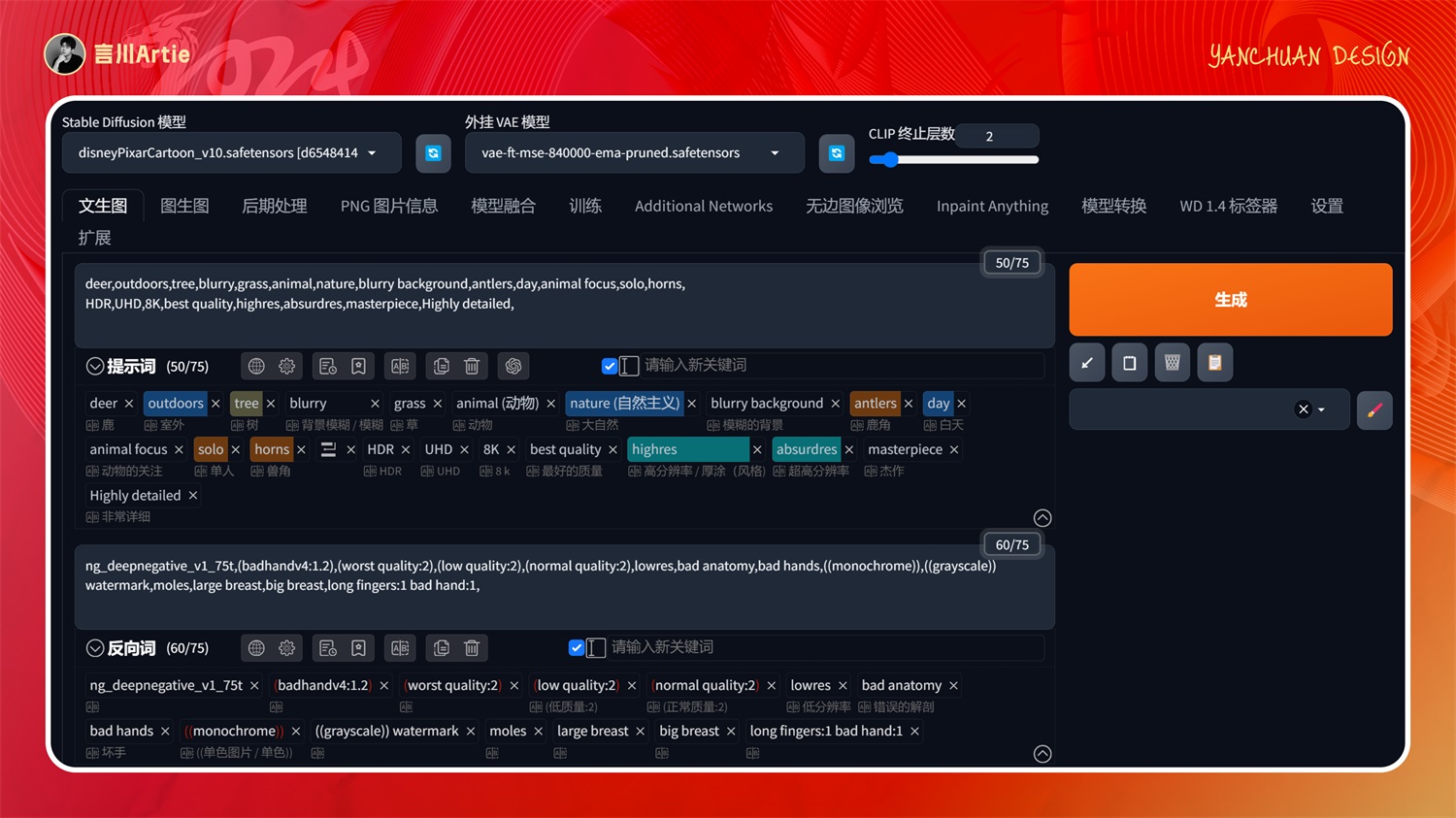
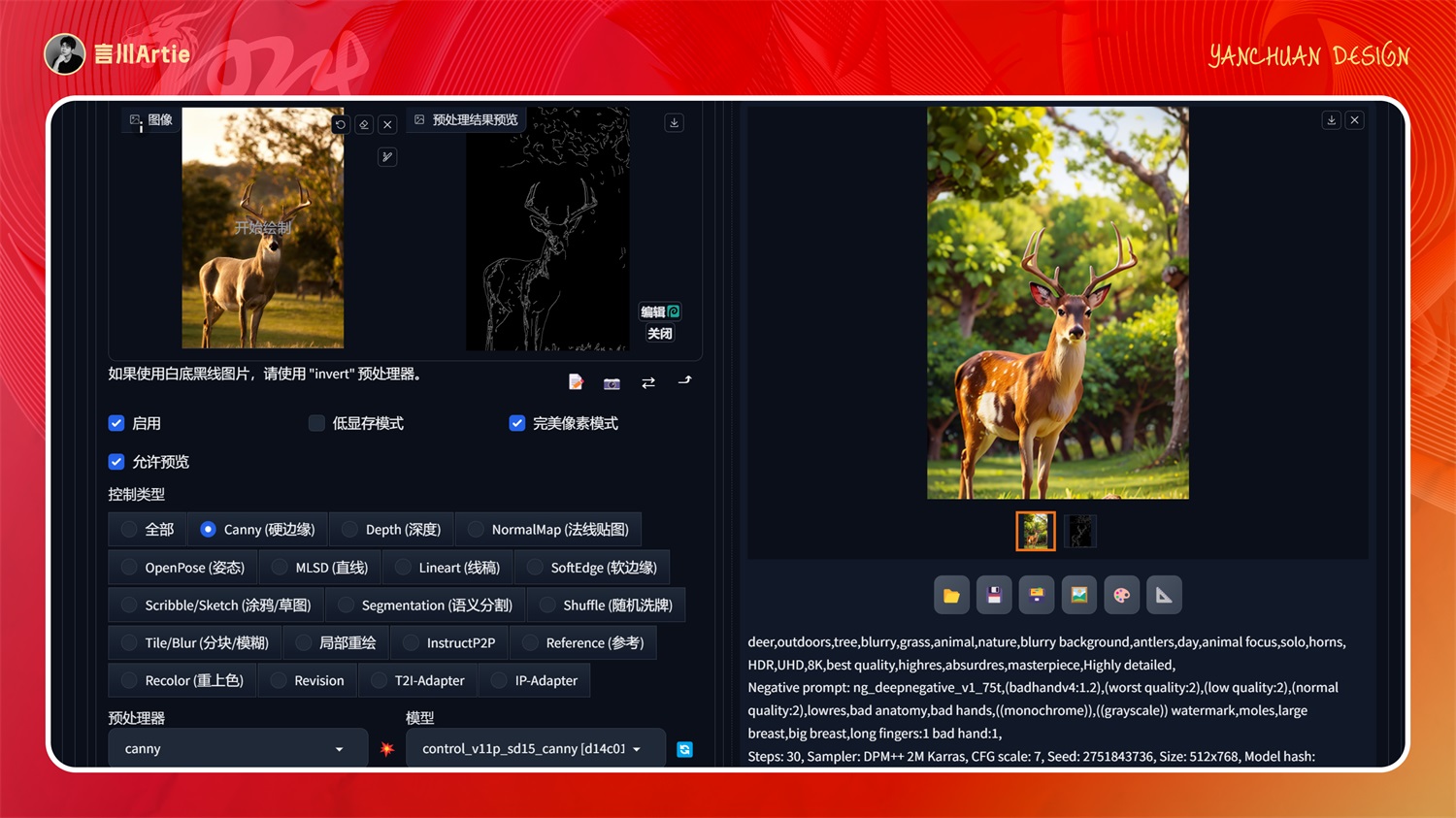
使用 canny 预处理器和模型,控制鹿的形体和身体细节之处,然后通过大模型和关键词的配合,即可生成与上传图非常非常相似的鹿。还可以控制背景元素,这是我们在生图中最常用的模型之一。
④ControlNet 1.1 MLSD
使用M-LSD直线控制Stable Diffusion模型文件:control_v11p_sd15_mlsd.pth
介绍:提取图片中物体的直线条,弯曲线条不会被提取。适合做室内设计和建筑设计这种直线结构的图。

实操案例:
大模型:majicMIX realistic 麦橘写实_v7.safetensors
正向关键词:couch,scenery,lamp,table,book,indoors,wooden floor,carpet,chair,plant,bookshelf,rug,shelf,ceiling light,door,HDR,UHD,8K,best quality,highres,absurdres,masterpiece,Highly detailed,
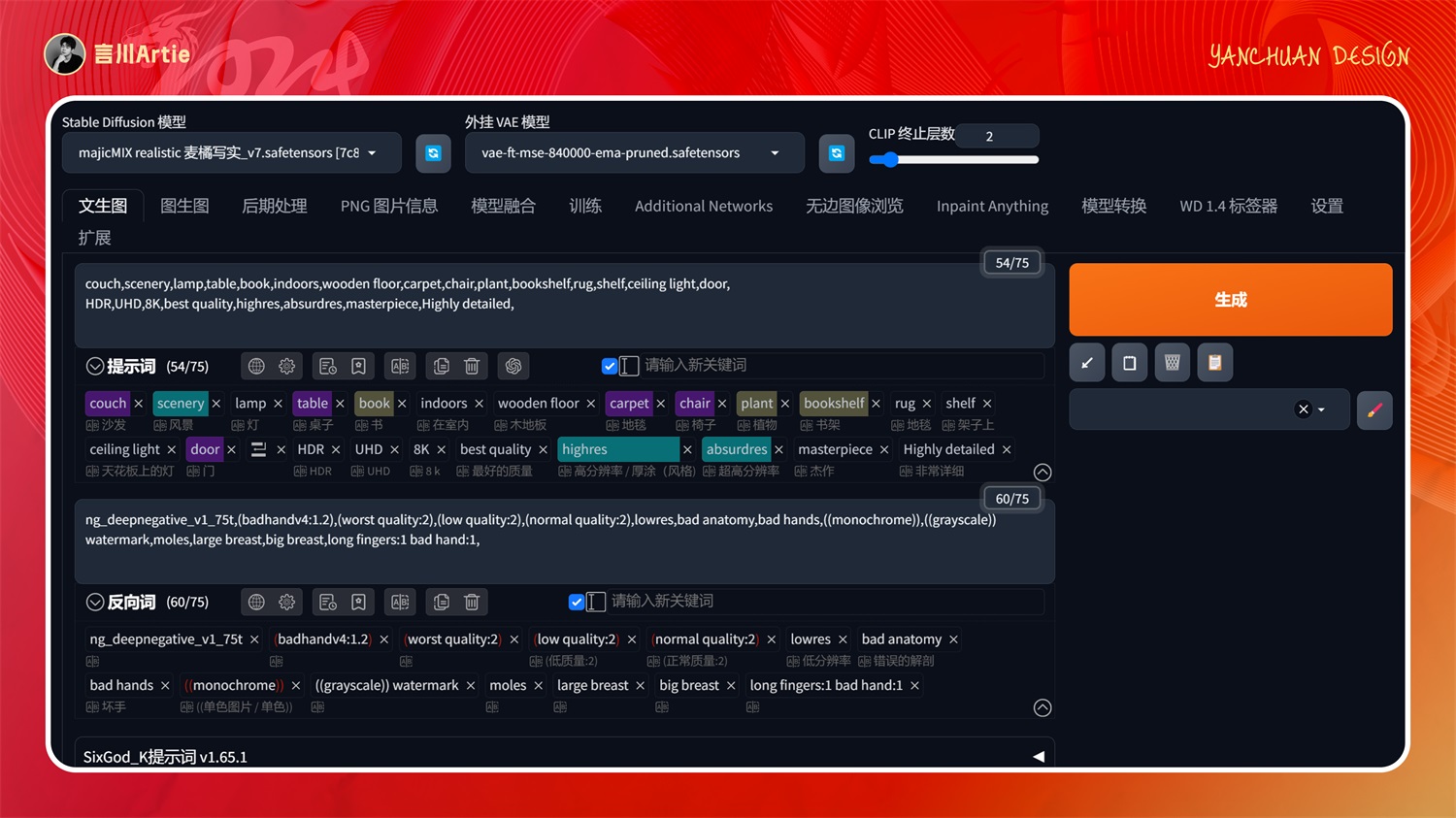
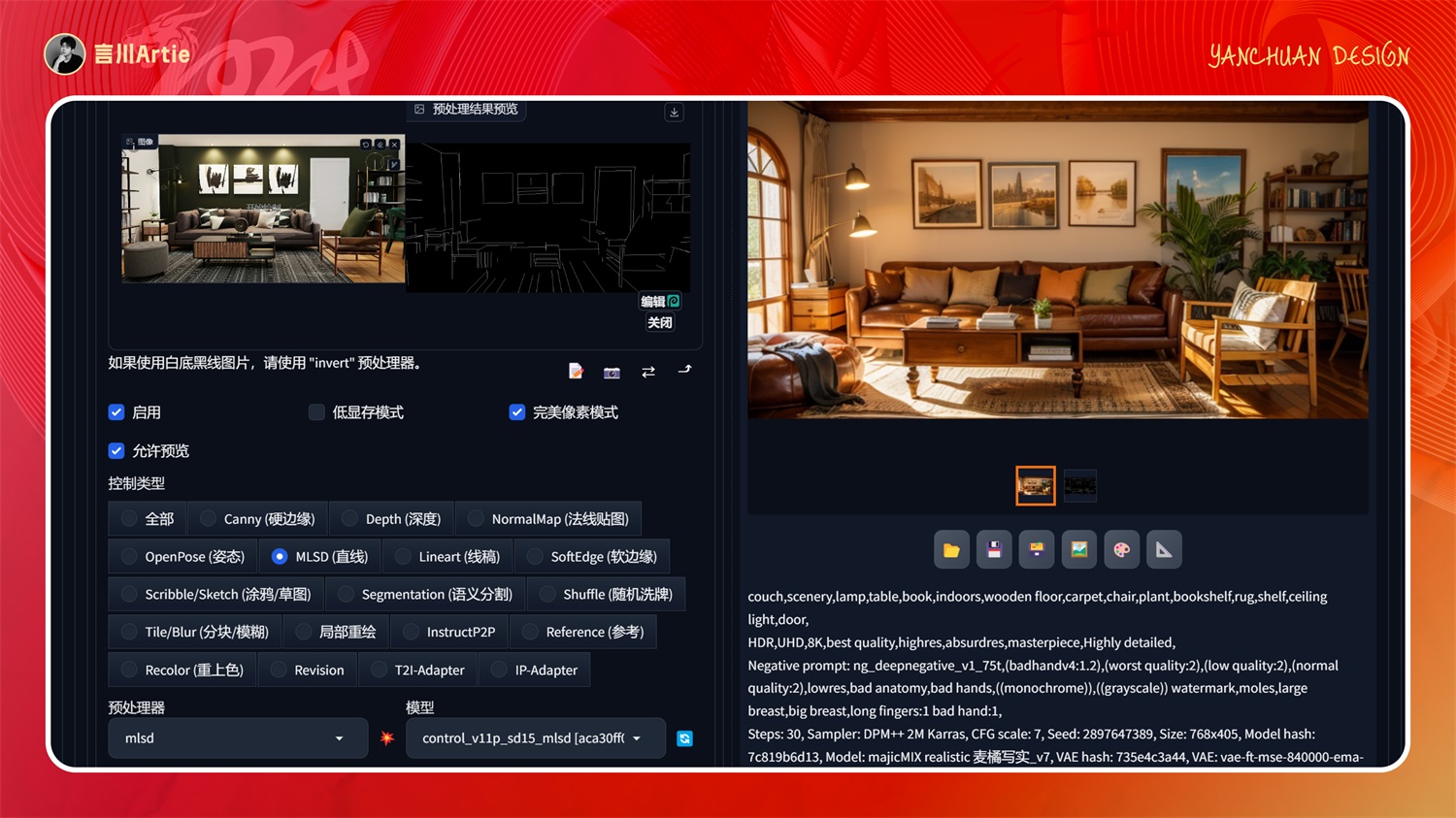
MLSD 模型在室内设计中最为常用,上传原始室内图,控制室内空间内的直线条,通过不同的关键词和大模型即可完成相同空间内不同风格的室内设计样板图。
⑤ControlNet 1.1 Scribble
使用涂鸦控制Stable Diffusion模型文件:control_v11p_sd15_scribble.pth
介绍:提取图片中物体的大轮廓,不会像 canny 一样提取精细化的线条,保留人物(物体)的外轮廓,细节会根据关键词发生改变。
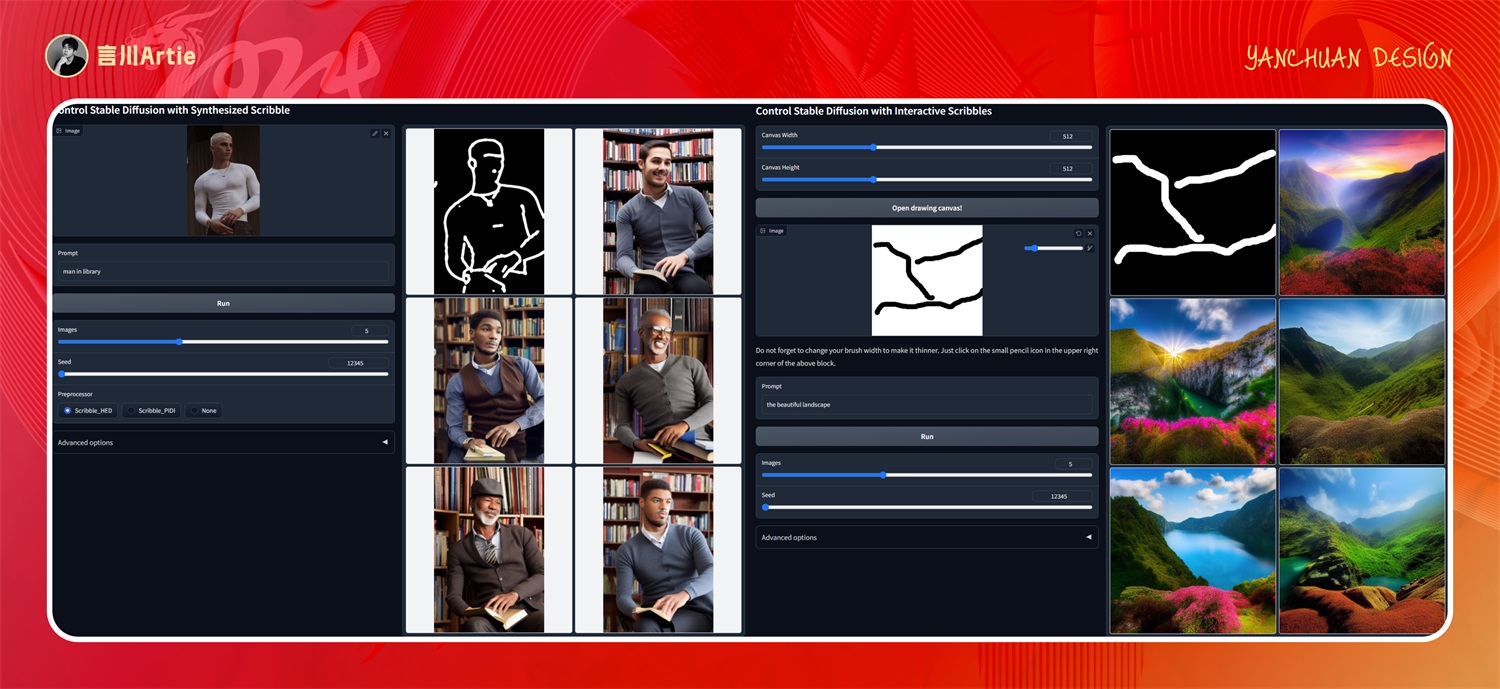
实操案例(与 canny 模型一样的案例):
大模型:disneyPixarCartoon_v10.safetensors
正向关键词:deer,outdoors,tree,blurry,grass,animal,nature,blurry background,antlers,day,animal focus,solo,horns,HDR,UHD,8K,best quality,highres,absurdres,masterpiece,Highly detailed,
相比于 canny 硬边缘控制,scribbble 相对比较柔和,在细节之处更多的是由 AI 来发挥生成,所以它的控制力不如 canny,适合展现创造力的图片。看下面生成的鹿和背景,只是控制了鹿的大概形体,其他地方则由 AI 发挥生成。
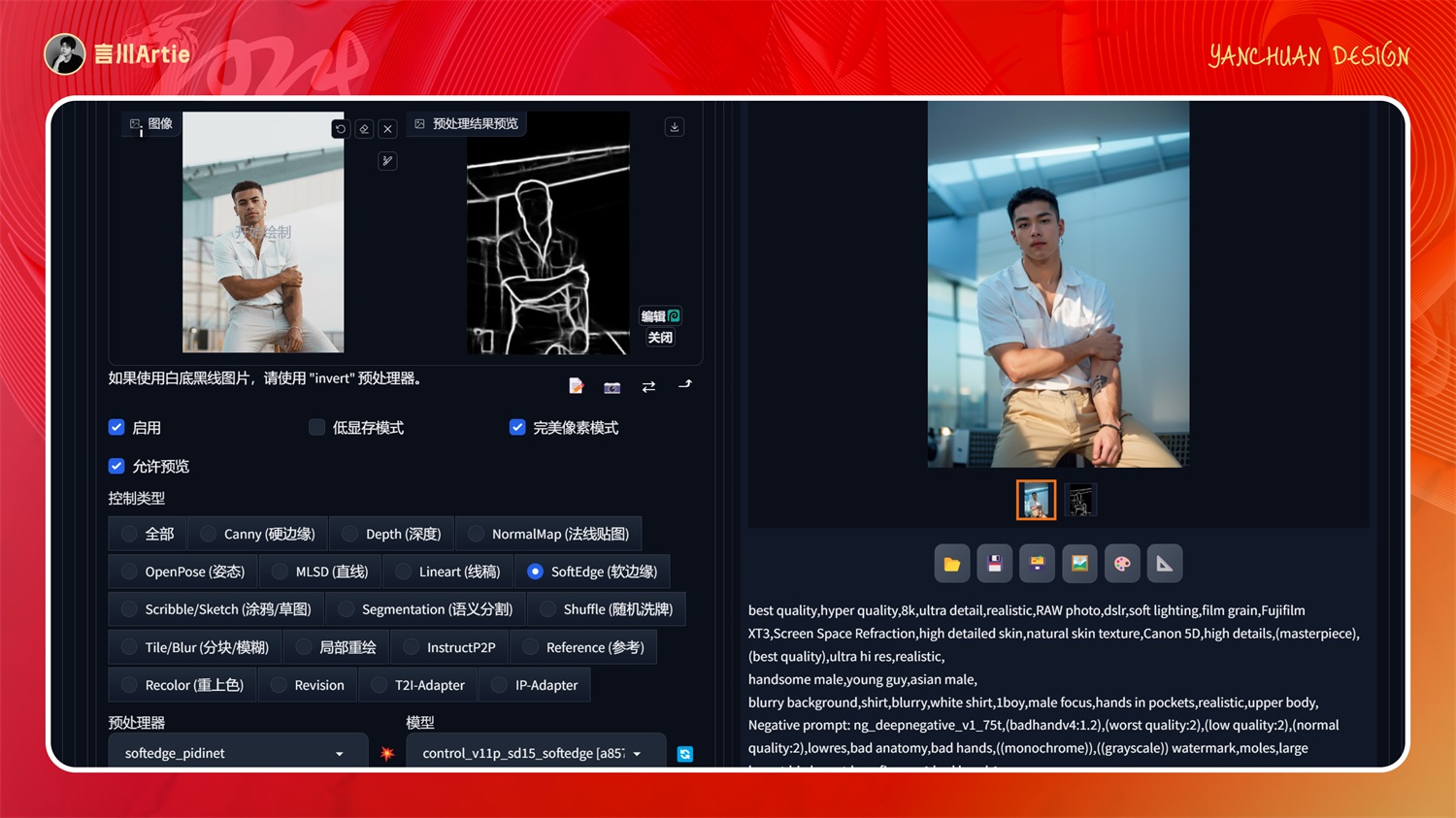
⑥ControlNet 1.1 Soft Edge
使用柔和边缘控制Stable Diffusion模型文件:control_v11p_sd15_softedge.pth
介绍:提取图片中物体的轮廓线,与 canny 不同的是他会首先提取物体大的轮廓线,然后其他地方会有细的线。相当于 canny 与 scribble 的结合,粗粗细细的。
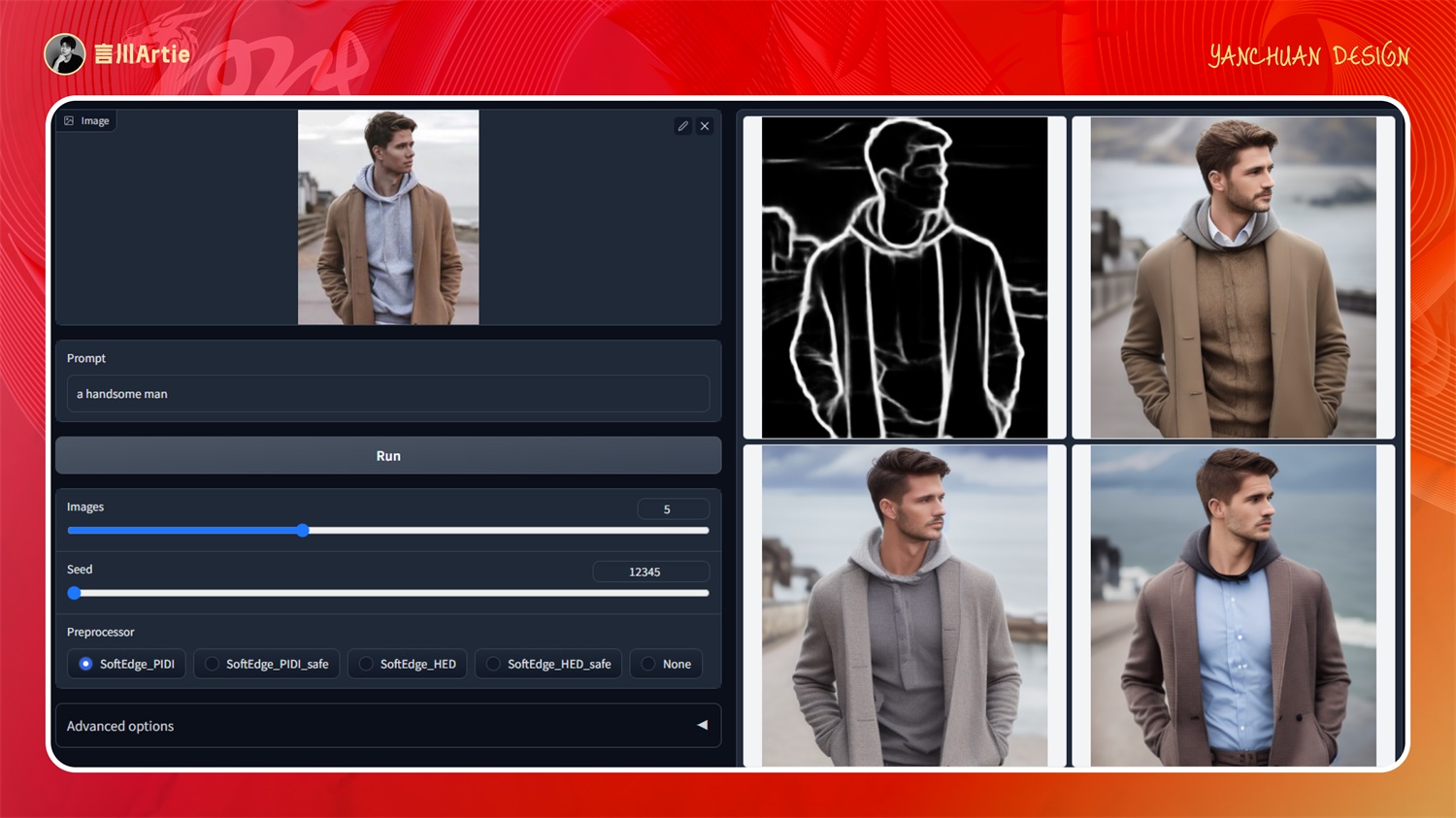
实操案例:
大模型:majicMIX alpha 麦橘男团_v2.0.safetensors
正向关键词:best quality,hyper quality,8k,ultra detail,realistic,RAW photo,dslr,soft lighting,film grain,Fujifilm XT3,Screen Space Refraction,high detailed skin,natural skin texture,Canon 5D,high details,(masterpiece),(best quality),ultra hi res,realistic,handsome male,young guy,asian male,blurry background,shirt,blurry,white shirt,1boy,male focus,hands in pockets,realistic,upper body,
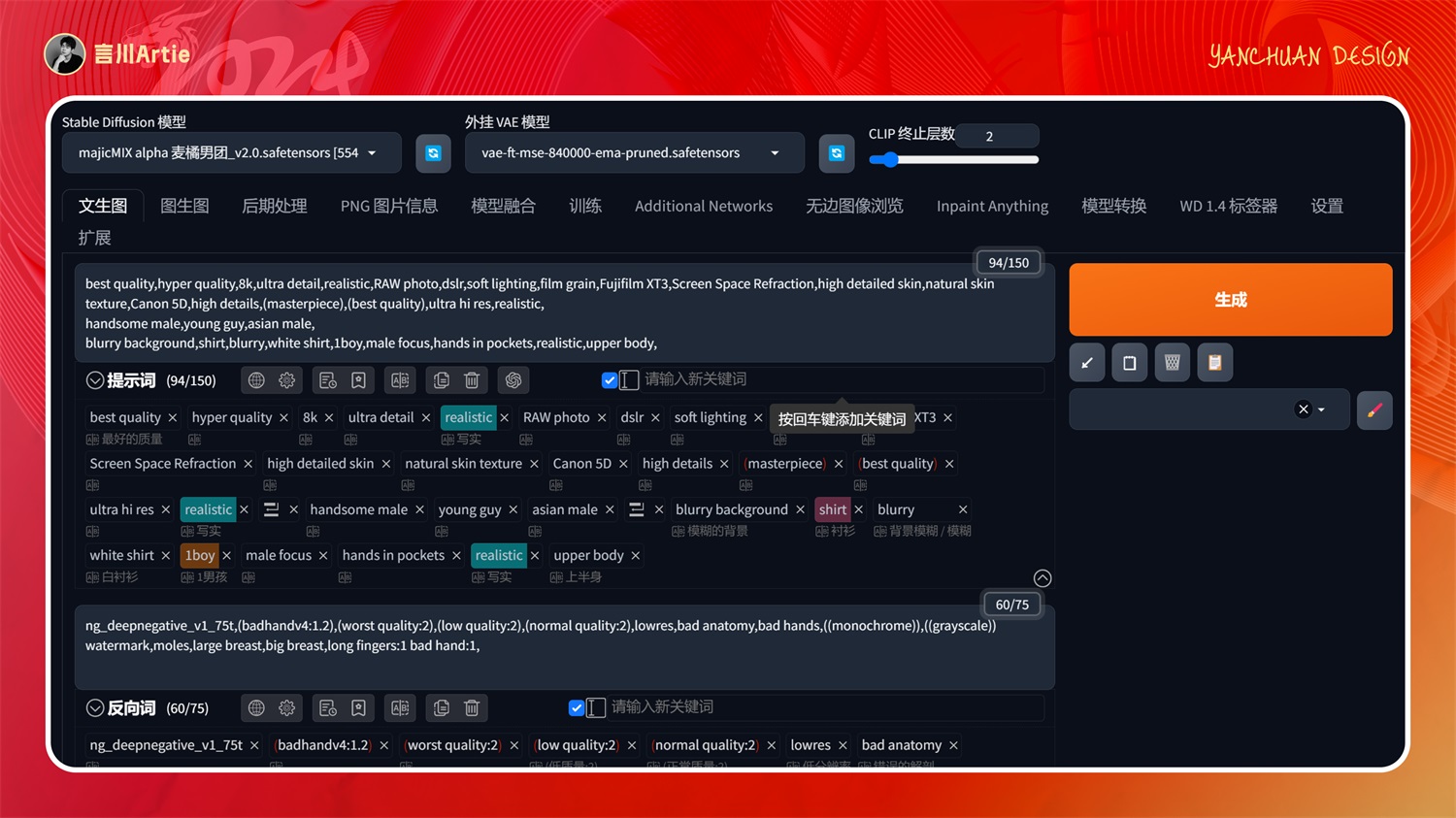
与上面说的一样,它相当于 Canny 与 Scribble 结合,能通过预处理精准控制图片中的物体,可以对比这几个模型的预处理出来的草稿图,他们对形体的控制力度会有区别,也是比较常用的模型。
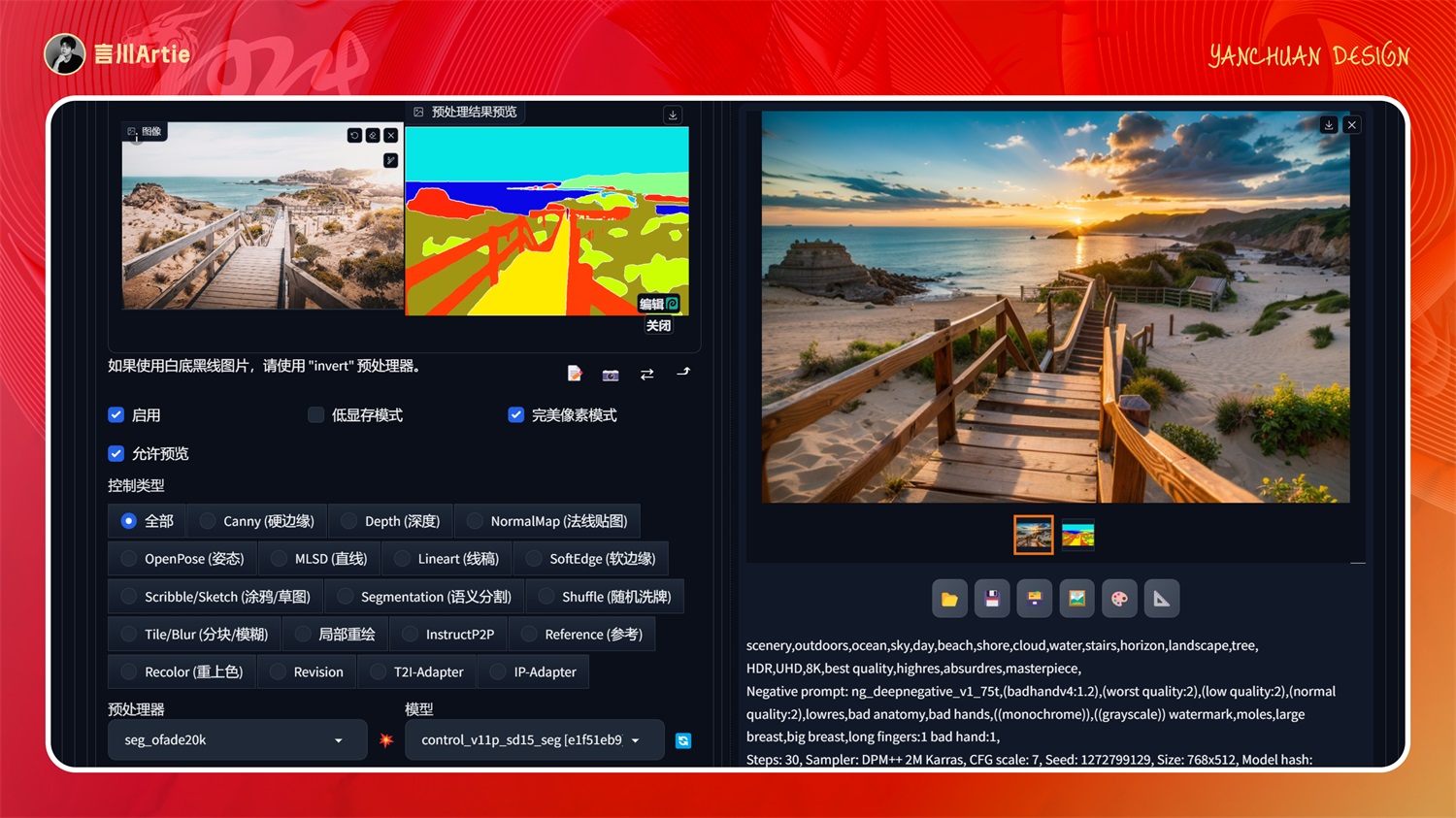
⑦ControlNet 1.1 Segmentation
使用语义分割控制Stable Diffusion模型文件:control_v11p_sd15_seg.pth
介绍:设计中的语义分割图,根据色块生成不同的物体,识别物体对应色块进行画面的区分,然后根据关键词的描述生成该物体在图片中的样子。
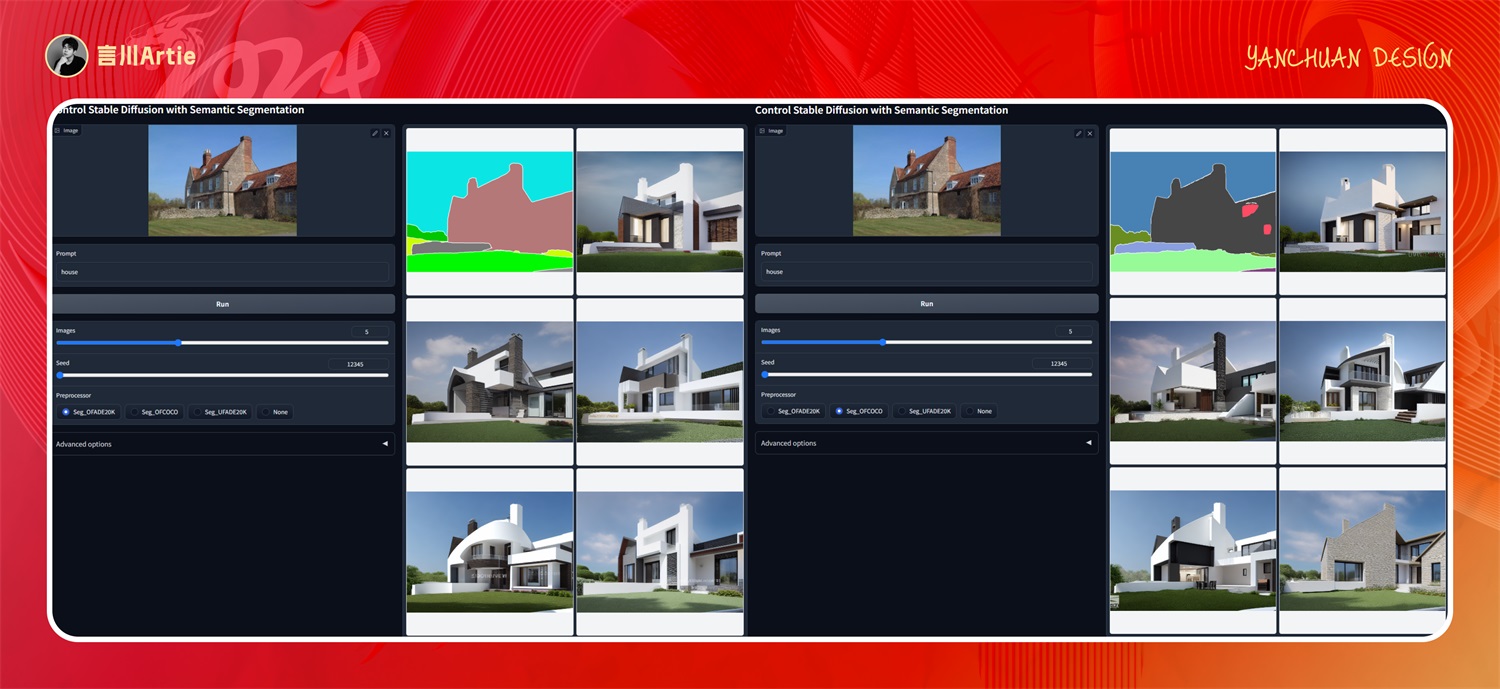
这个表格是用在“seg”这个模型上的,可以通过颜色来控制物体在画面出现的区域。
实操案例:
大模型:majicMIX realistic 麦橘写实_v7.safetensors
正向关键词:scenery,outdoors,ocean,sky,day,beach,shore,cloud,water,stairs,horizon,landscape,tree,HDR,UHD,8K,best quality,highres,absurdres,masterpiece,
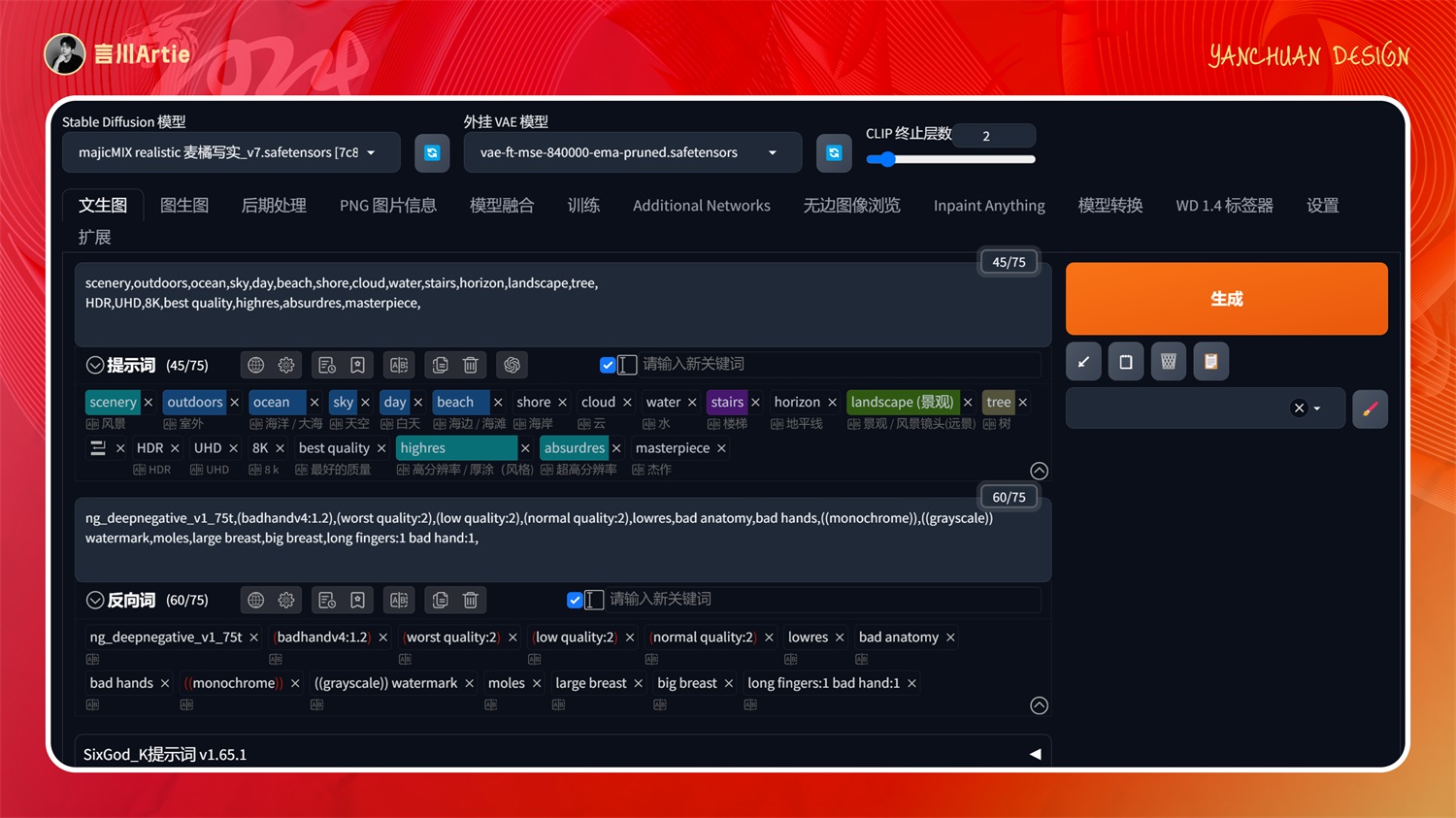
它的原理是把图像中的物体,按照语义分割图的规则分割成色块,每个色块都对应着一个物体,比如青蓝色是天空,草木是绿色,通过这样的方式控制图片中的元素,也是比较常用的模型。
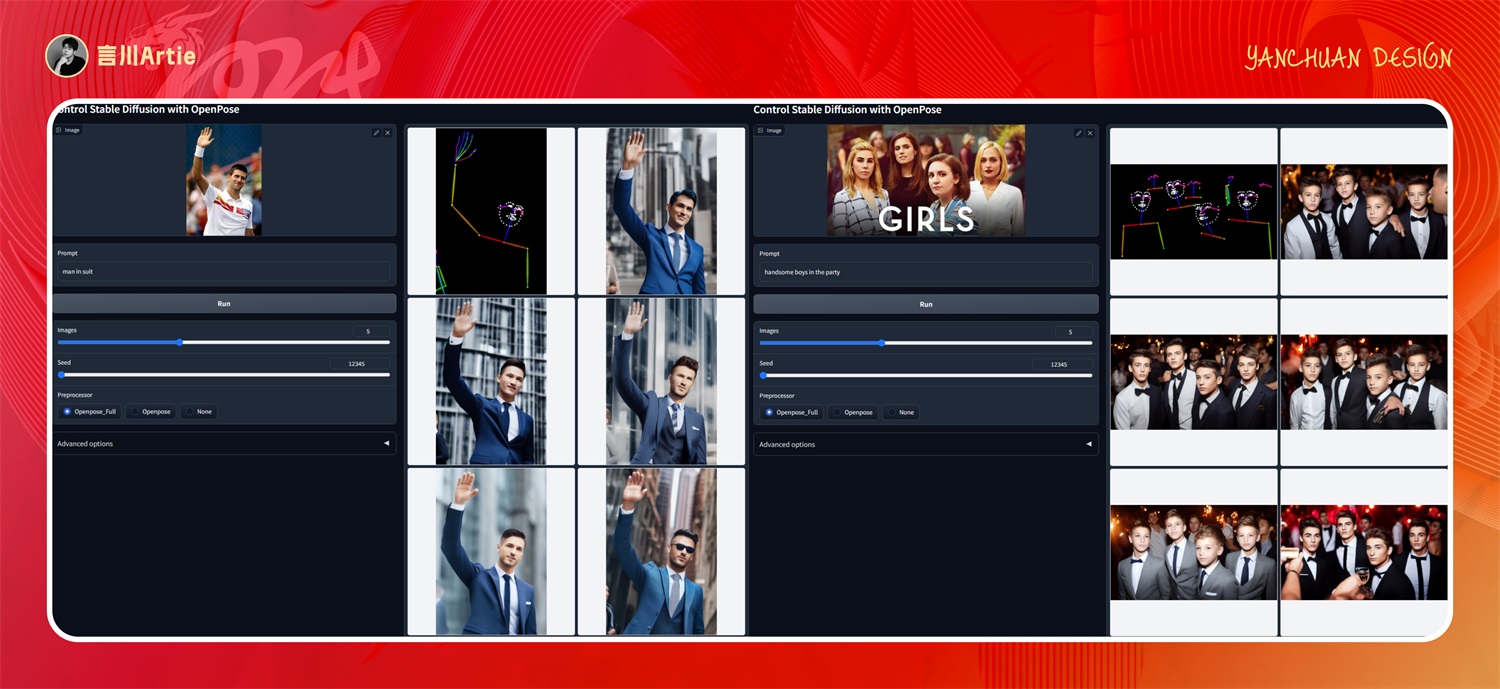
⑧ControlNet 1.1 Openpose
使用Openpose控制Stable Diffusion模型文件:control_v11p_sd15_openpose.pth
介绍:识别人物的姿势、面部、手臂,生成骨架图,AI 根据骨架图可以很好的还原原图上的人物形态。
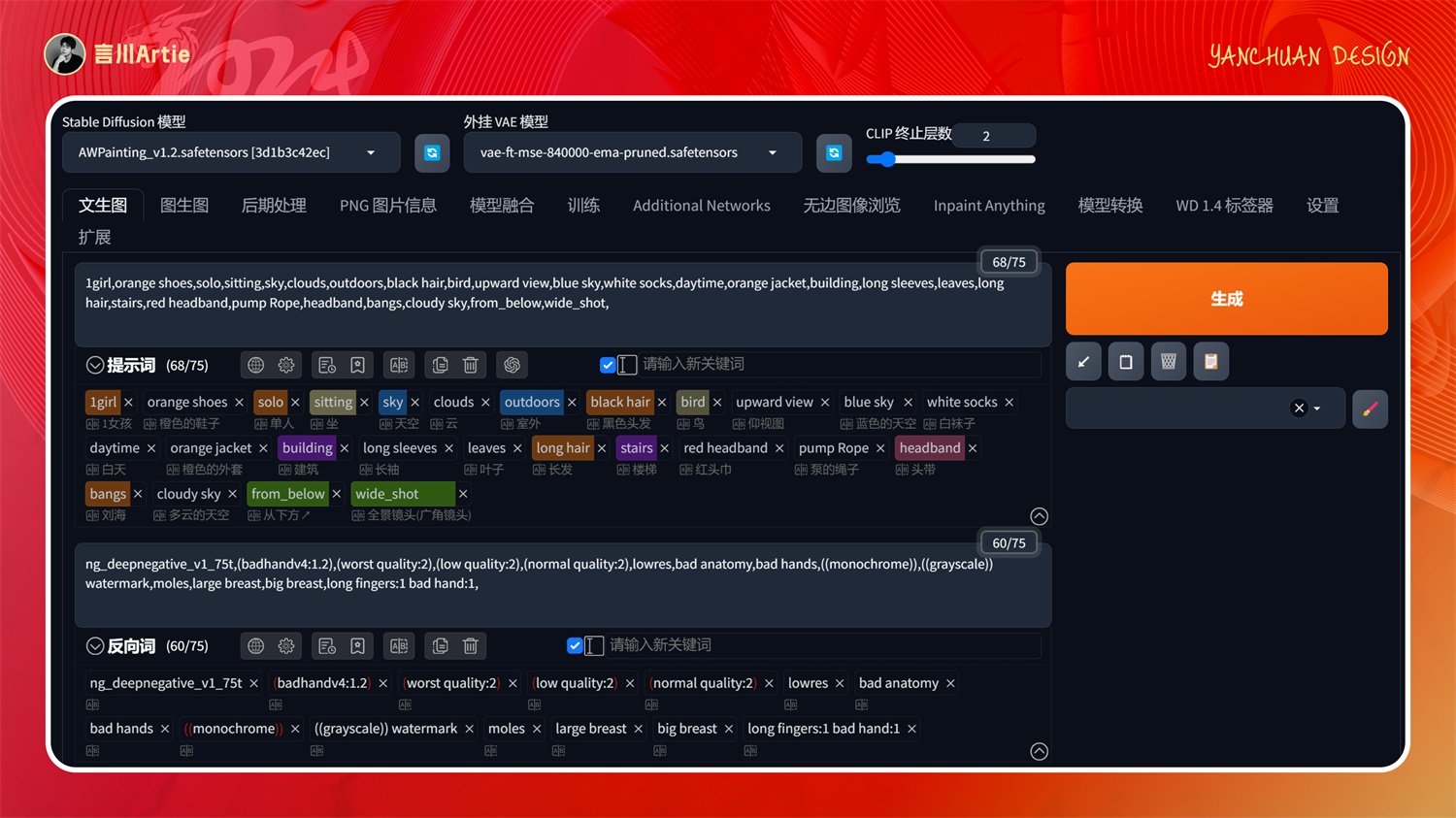
实操案例:
大模型:AWPainting_v1.2.safetensors
正向关键词:1girl,orange shoes,solo,sitting,sky,clouds,outdoors,black hair,bird,upward view,blue sky,white socks,daytime,orange jacket,building,long sleeves,leaves,long hair,stairs,red headband,pump Rope,headband,bangs,cloudy sky,from_below,wide_shot,
上传人物图,可以通过 openpose 控制生成人物骨架图,通过不同的大模型和关键词,生成与原图人物姿势一样,但是风格不一样的图片,做人物类的图片少不了用它。
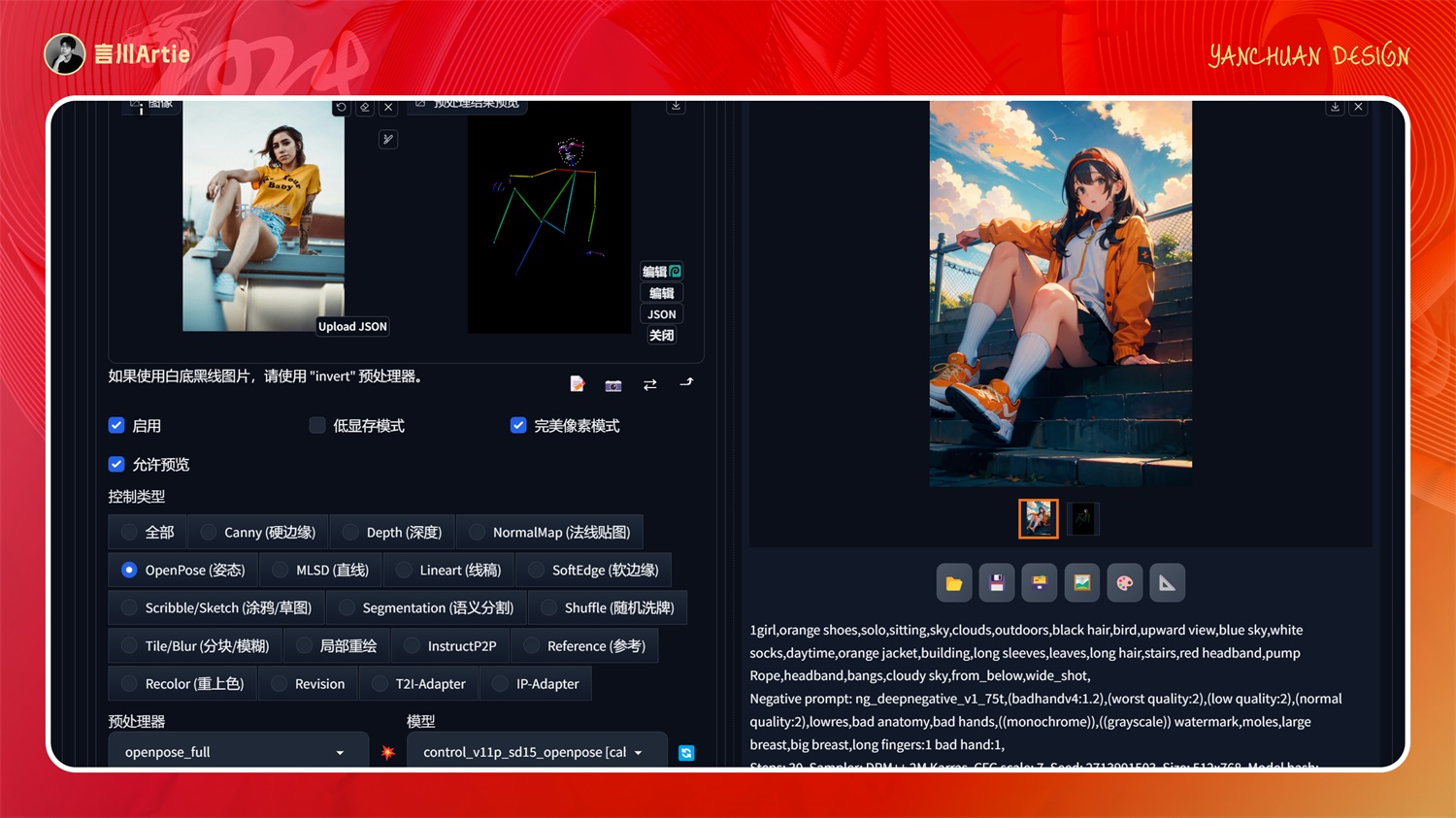
⑨ControlNet 1.1 Lineart
使用线条艺术控制Stable Diffusion模型文件:control_v11p_sd15_lineart.pth
介绍:精准的控制物体的线条,并自动对线条进行艺术化处理,与 canny 类似,适合做一些偏艺术类的图片,简单说可以帮我们把图片转成手绘线稿图。
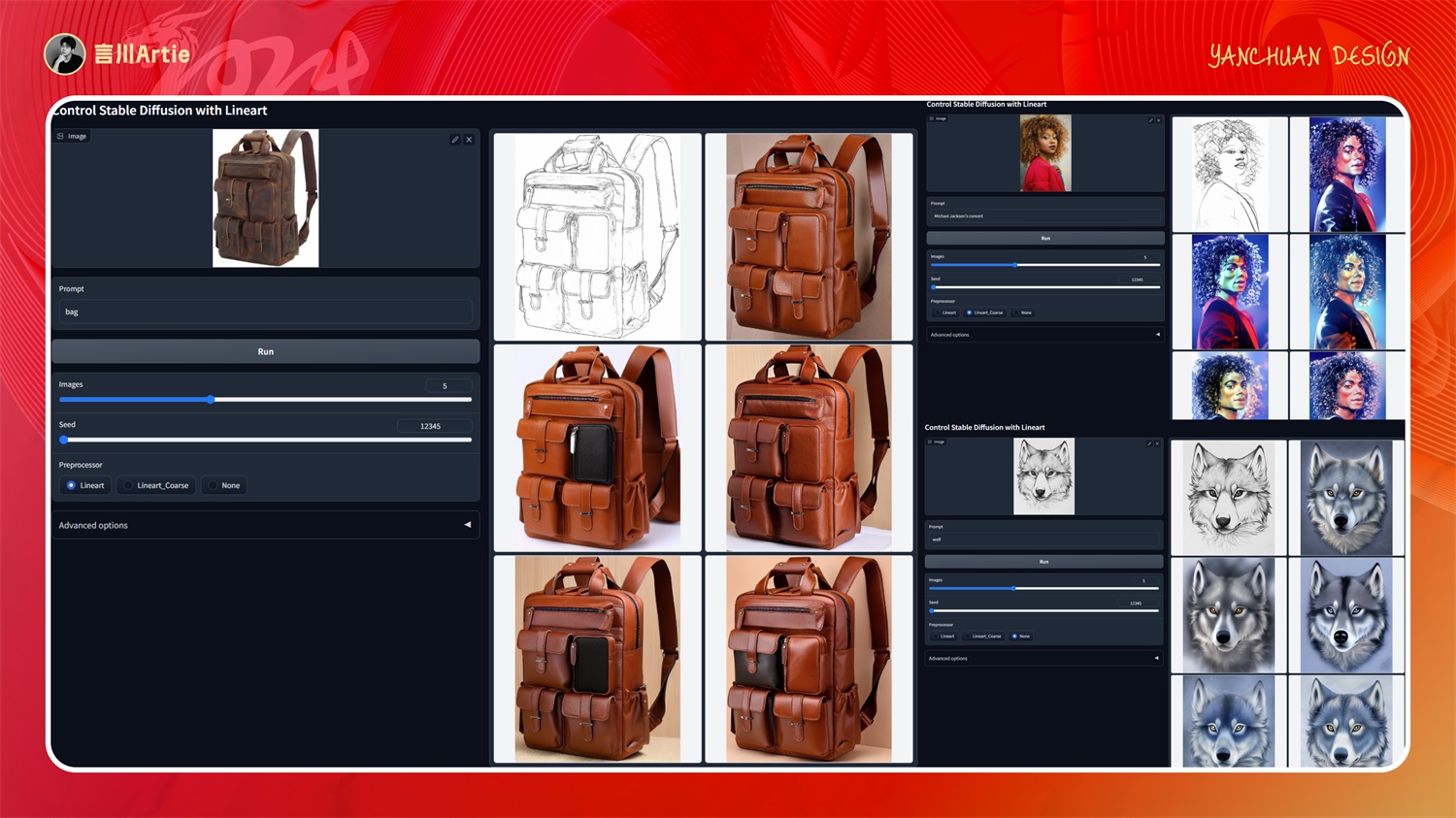
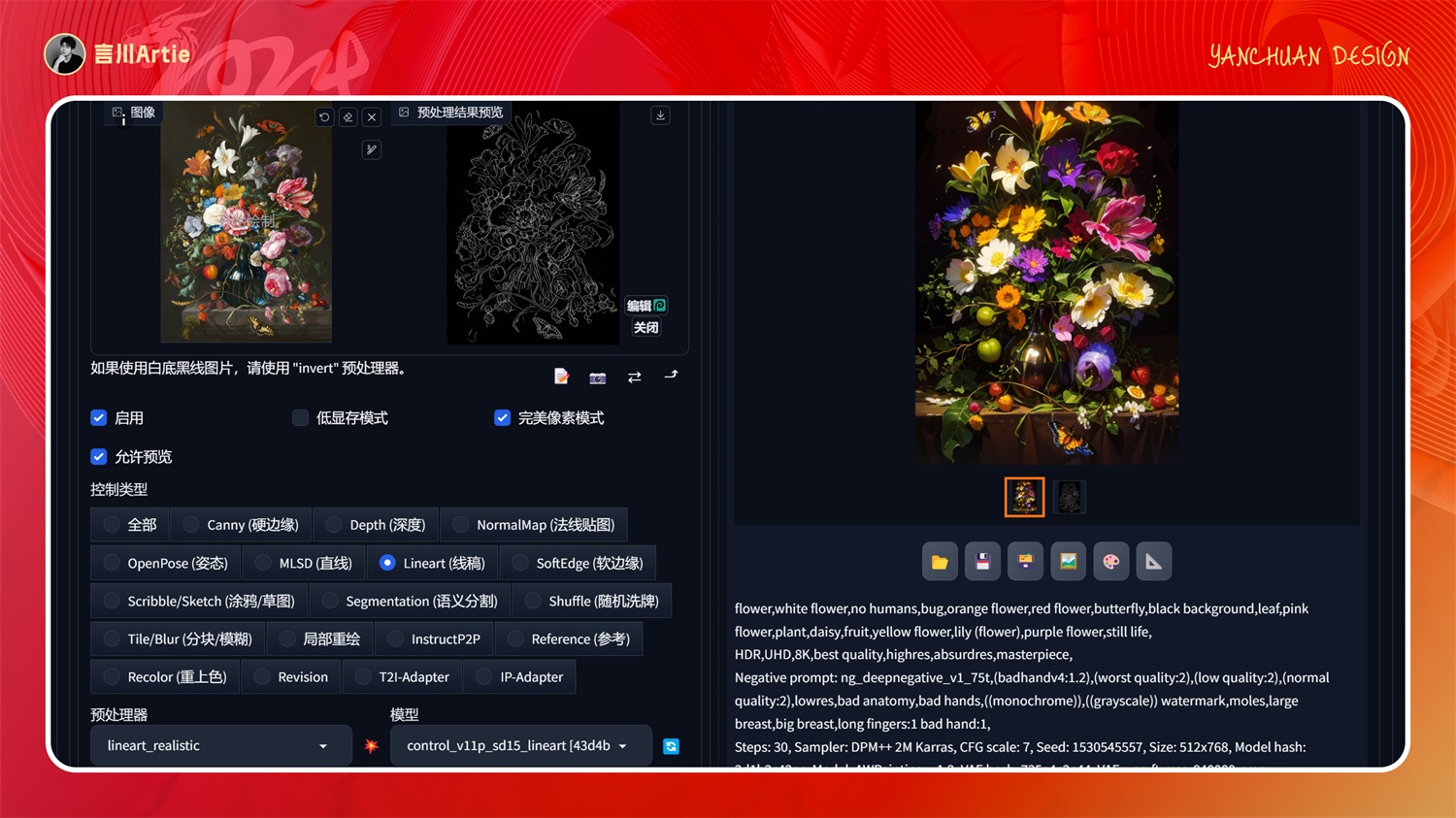
实操案例:
大模型:AWPainting_v1.2.safetensors
正向关键词:flower,white flower,no humans,bug,orange flower,red flower,butterfly,black background,leaf,pink flower,plant,daisy,fruit,yellow flower,lily (flower),purple flower,still life,HDR,UHD,8K,best quality,highres,absurdres,masterpiece,
这个模型提取出来的线条就类似我们手绘出来的线稿图一样,对于艺术类的图片控制重绘的效果比较合适,可以看到下图生成出来的效果是非常精准的。
⑩ControlNet 1.1 Anime Lineart
使用动漫线条艺术控制Stable Diffusion模型文件:control_v11p_sd15s2_lineart_anime.pth
介绍:专门做动漫线稿上色的模型,提取图片线稿,然后进行上色处理,也可以直接上传线稿上色。
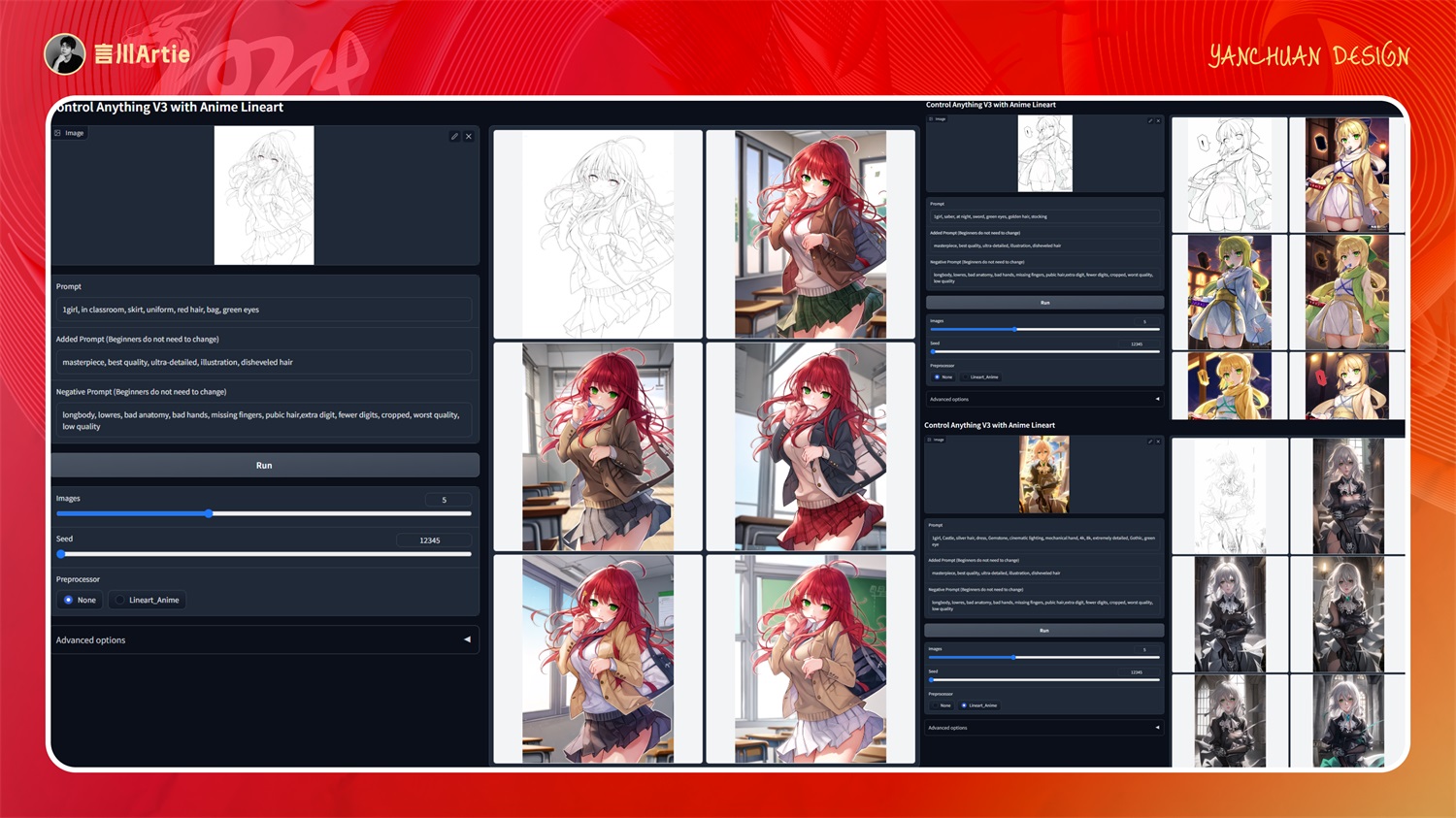
实操案例:
大模型:AWPainting_v1.2.safetensors
正向关键词:(masterpiece),(best quality:1.2),official art,(extremely detailed CG unity 8k wallpaper),(photorealistic:1.4),1girl,future technology,science fiction,future mecha,white mecha,streamlined construction,internal integrated circuit,upper body,driver's helmet,
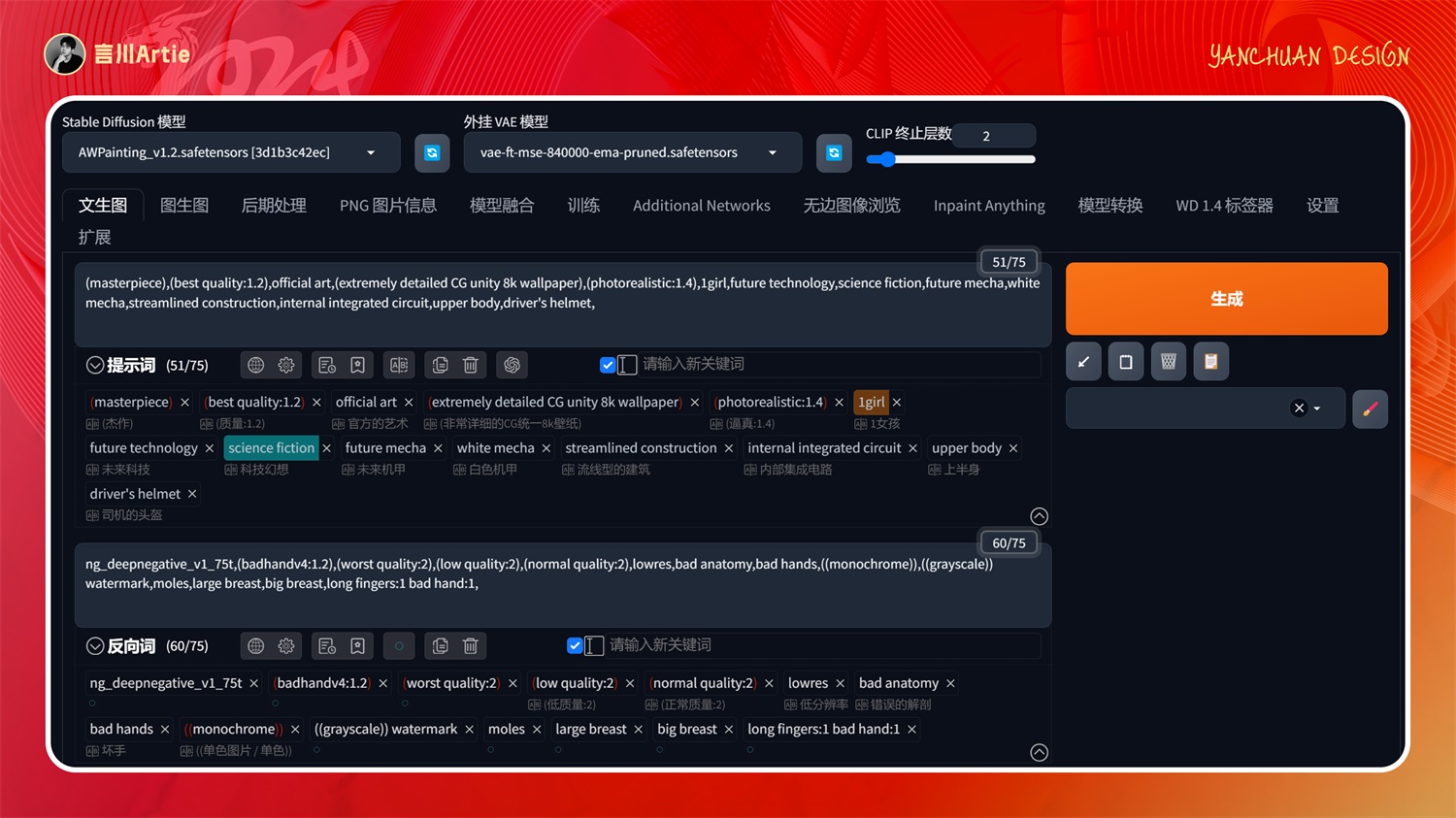
把人物线稿上传后,使用 lineart 进行黑白反色处理,根据大模型风格和关键词描述,即可对手绘线稿上色,这也是最常用的线稿上色方式。
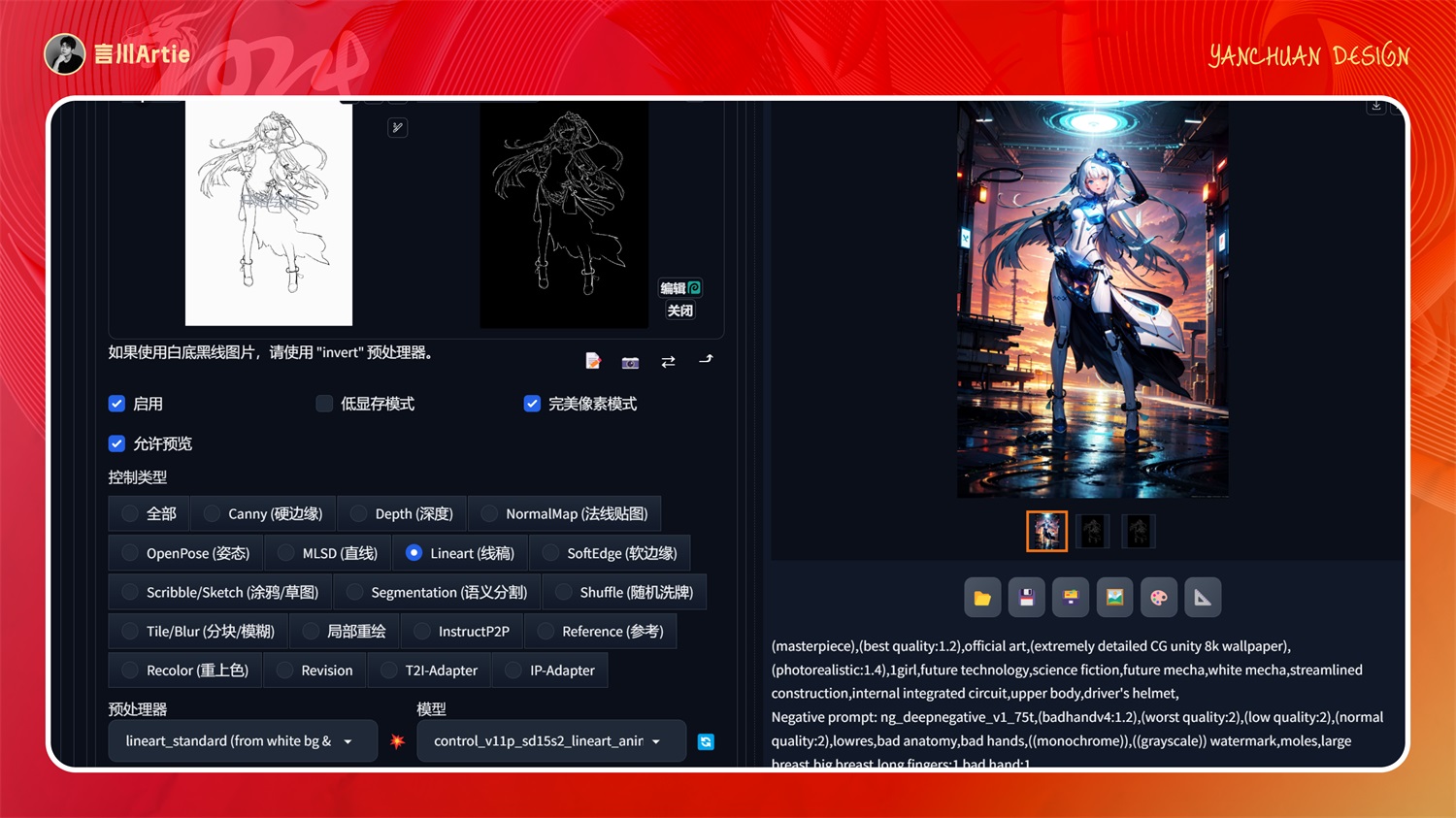
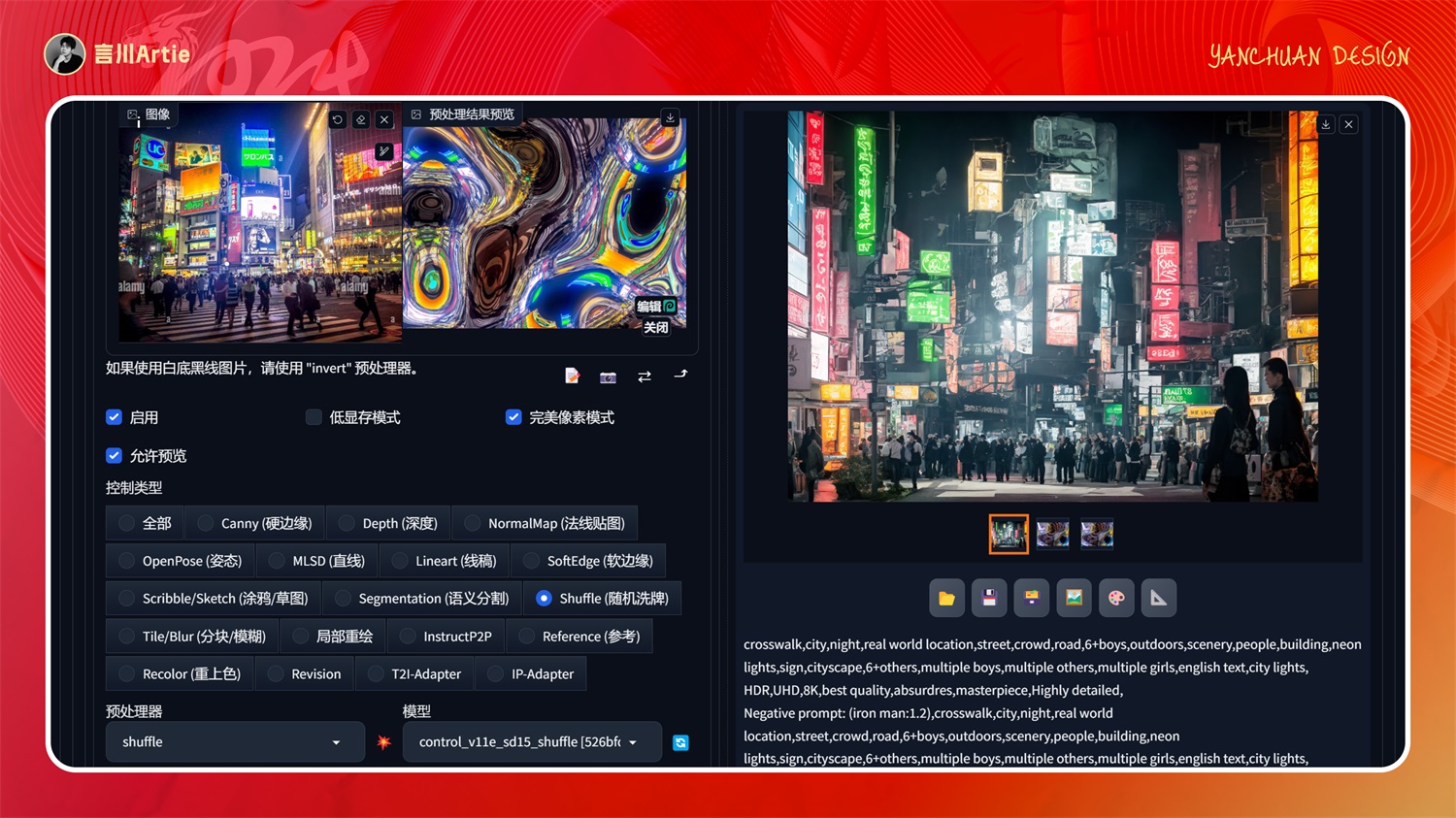
⑪ControlNet 1.1 Shuffle
使用内容洗牌控制Stable Diffusion模型文件:control_v11e_sd15_shuffle.pth
介绍:风格迁移,把原图的颜色信息打乱,然后为生成图片添加原图的颜色信息。简单来说就是让 AI 学习原图的风格,然后赋予到新的图片上。
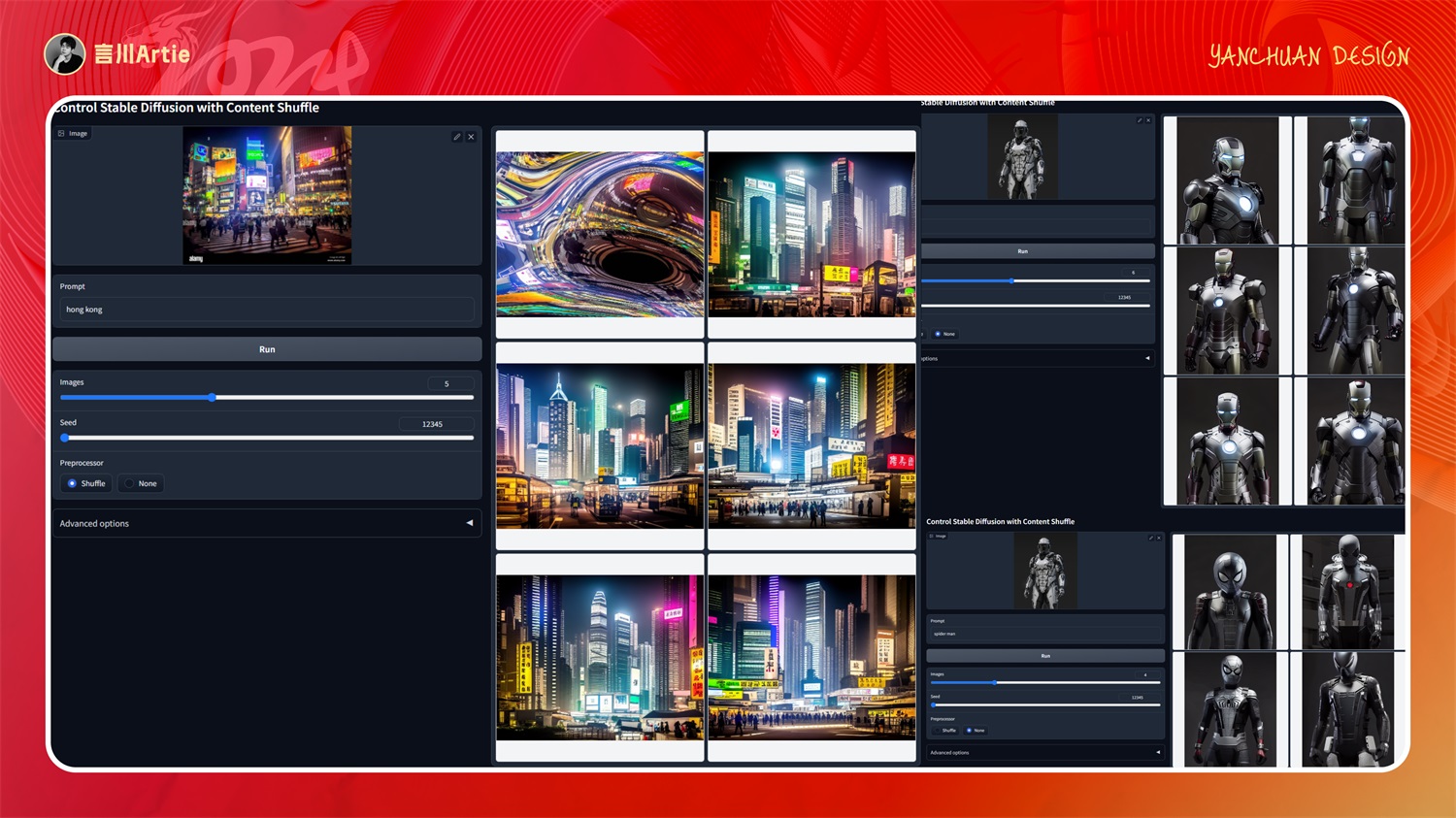
实操案例:
大模型:majicMIX realistic 麦橘写实_v7.safetensors
正向关键词:crosswalk,city,night,real world location,street,crowd,road,6+boys,outdoors,scenery,people,building,neon lights,sign,cityscape,6+others,multiple boys,multiple others,multiple girls,english text,city lights,HDR,UHD,8K,best quality,absurdres,masterpiece,Highly detailed,
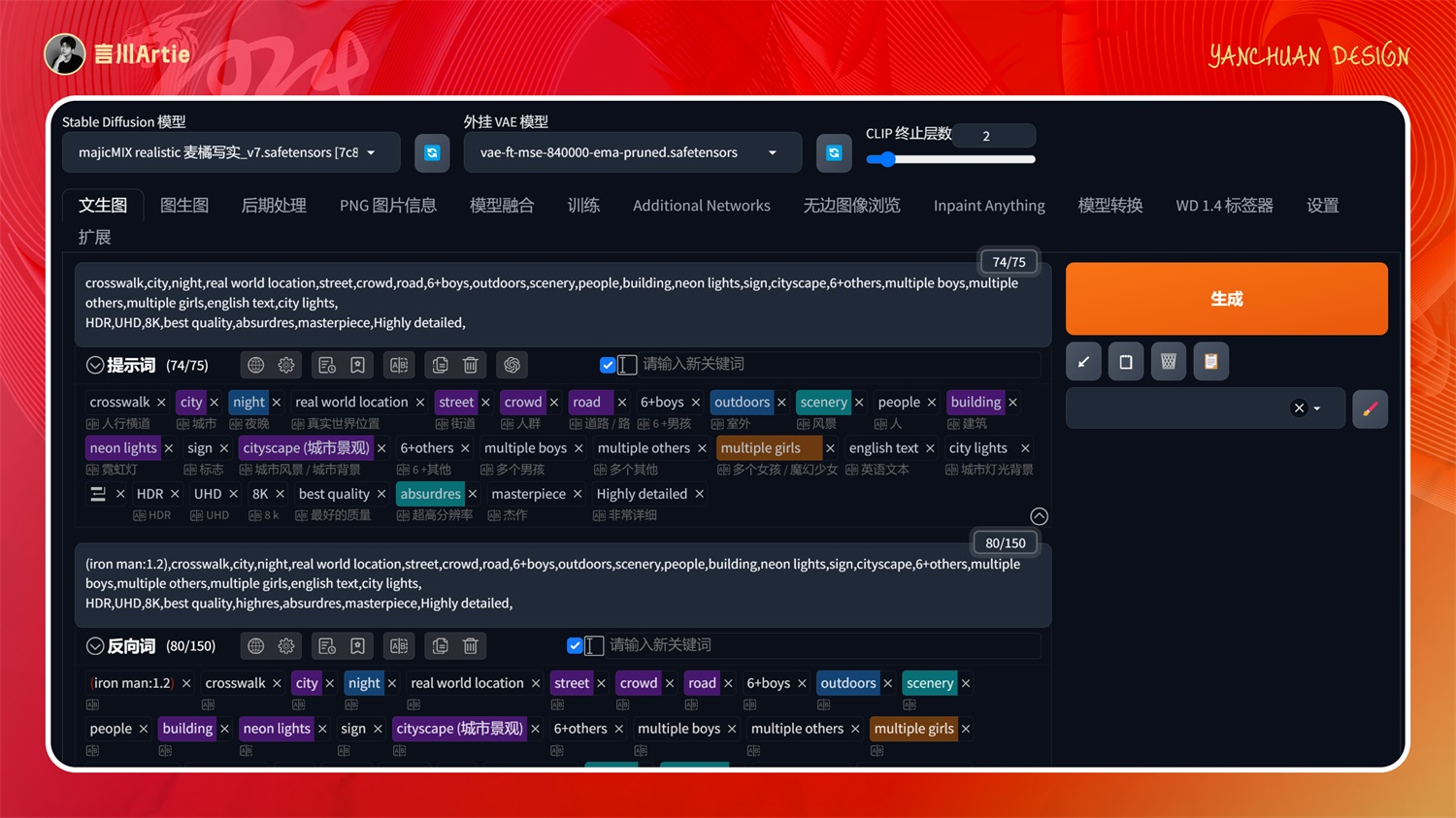
实测下来,不是特别理想。可能在一些小众场景中可以用到。
⑫ControlNet 1.1 Instruct Pix2Pix
使用指令式Pix2Pix控制Stable Diffusion模型文件:control_v11e_sd15_ip2p.pth
介绍:指令性模型,与其他的模型都不一样,它是上传一张图片后,给他发送一串指令关键词。比如下面的图片,给他发送:“让它着火”,但是目前只支持一些简单的指令,还不成熟。
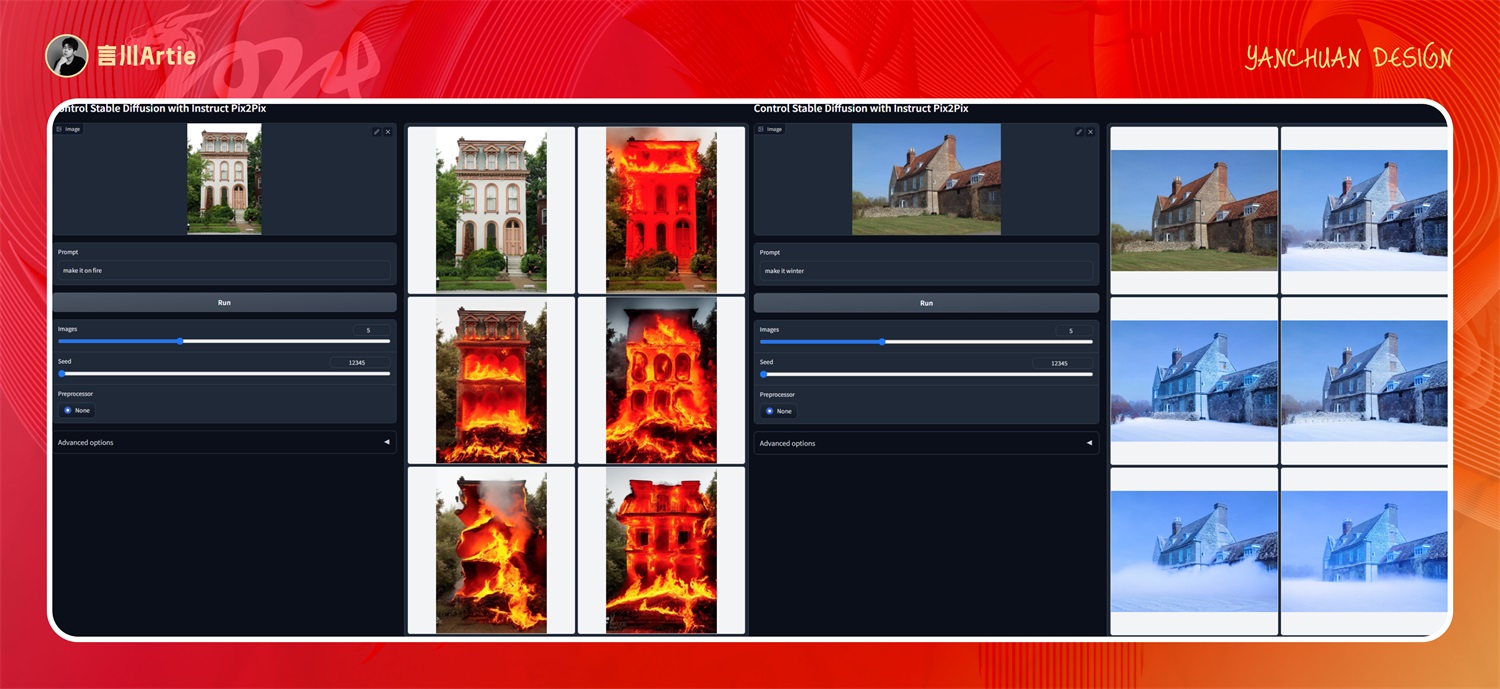
实操案例:
大模型:majicMIX realistic 麦橘写实_v7.safetensors
正向关键词:Set him on fire.
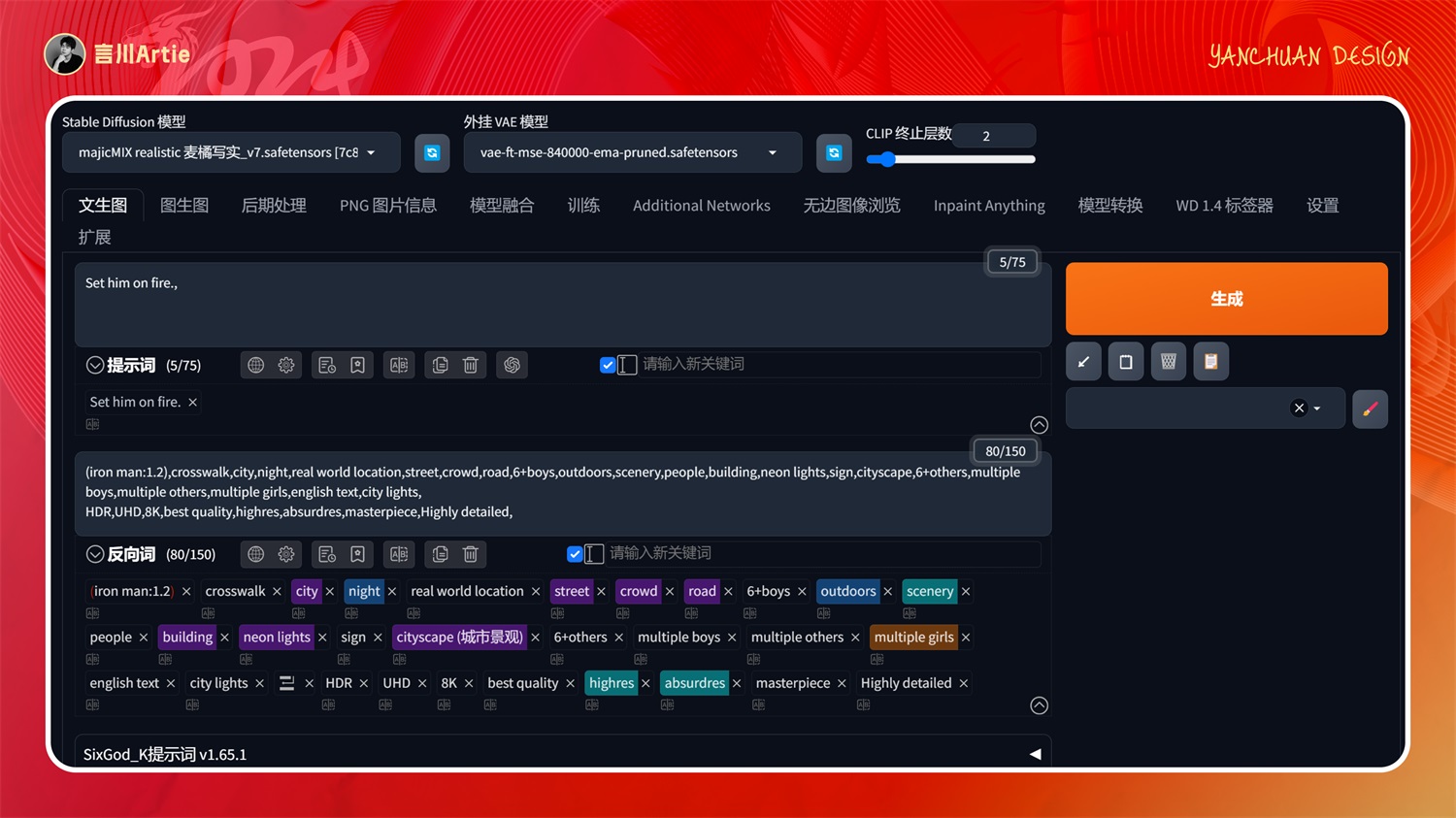
上传图片后,在正向关键词中描述:让它着火,就出现了如下的图片,尝试了更为复杂的指令,确实识别不出来,目前也就适合拿来玩一下。
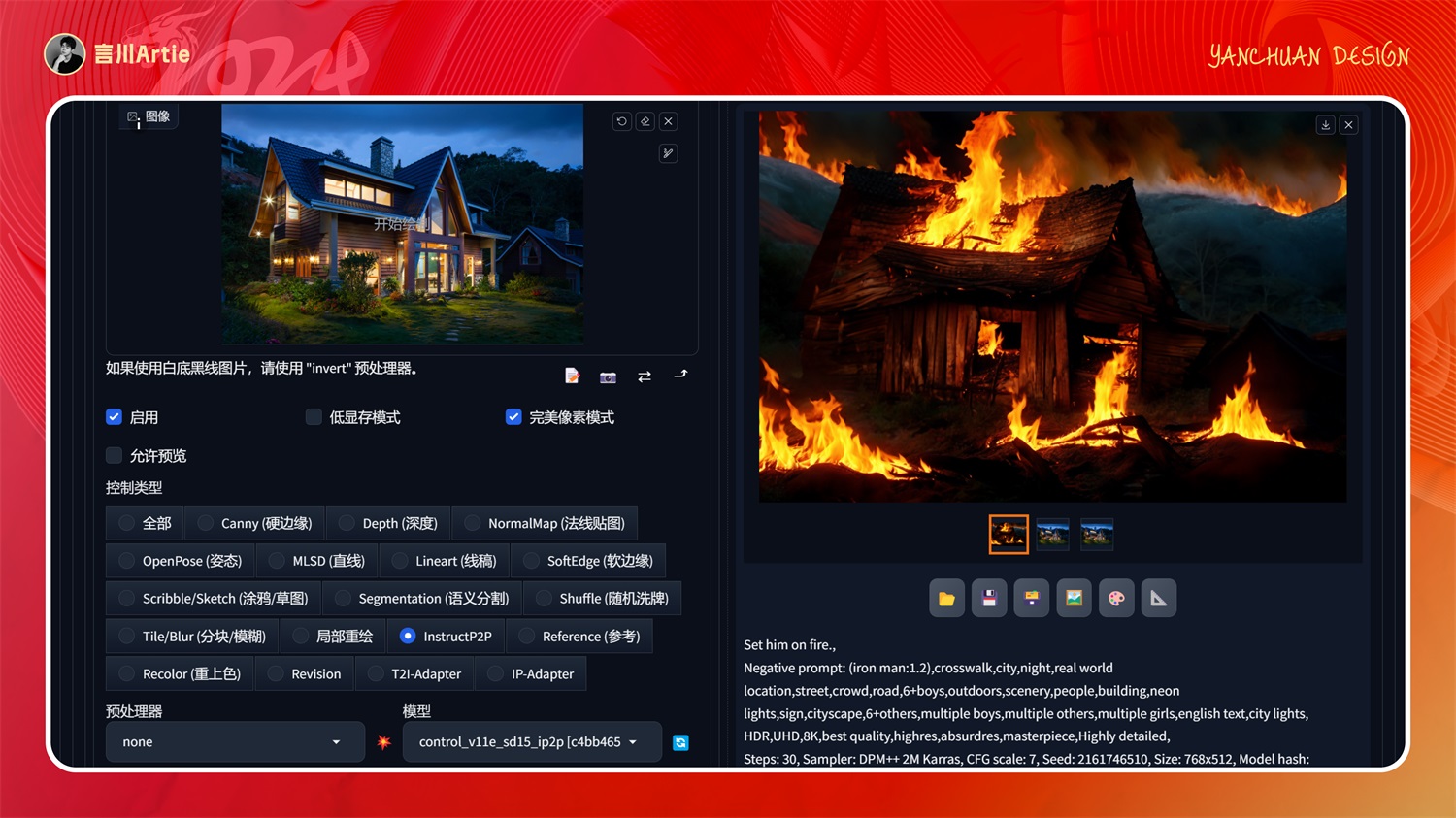
⑬ControlNet 1.1 Inpaint
使用修复控制Stable Diffusion模型文件:control_v11p_sd15_inpaint.pth
介绍:与图生图的局部重绘类似,它会比局部重绘生成的图与原图更融合,且操作更简单。
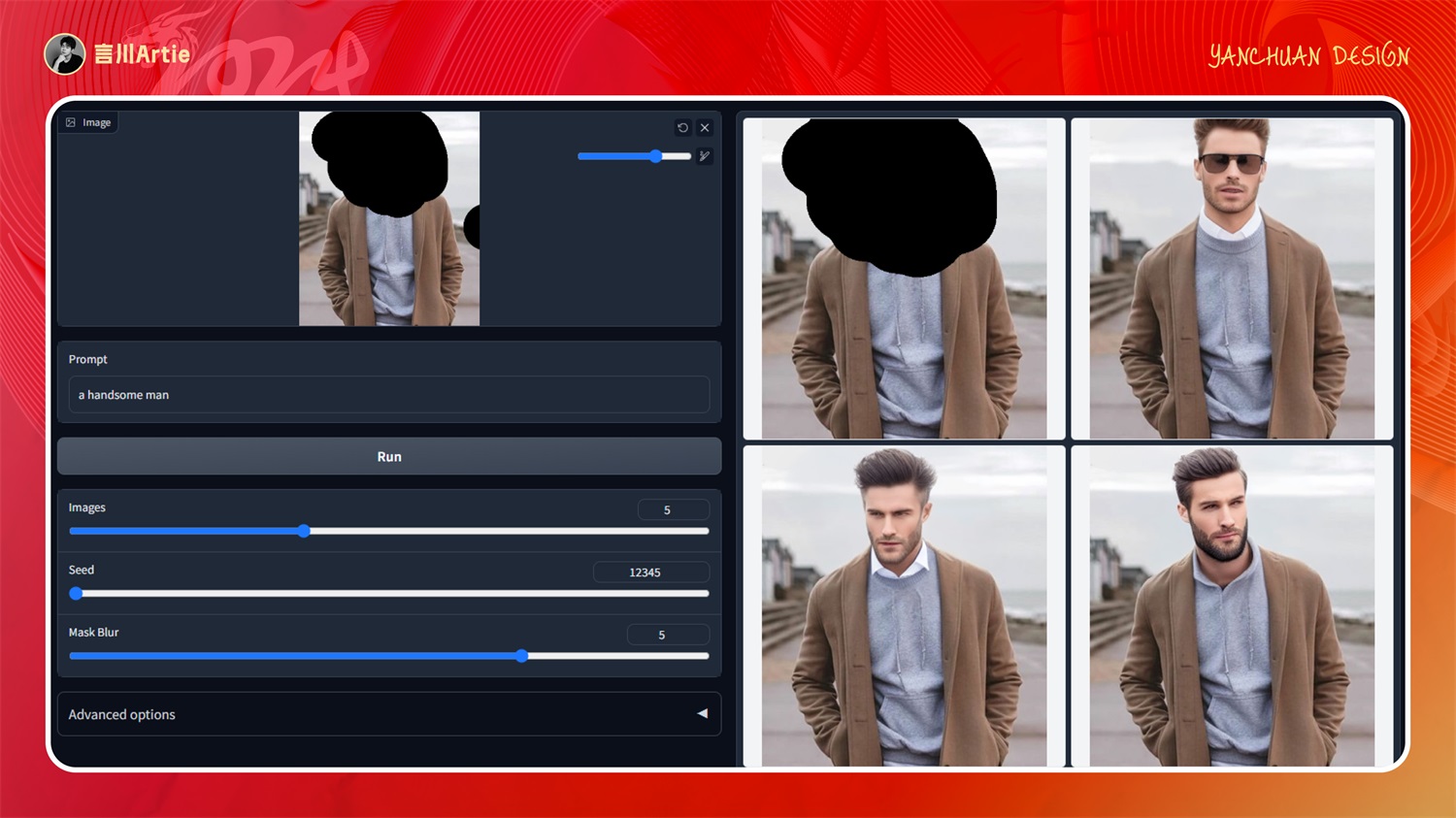
实操案例:
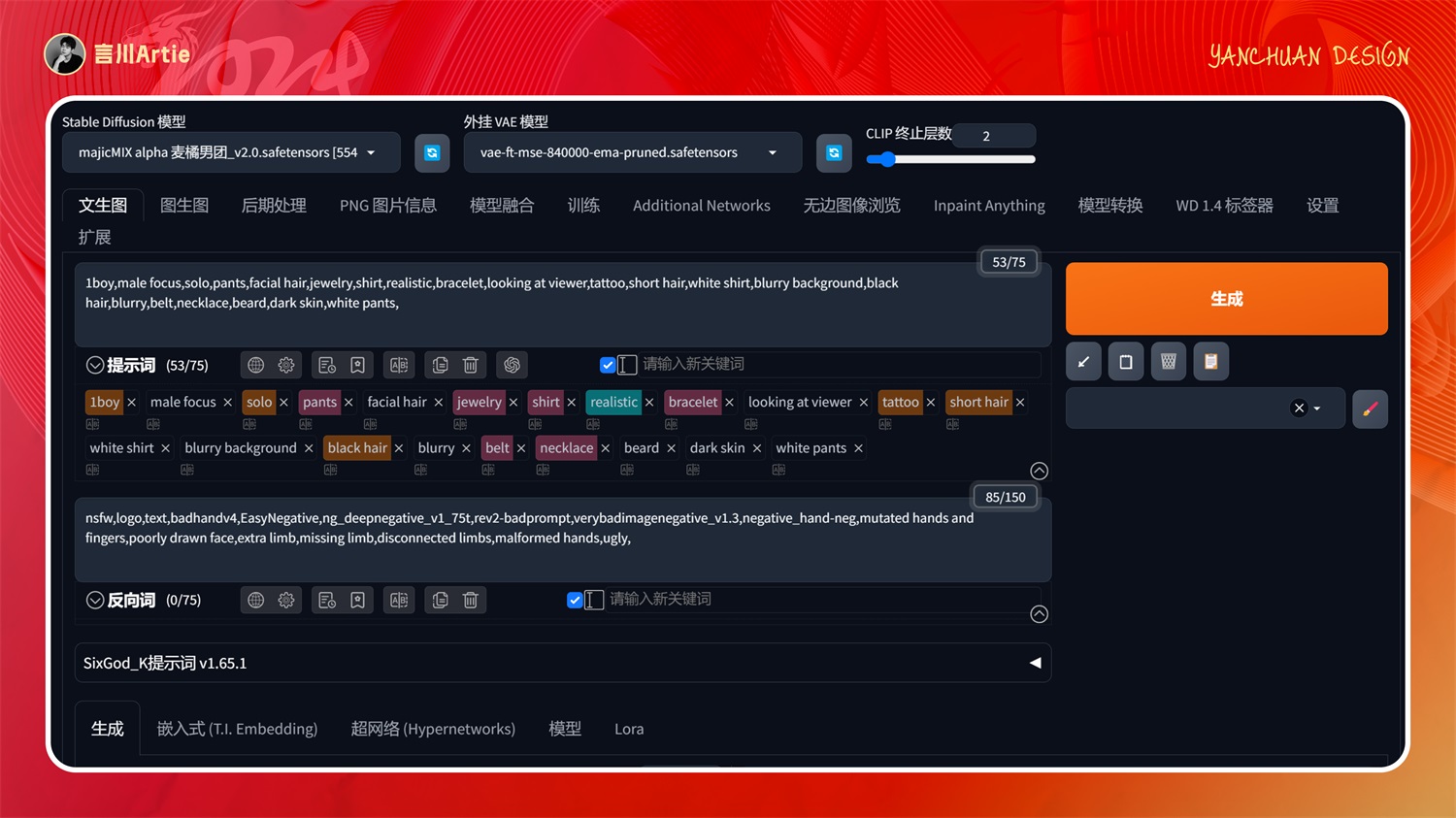
大模型:majicMIX alpha 麦橘男团_v2.0.safetensors
正向关键词:1boy,male focus,solo,pants,facial hair,jewelry,shirt,realistic,bracelet,looking at viewer,tattoo,short hair,white shirt,blurry background,black hair,blurry,belt,necklace,beard,dark skin,white pants,
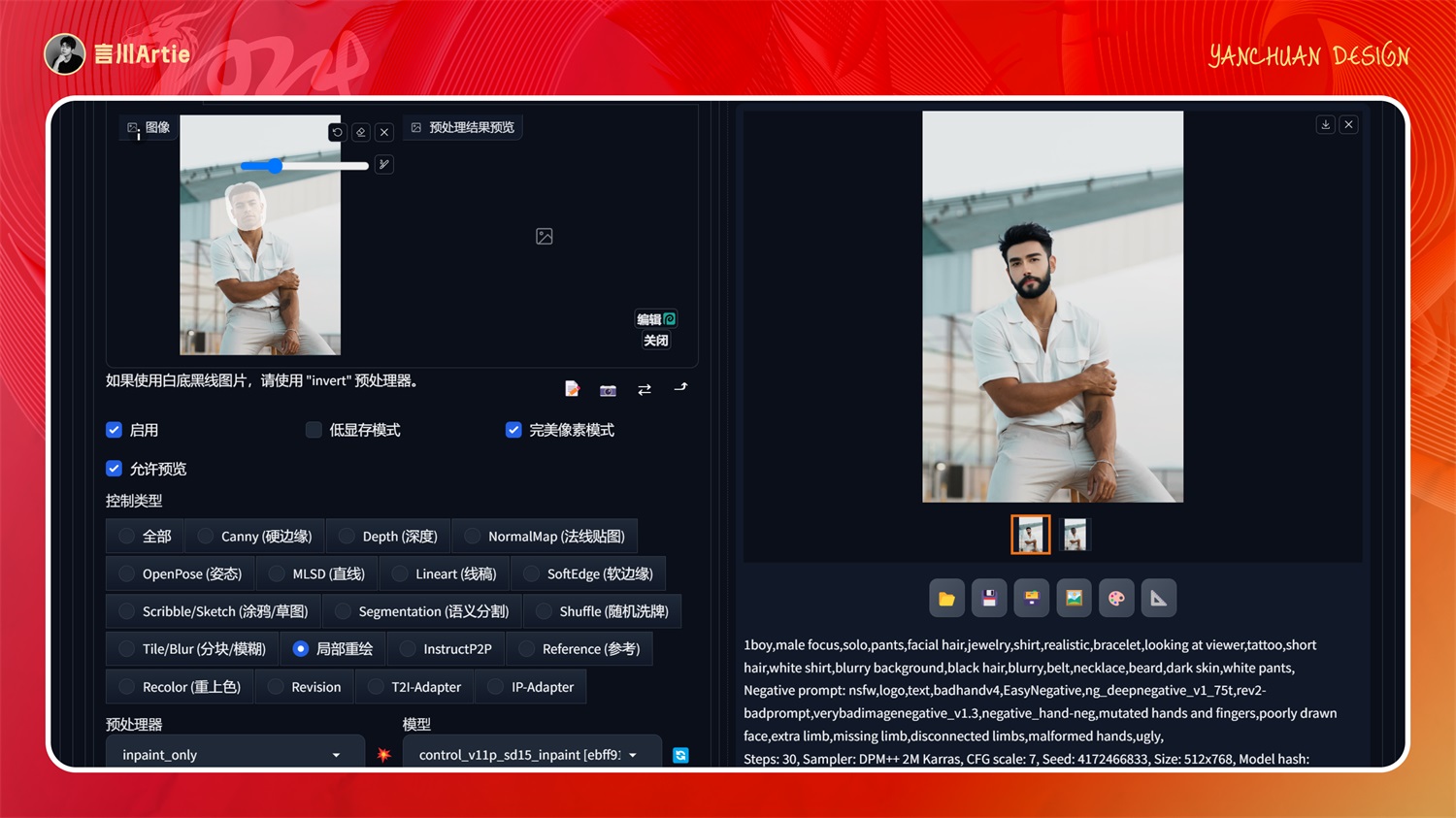
上传图片,按住 S 键放大原图,然后用画笔涂抹人物头部区域,点击生成就会给我们换头处理。如下图,我没有开高清修复和 After Detailer,所以面部融合不是很自然。
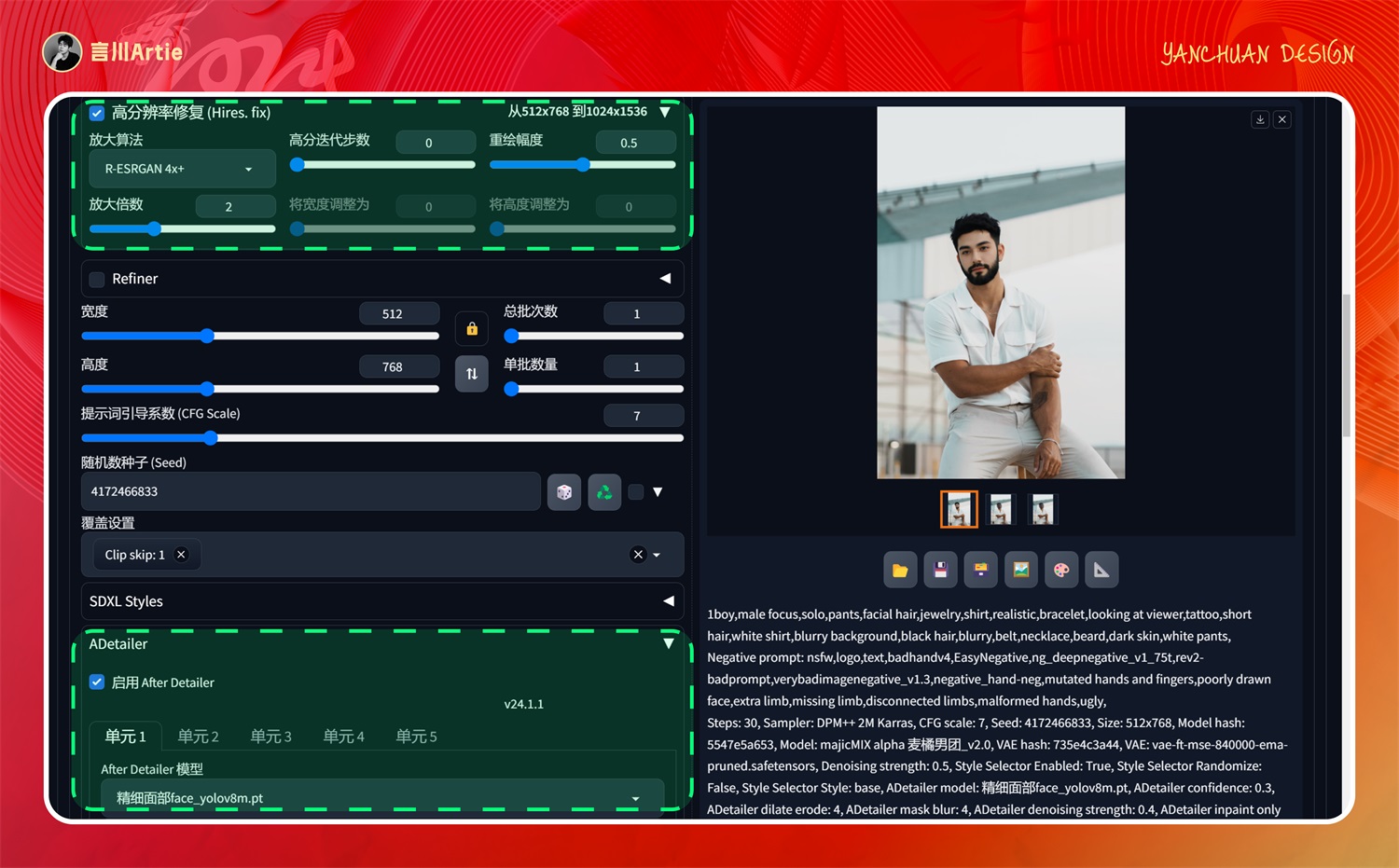
开启高清修复和 After Detailer 后,头部质量明显提升,而且融合的相对比较自然,实测比图生图中的重绘幅度好用很多。
⑭ControlNet 1.1 Tile
使用瓷砖控制Stable Diffusion模型文件:control_v11f1e_sd15_tile.pth
介绍:让一张模糊的图片变成高清的图片,或者是让一张不清晰的图变成超多细节的图。可作用于老照片修复,图片高清化处理,非常的强大。
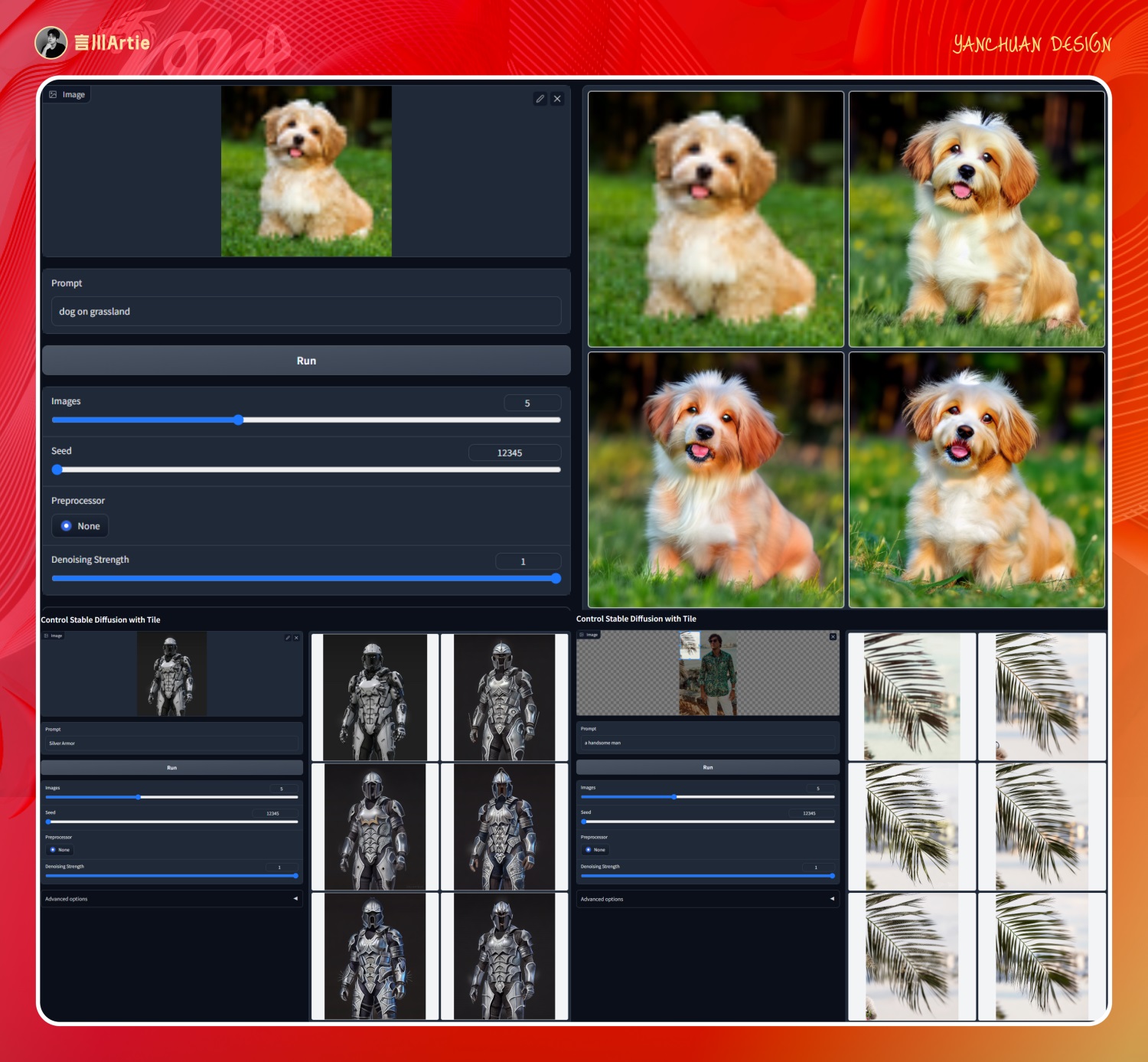
实操案例(老照片修复):
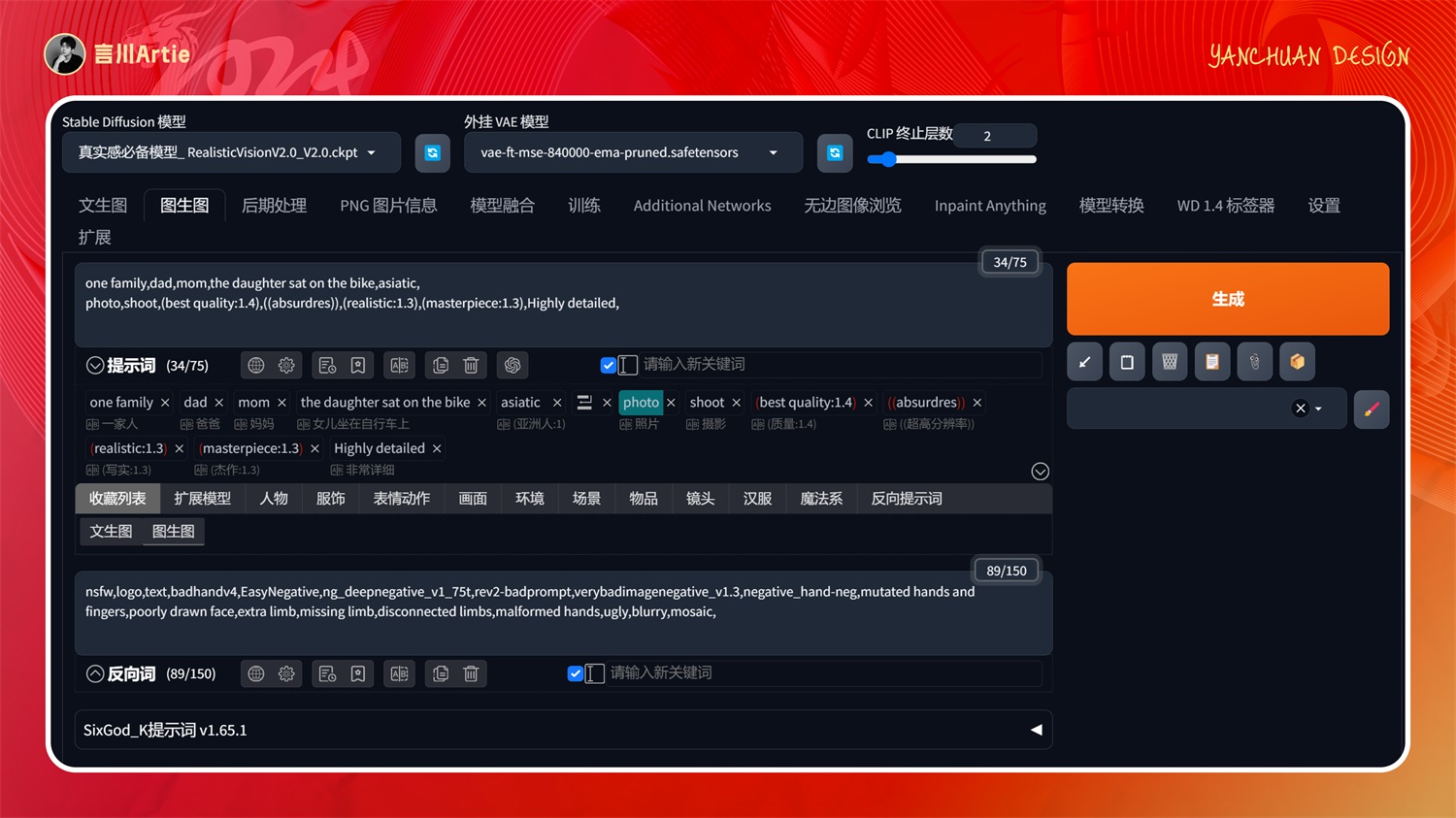
大模型:RealisticVisionV2.0
图生图反推关键词:one family,dad,mom,the daughter sat on the bike,asiatic,photo,shoot,(best quality:1.4),((absurdres)),(realistic:1.3),(masterpiece:1.3),Highly detailed,
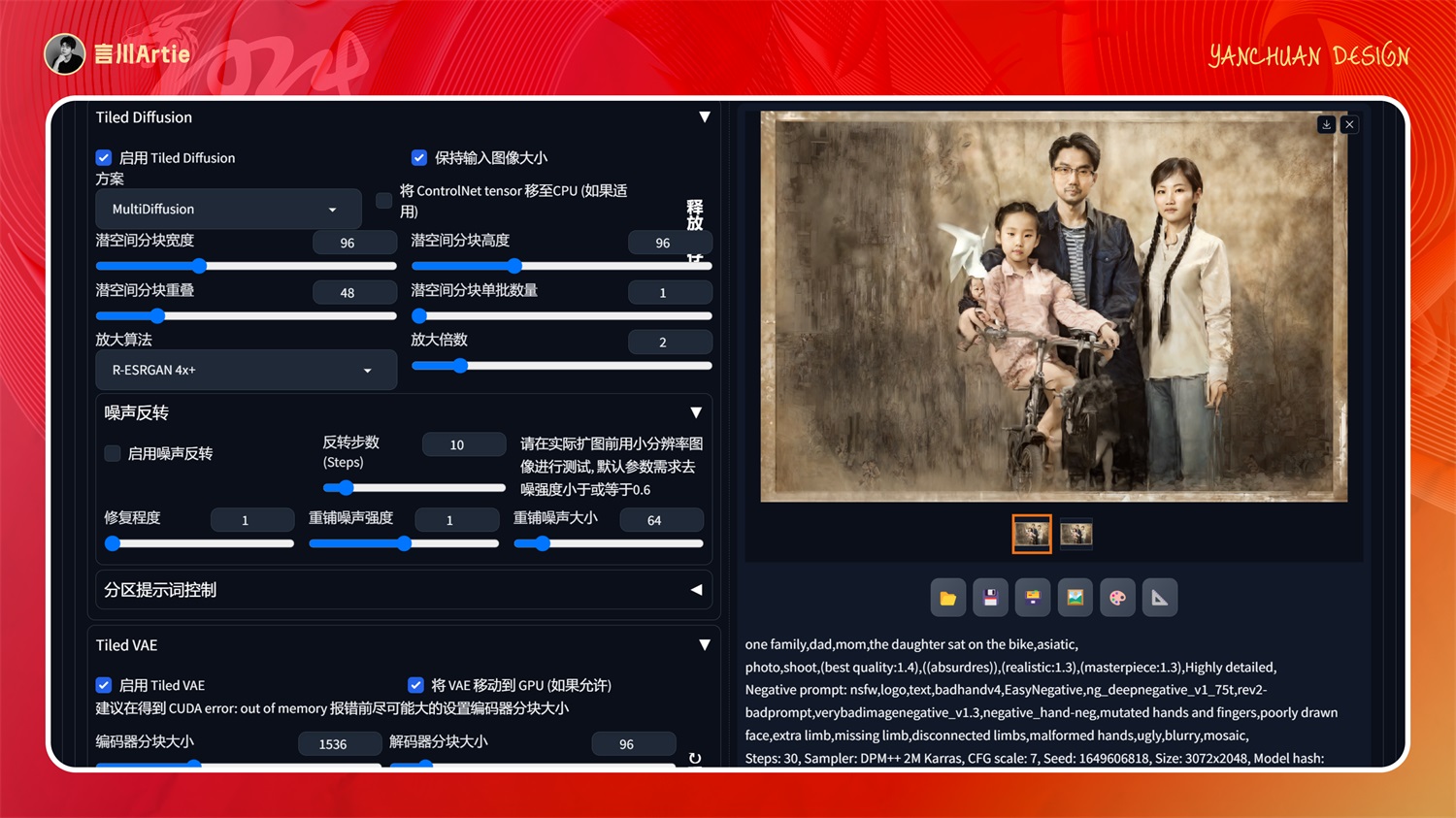
启用 Tiled Diddusion 和 Tiled VAE,放大算法切换为 R-ESRGAN 4X+,放大倍数 2 倍。
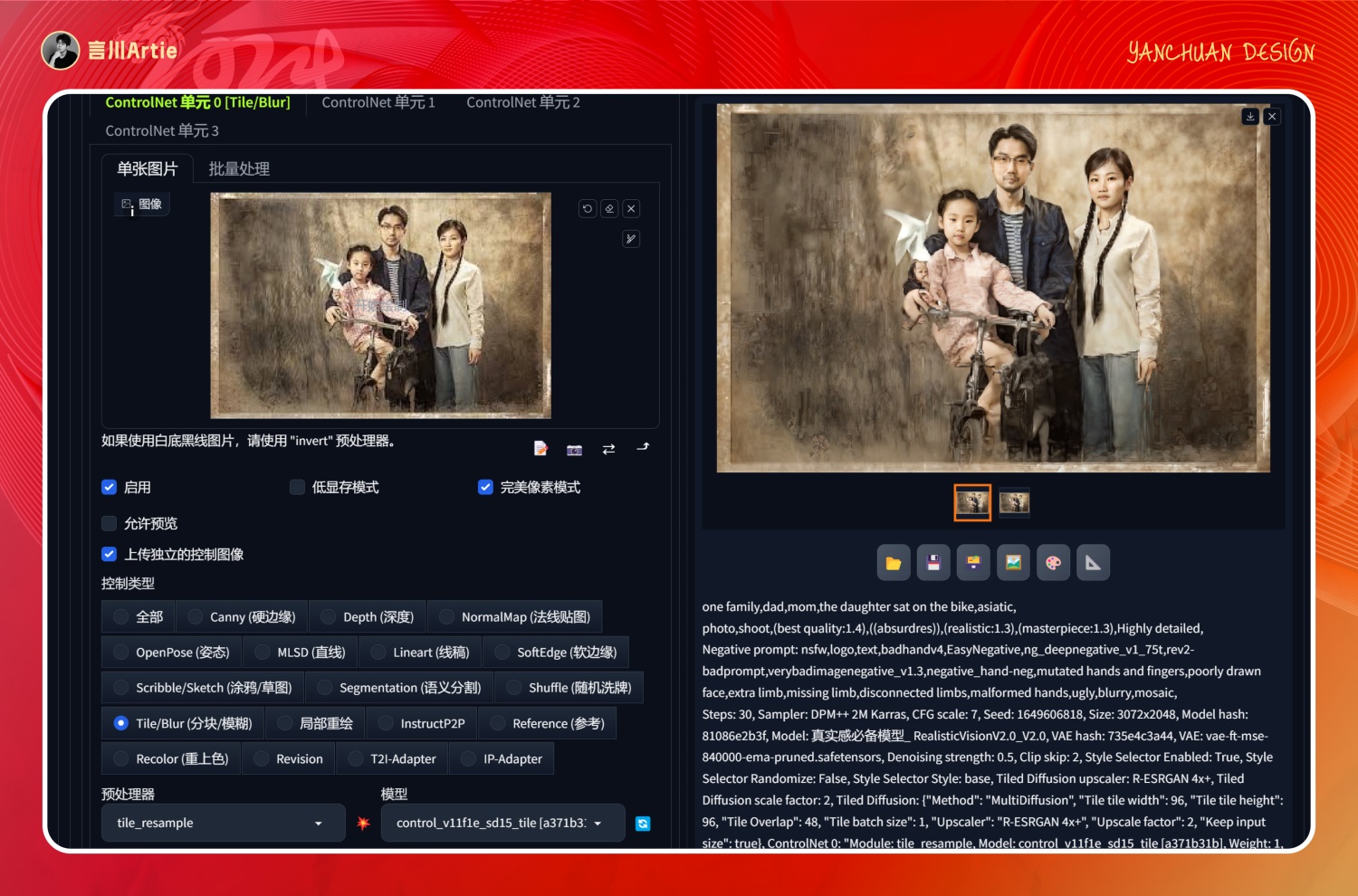
启用 controlnet,上传老照片,使用 tile 模型,点击生成即可得到一张修复后的高清大图。
3. 非官方发布模型
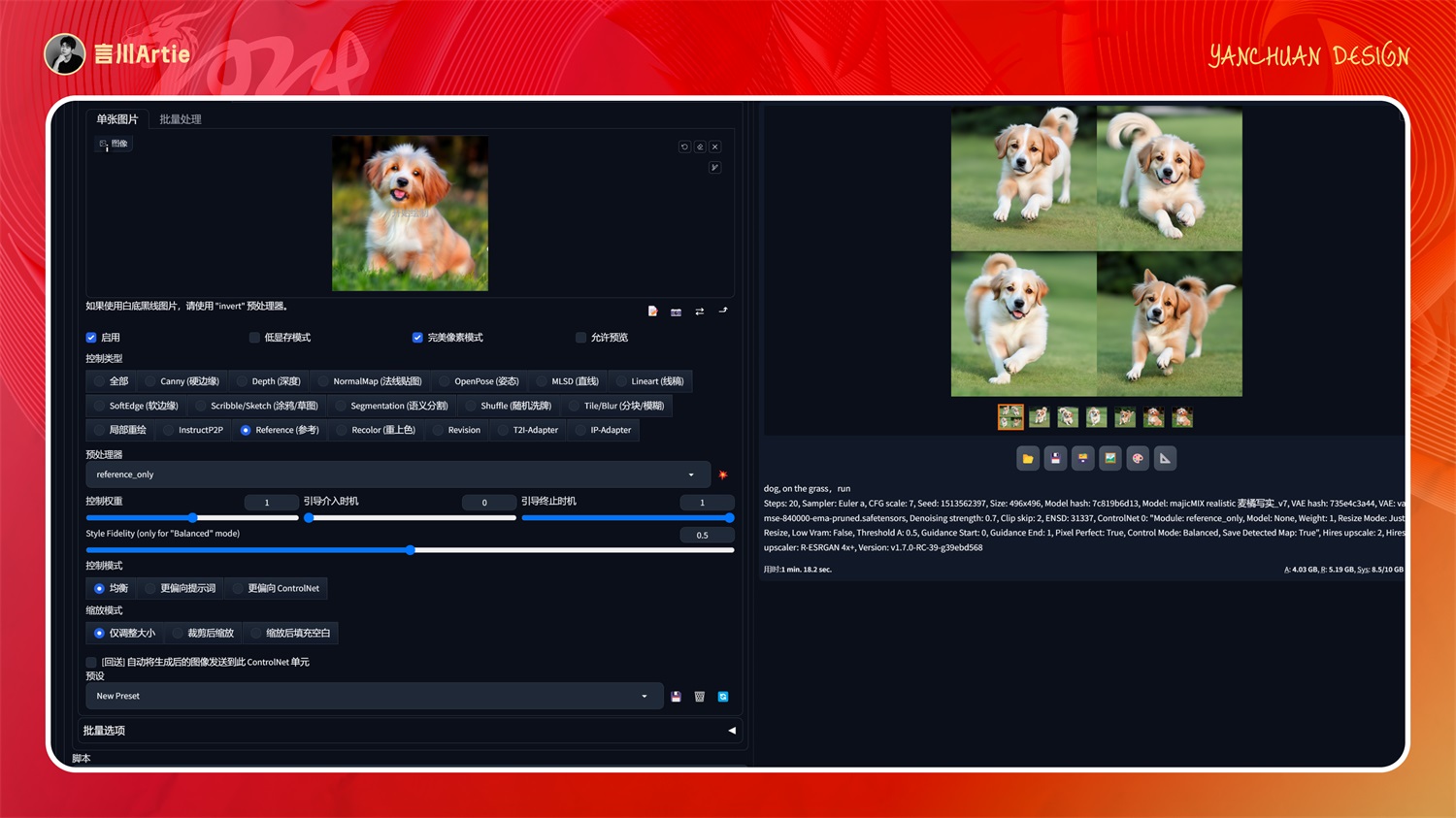
①reference
使用参考图控制Stable Diffusion模型文件:无模型文件
介绍:可以理解为垫图,AI 会根据上传的图片进行物体和风格的参考进行重新绘制,也可以通过关键词描述改变物体动作或形态。
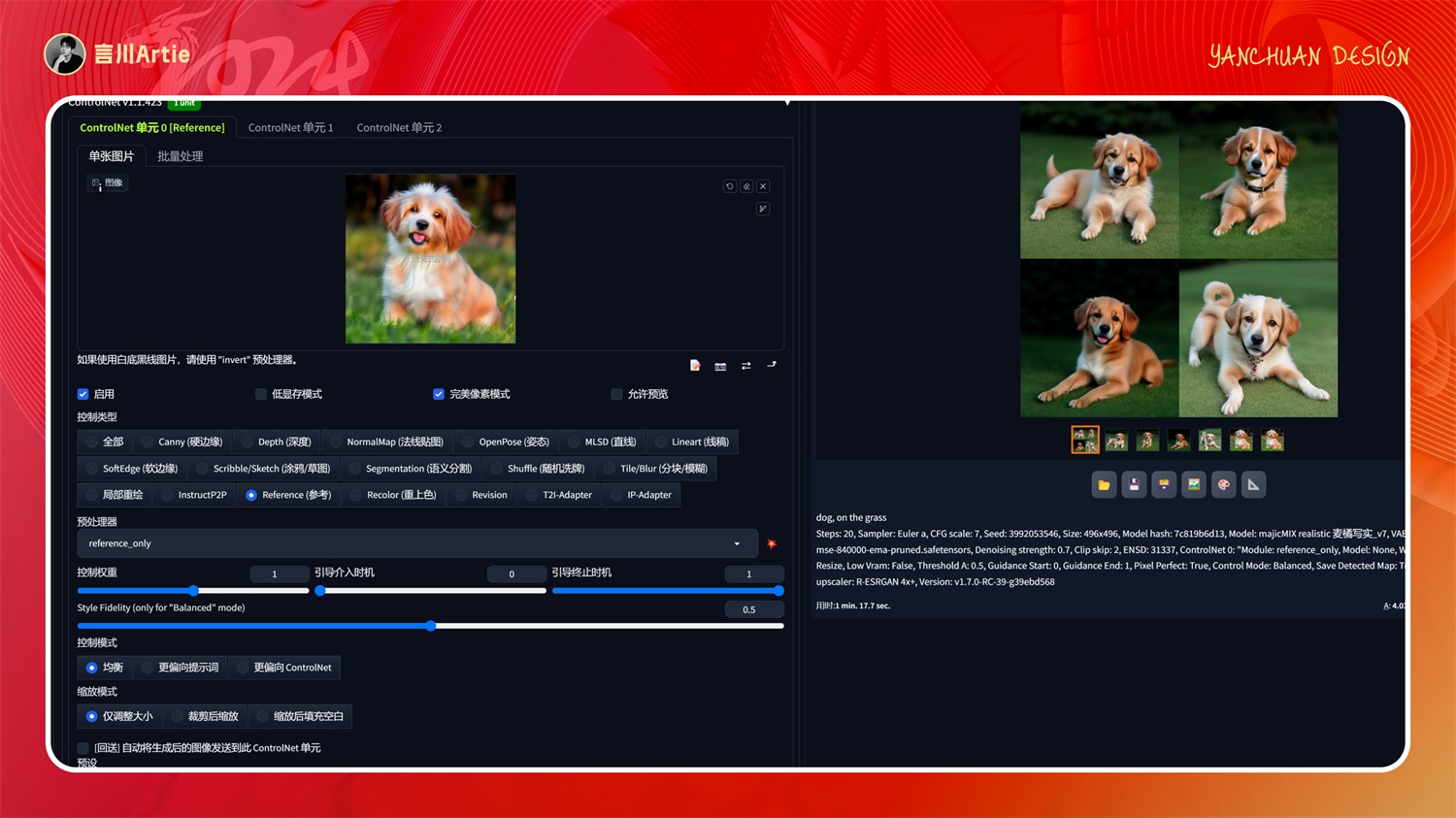
实操案例:
大模型:RealisticVisionV2.0
正向关键词:dog, on the grass, run
reference 没有模型,只有一个预处理器,上传图片后,在正向关键词中输入描述词就可以生成与原图类似风格的图片效果。
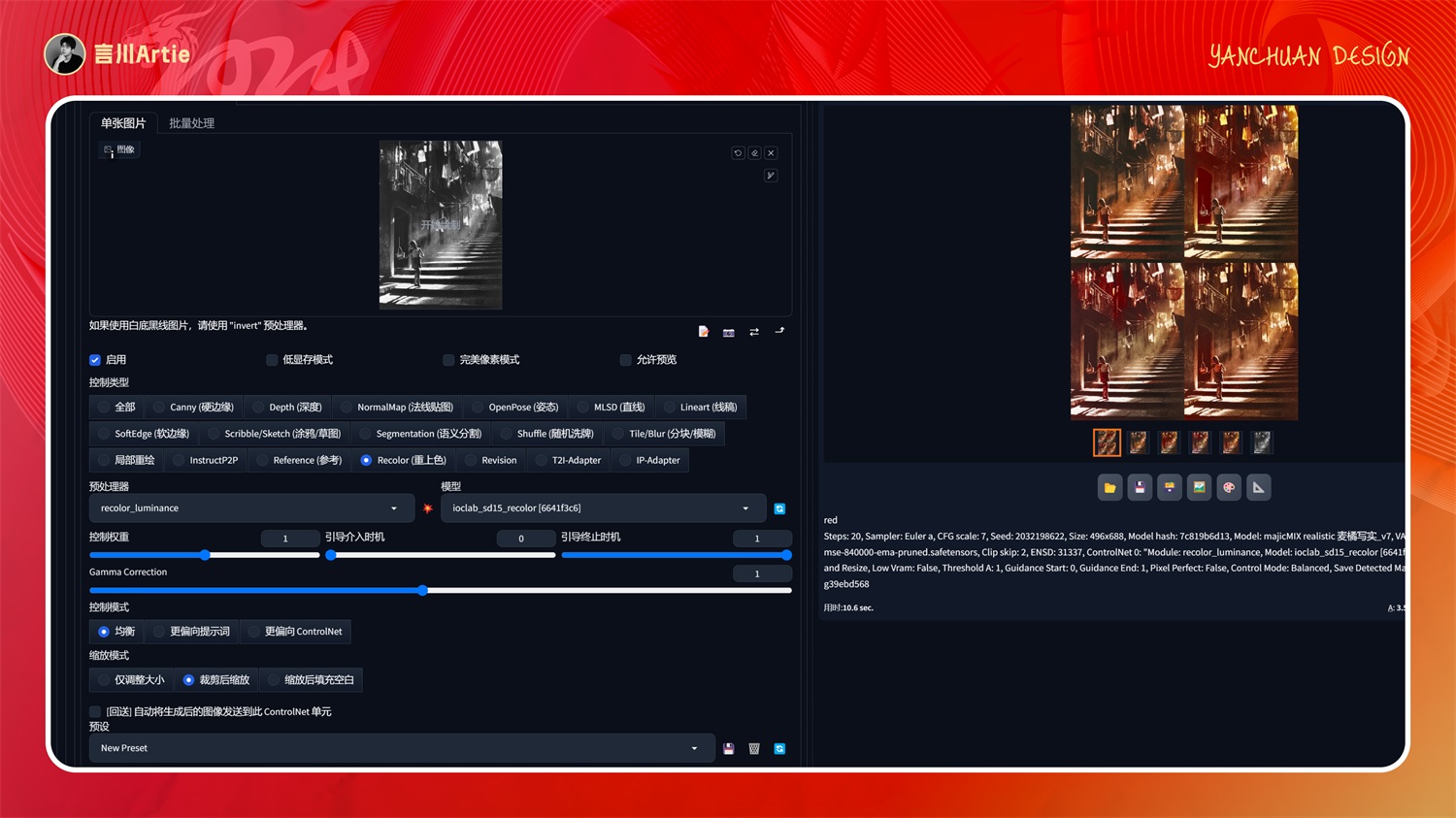
②recolor
使用重上色控制Stable Diffusion模型文件:ioclab_sd15_recolor
介绍:为照片重新上色,比如黑白照片上色,也可以通过关键词指定颜色(下图无关键词)。
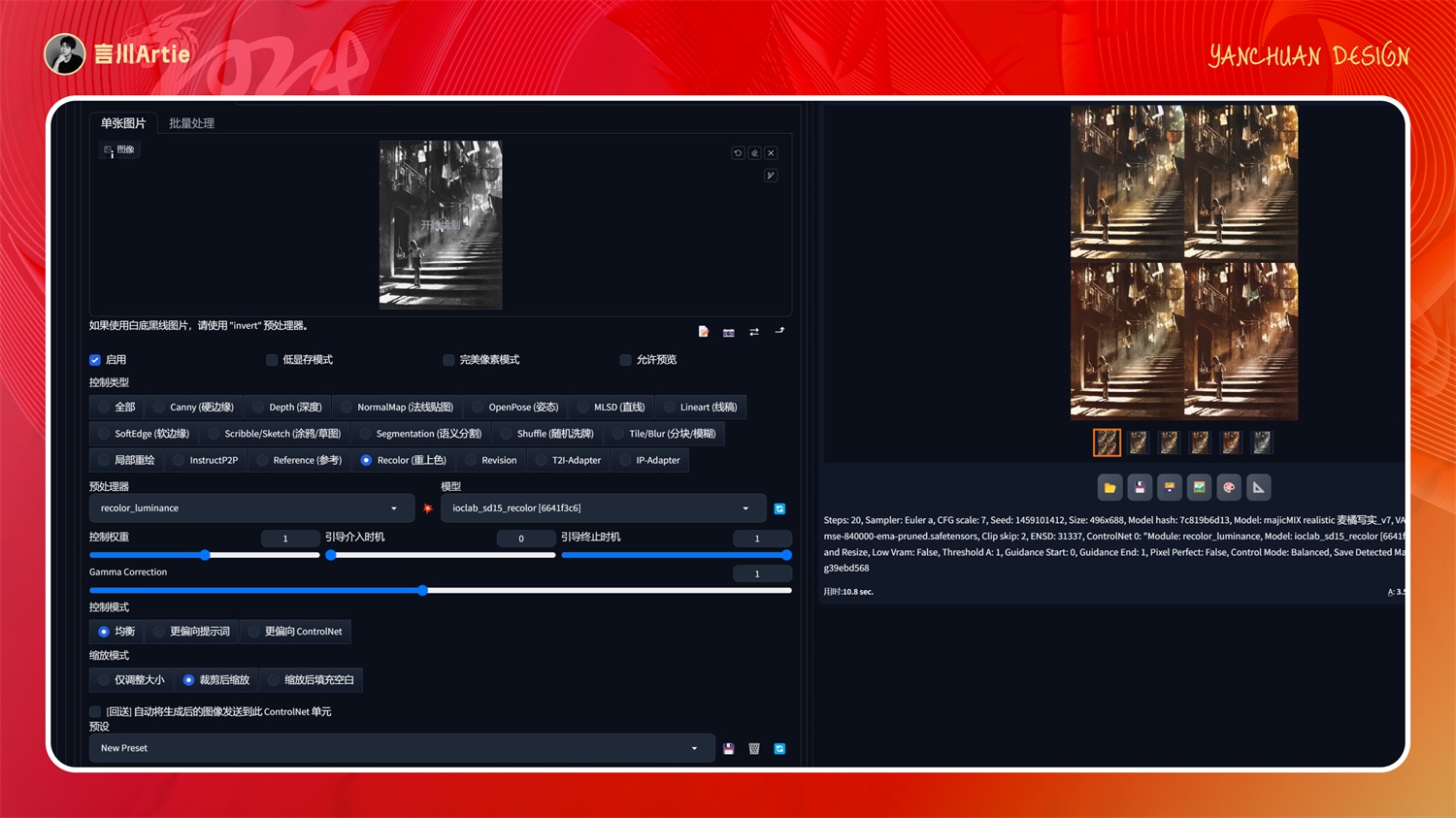
大模型:RealisticVisionV2.0
正向关键词:red
启用 controlnet,上传黑白照片,在正向关键词中输入“红色”关键词,点击生成之后,照片的整体色调就被赋予了红色,如果想换成其他色调可通过调整关键词切换。
以上就是本篇 controlnet 模型的全部拆解,不知道大家对每一个模型是否都了解了,下面我给大家演示一个通过 controlnet 插件完成背景生成的案例。
四、人物背景生成
1. 前期准备
下面这个案例就是为二次元人物生成一个背景:
我们这个案例的思路就是通过图生图-上传重绘蒙版功能生成背景,用 controlnet 控制背景生成的准确度。在前期的素材准备方面,准备一张白底图和黑白蒙版图。
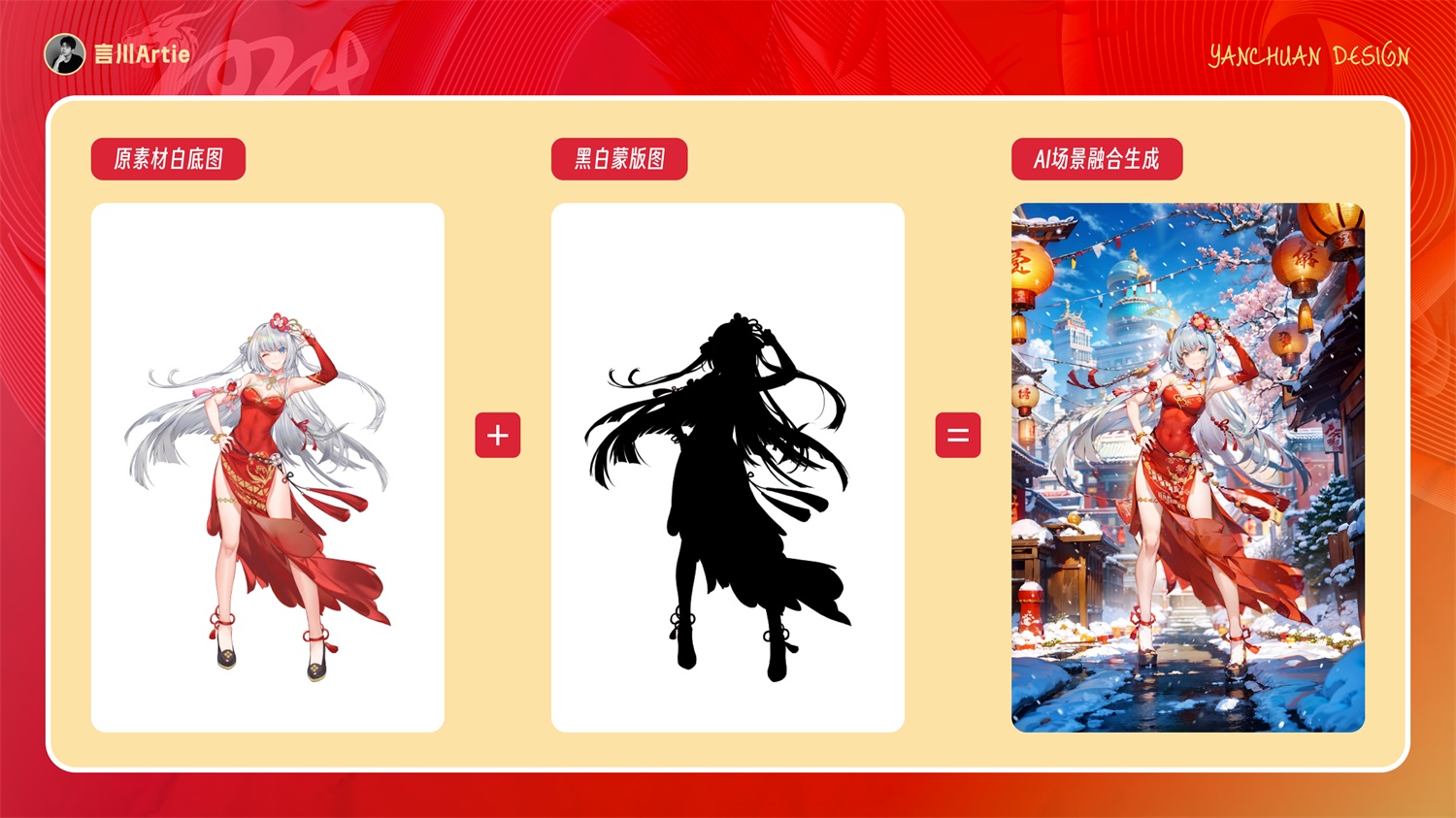
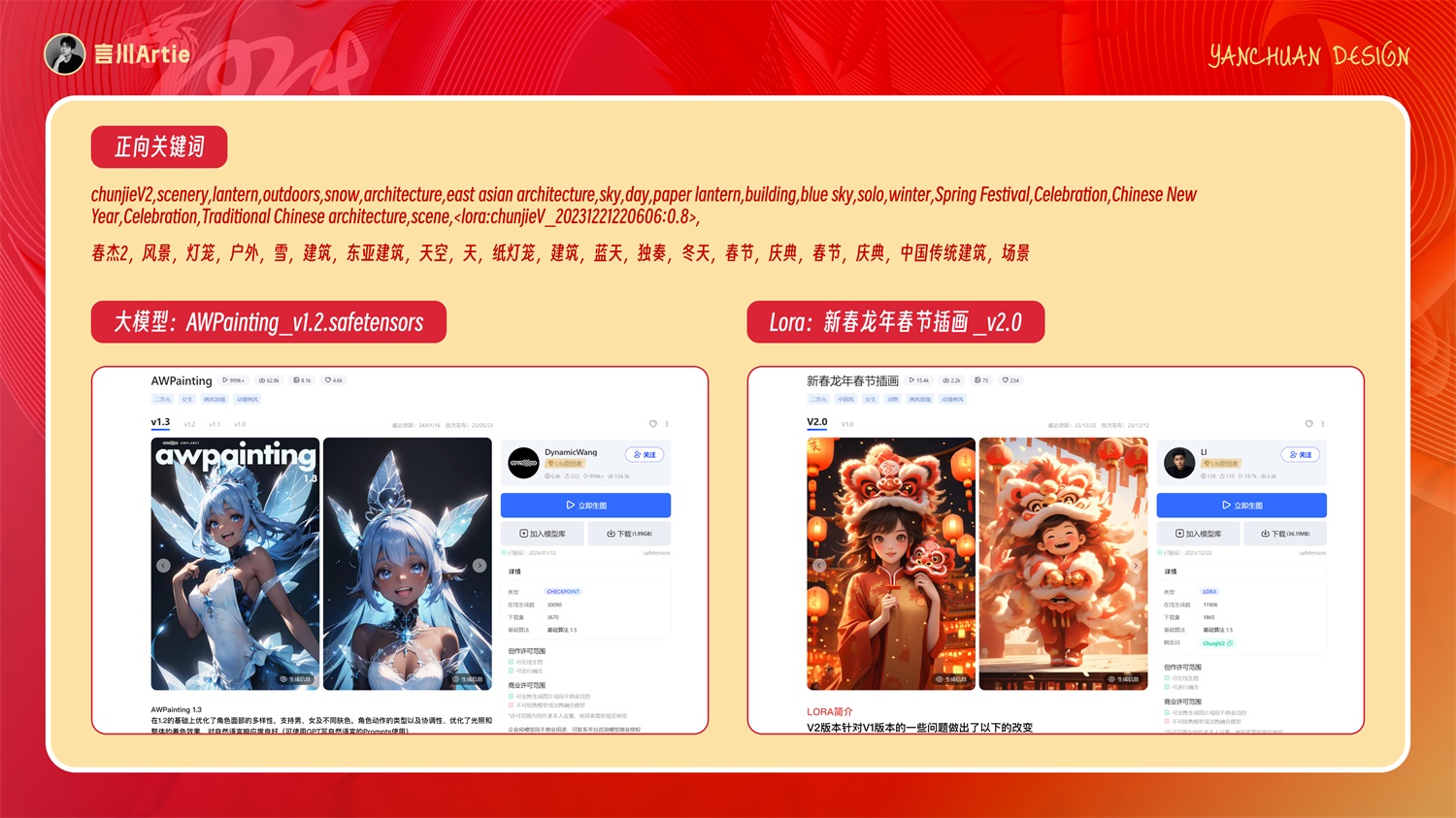
然后就是大模型和 Lora,因为我们主体是一个动漫二次元人物,所以我们的大模型和 lora 也需要用到同一风格的。
大模型:AWPainting_v1.2.safetensors 丨 Lora:新春龙年春节插画 _v2.0
正向关键词描述你想让画面出现的元素:
chunjieV2,scenery,lantern,outdoors,snow,architecture,east asian architecture,sky,day,paper lantern,building,blue sky,solo,winter,Spring Festival,Celebration,Chinese New Year,Celebration,Traditional Chinese architecture,scene,,
春节,风景,灯笼,户外,雪,建筑,东亚建筑,天空,天,纸灯笼,建筑,蓝天,独奏,冬天,春节,庆典,春节,庆典,中国传统建筑,场景
Lora 权重 0.8,反向关键词可自己选择通用的。
2. 基础生图
前期准备工作完成后,就可以把这些素材填充到 web-ui 中了。
在上传重绘蒙版这里,需要注意两点:
蒙版模糊度 10,蒙版模式为重绘非蒙版内容;重绘幅度为 1,因为我们需要 AI 100%参与生成。
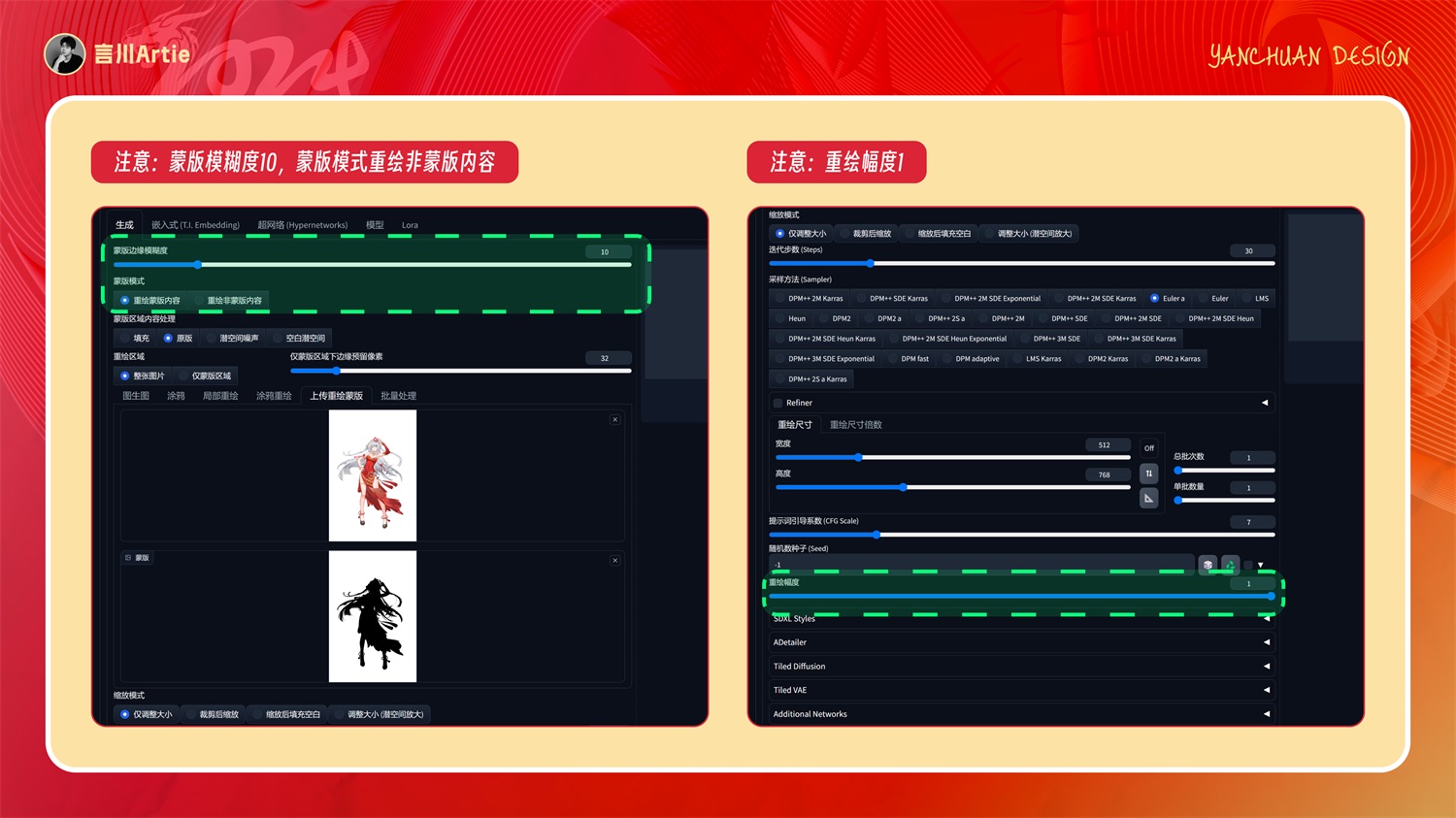
设置完上面一部分后,如果你点击生成,那你的背景一定会有问题,因为我们只通过黑白蒙版是无法精准控制整个画面的,我们还需要使用 controlnet 进一步控制:
单元一:设置 lineart 预处理器和模型,控制人物身体线稿,确保背景不会出现另外一个角色;
单元二:设置 inpaint 预处理器和模型,这个局部重绘会让人物和背景更加融合(可以不上传原图)。
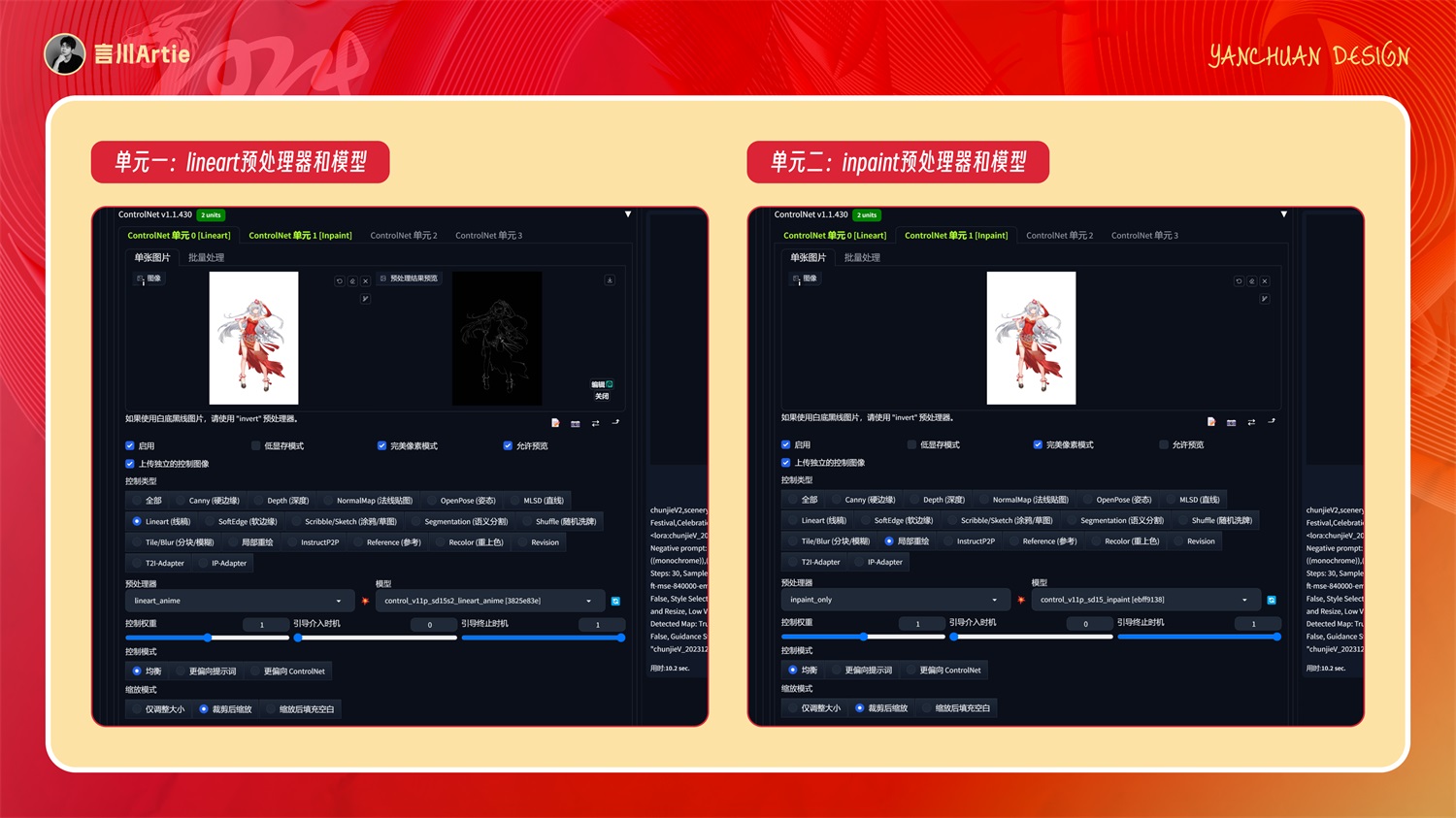
以上步数设置完成后,点击生成,我们就为人物添加上了背景。
但是现在你会发现整张图片的质量并不高,人物在场景中没有光影变化,所以我们还需进行后续的修复:
我们可以批量生成 8 张图,挑选一张你所满意的图片,发送到图生图。

3. 后期修复
先把生成图发送到图生图,然后重绘幅度设置为 0.3,设置 tiled diffusion 和 tiled VAE 插件。
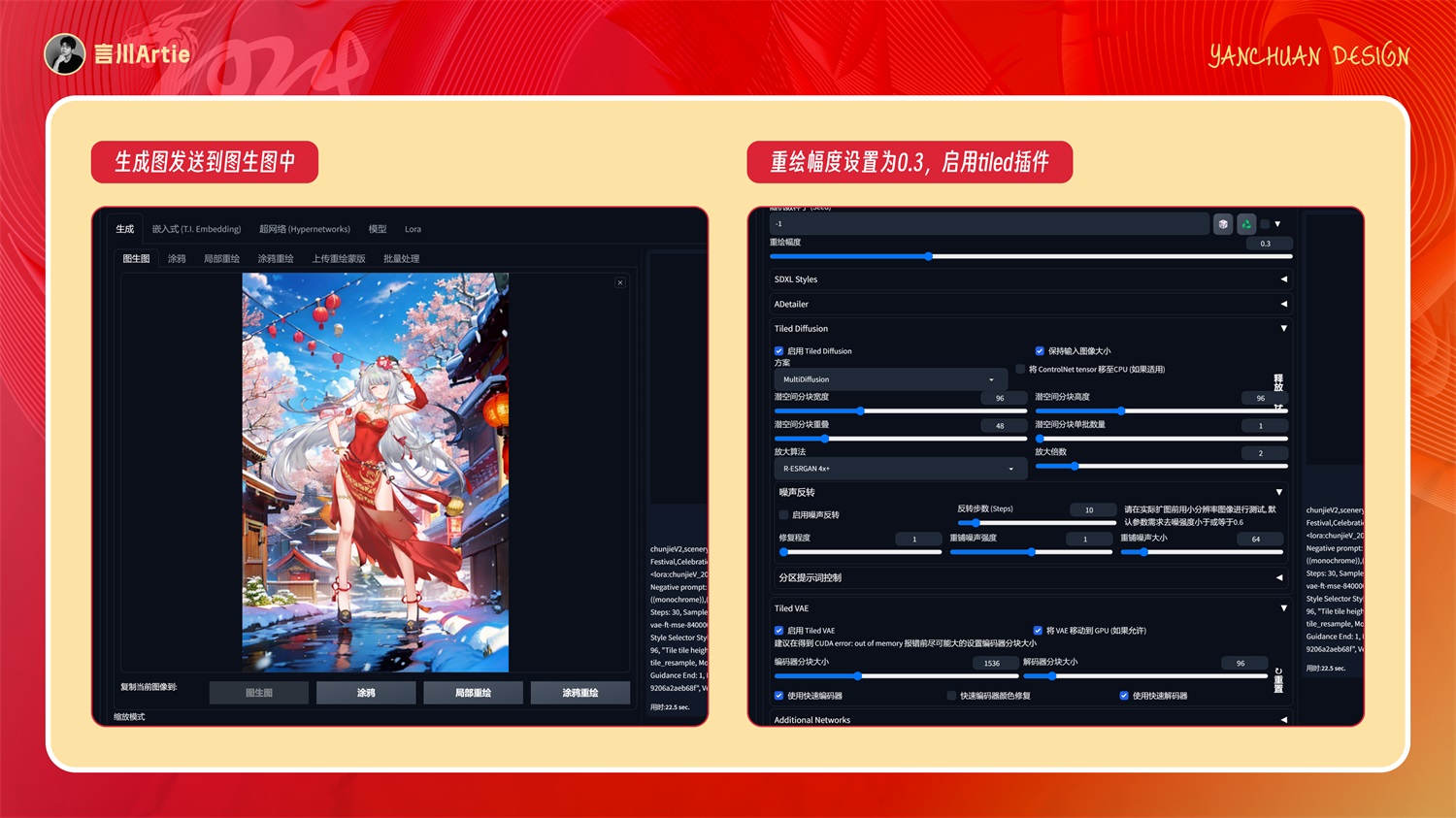
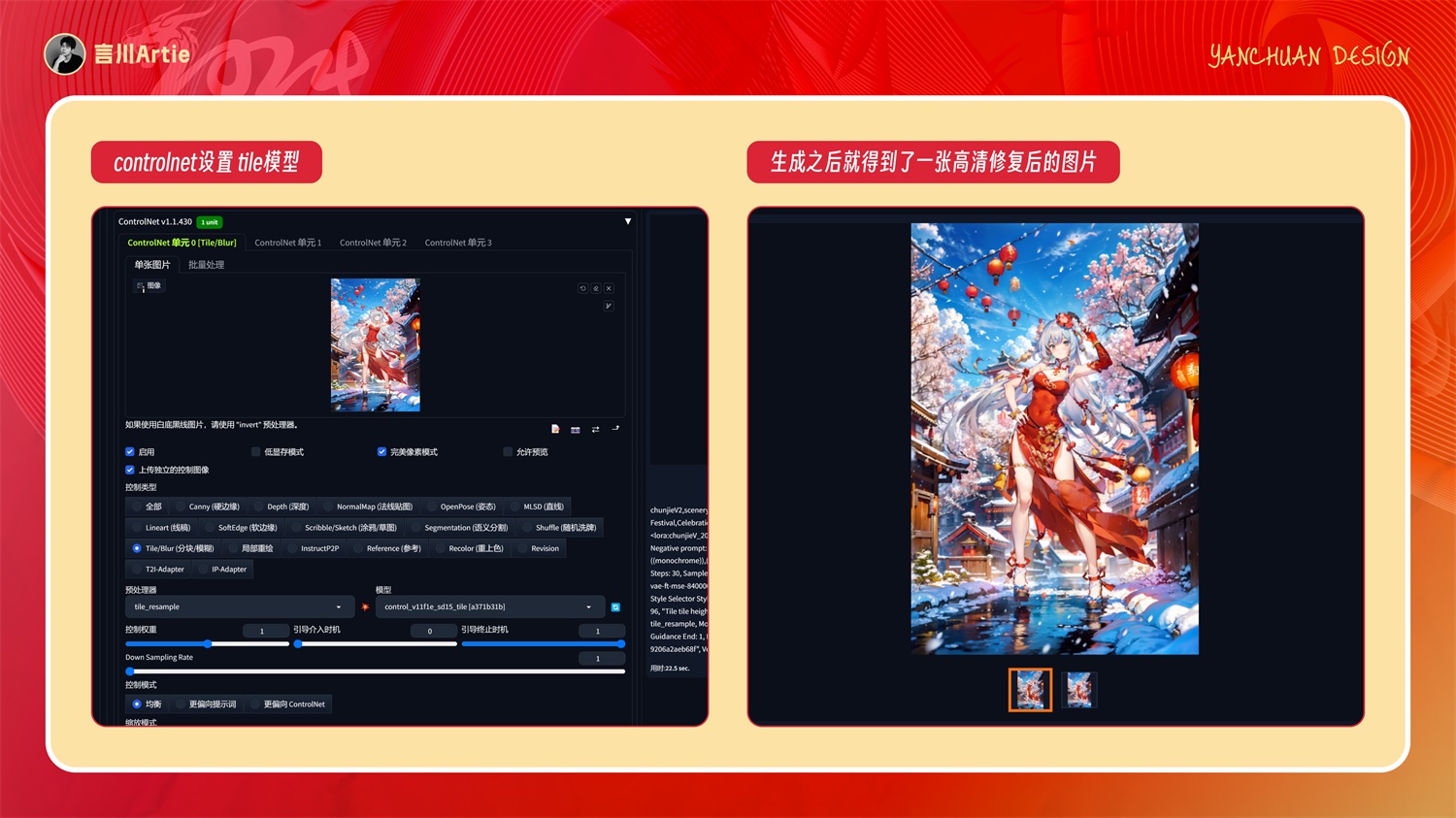
在 controlnet 这里设置 tile 模型进行细节的修复,点击生成之后我们就得到了一张高清修复后的图片。
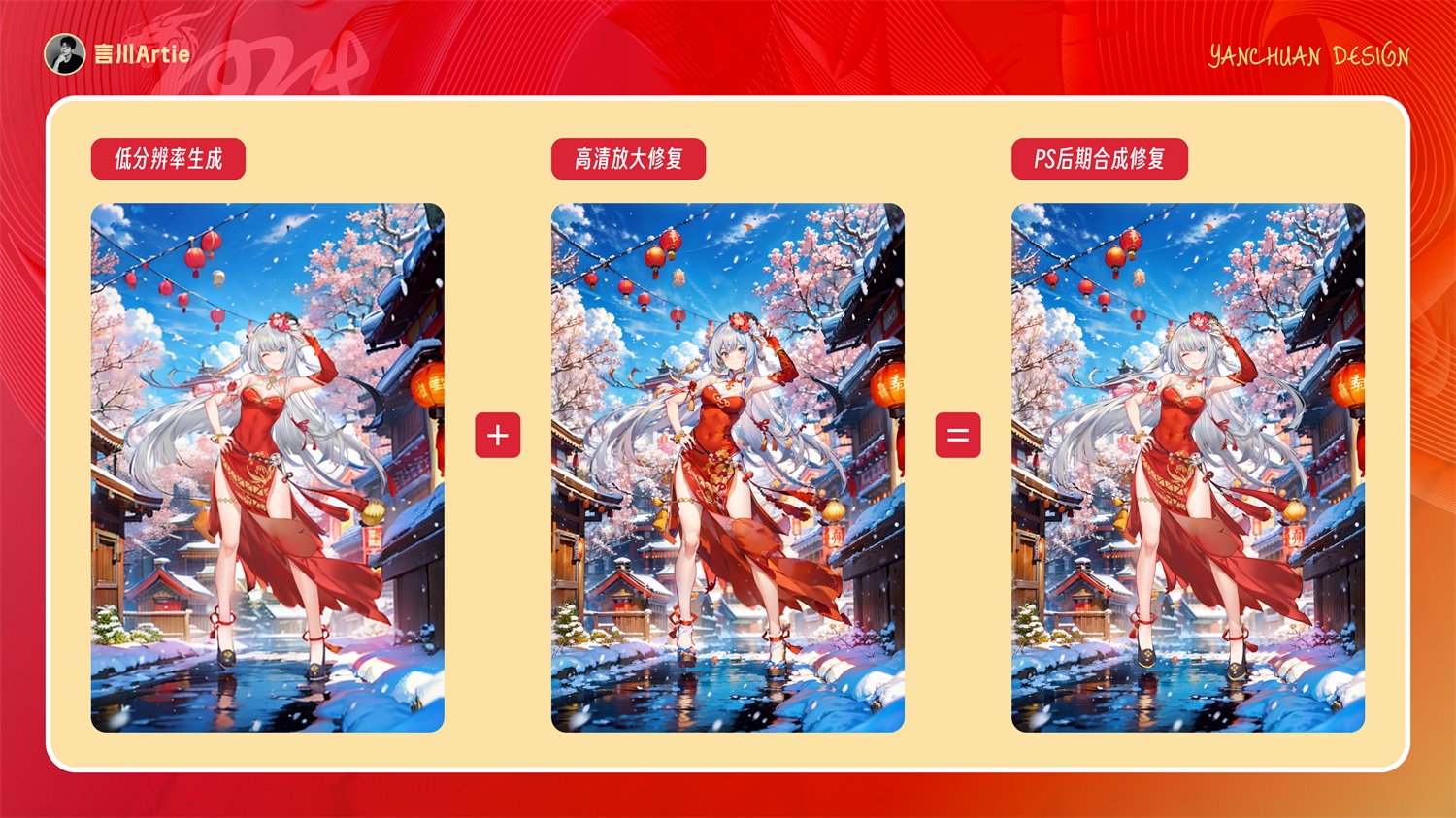
到此处你还会发现,生成后的人物主体发生了变化,那是因为我们的重绘幅度 0.3 影响了人物主体。但是我们如果设置更小的重绘幅度,整个场景包括人物的光影细节都不会有变化,所以我们可以让 SD 休息会了,剩下的交给 Photoshop 来修复。
到 PS 中,我们就可以把原图的人物覆盖上去,然后各位就在 PS 中各显神通,把原图用图层蒙版功能涂涂抹抹,最后我们就得到了一张高清的二次元新春图了。
五、结语
以上就是本教程的全部内容了,重点介绍了 controlnet 模型,当然还有一些小众的模型在本次教程中没有出现,目前 controlnet 模型确实还挺多的,所以重点放在了官方发布的几个模型上。
熟悉并掌握每个模型的作用后,你就可以灵活的在 web ui 中使用这些模型,还有各种模型之间的搭配。本教程的案例只是众多商业化设计中的一个操作流程,之后我还会分享更多的商业设计工作流,你可以在我的主页获取链接我的方式,期待与大家的交流。
最后最后,新年快乐啦,发布上线本篇教程后,我就溜溜球了,放假放假~
相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
