

 新火种
2023-10-20
新火种
2023-10-20 


手机上就能学!Pytorch深度学习教程手把手教你从DQN到Rainbow
鱼羊 发自 凹非寺量子位 报道 | 公众号 QbitAI炎炎夏日,燥热难耐,不如学学深度学习冷静一下?这里有一份干货教程,手把手带你入门深度强化学习(Deep Reiforcement Learning),背景理论、代码实现全都有,在线领取无需安装哟!废话不多说,赶紧领取教程看看里头具体都有哪些宝藏知识吧~步步深入RL这份Pytorch强化学习教程一共有八章,从DQN(Deep Q-Learning)开始,步步深入,最后向你展示Rainbow到底是什么。不仅有Jupyter Notebook,作者还在Colab上配置好了代码,无需安装,你就能直观地感受到算法的效果,甚至还可以直接在手机上进行学习! 1. DQNDeepRL入门第一步,当先了解DQN(Deep Q-Learning)。这是DeepMind提出的一种算法,2015年登上Nuture。它首次将深度神经网络与强化学习进行了结合,实现了从感知到动作的端到端学习,在多种雅达利游戏当中达到了超人水平。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/01.dqn.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/01.dqn.ipynb#scrollTo=nEcnUNg8Sn3I
1. DQNDeepRL入门第一步,当先了解DQN(Deep Q-Learning)。这是DeepMind提出的一种算法,2015年登上Nuture。它首次将深度神经网络与强化学习进行了结合,实现了从感知到动作的端到端学习,在多种雅达利游戏当中达到了超人水平。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/01.dqn.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/01.dqn.ipynb#scrollTo=nEcnUNg8Sn3I △Colab在线训练
△Colab在线训练 2. Double DQNDouble DQN(DDQN)是DQN的一种改进。在DDQN之前,基本所有的目标Q值都是通过贪婪法得到的,而这往往会造成过度估计(overestimations)的问题。DDQN将目标Q值的最大动作分解成动作选择和动作评估两步,有效解决了这个问题。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/02.double_q.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/02.double_q.ipynb
2. Double DQNDouble DQN(DDQN)是DQN的一种改进。在DDQN之前,基本所有的目标Q值都是通过贪婪法得到的,而这往往会造成过度估计(overestimations)的问题。DDQN将目标Q值的最大动作分解成动作选择和动作评估两步,有效解决了这个问题。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/02.double_q.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/02.double_q.ipynb 3.Prioritized Experience Replay该算法的核心在于抽取经验池中过往经验样本时,引入了优先级的概念。也就是说,优先级的大小会影响样本被采样的概率。采用这种方法,重要经验被回放的概率会增大,算法会更容易收敛,学习效率也就相应提高了。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/03.per.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/03.per.ipynb
3.Prioritized Experience Replay该算法的核心在于抽取经验池中过往经验样本时,引入了优先级的概念。也就是说,优先级的大小会影响样本被采样的概率。采用这种方法,重要经验被回放的概率会增大,算法会更容易收敛,学习效率也就相应提高了。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/03.per.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/03.per.ipynb 4. Dueling NetworksDueling DQN是通过优化神经网络的结构来优化算法的。Dueling Networks用两个子网络来分别估计状态值和每个动作的优势。
4. Dueling NetworksDueling DQN是通过优化神经网络的结构来优化算法的。Dueling Networks用两个子网络来分别估计状态值和每个动作的优势。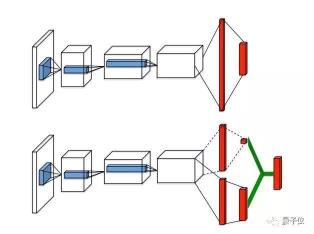 Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/04.dueling.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/04.dueling.ipynb5. Noisy NetworkNoisyNet通过学习网络权重的扰动来推动探索。其关键在于,对权重向量的单一更改可以在多个时间步骤中引发一致的,可能非常复杂的状态相关的策略更改。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/05.noisy_net.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/05.noisy_net.ipynb6. Categorical DQN(C51)Categorical DQN是一种采用分布视角来设计的算法,它建模的是状态-动作价值Q的分布,这样学习的结果会更加准确。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/06.categorical_dqn.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/06.categorical_dqn.ipynb7. N-step LearningDQN使用当前的即时奖励和下一时刻的价值估计作为目标价值,学习速度可能相对较慢。而使用前视多步骤目标实际上也是可行的。N-step Learning通过调整多步骤目标n来加快学习速度。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/07.n_step_learning.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/07.n_step_learning.ipynb8. Rainbow有了前七章的铺垫,现在你就能了解到Rainbow的真意了。Rainbow是结合了DQN多种扩展算法的一种新算法,在数据效率和最终性能方面,该方法表现出了惊人的效果。
Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/04.dueling.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/04.dueling.ipynb5. Noisy NetworkNoisyNet通过学习网络权重的扰动来推动探索。其关键在于,对权重向量的单一更改可以在多个时间步骤中引发一致的,可能非常复杂的状态相关的策略更改。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/05.noisy_net.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/05.noisy_net.ipynb6. Categorical DQN(C51)Categorical DQN是一种采用分布视角来设计的算法,它建模的是状态-动作价值Q的分布,这样学习的结果会更加准确。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/06.categorical_dqn.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/06.categorical_dqn.ipynb7. N-step LearningDQN使用当前的即时奖励和下一时刻的价值估计作为目标价值,学习速度可能相对较慢。而使用前视多步骤目标实际上也是可行的。N-step Learning通过调整多步骤目标n来加快学习速度。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/07.n_step_learning.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/07.n_step_learning.ipynb8. Rainbow有了前七章的铺垫,现在你就能了解到Rainbow的真意了。Rainbow是结合了DQN多种扩展算法的一种新算法,在数据效率和最终性能方面,该方法表现出了惊人的效果。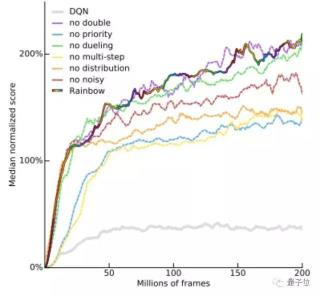 然而,整合并非一件简单的事情,针对这一点,教程也做出了讨论。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/08.rainbow.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/08.rainbow.ipynb#scrollTo=ougv5VEKX1d1系统学习是个非常不错的选择,当然作者也说了,以上知识点,你也可以选择想学哪里点哪里。学习小技巧如果你想在本地运行这些代码,那么这里有些小技巧请拿好。首先是运行环境:$ conda create -n rainbow_is_all_you_need python=3.6.1$ conda activate rainbow_is_all_you_need进入安装环节,首先,克隆存储库:git clone https://github.com/Curt-Park/rainbow-is-all-you-need.gitcd rainbow-is-all-you-need其次,安装执行代码所需的包,这很简单:make dep那么,快开始学习吧~传送门教程地址:https://github.com/Curt-Park/rainbow-is-all-you-need— 完 —
然而,整合并非一件简单的事情,针对这一点,教程也做出了讨论。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/08.rainbow.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/08.rainbow.ipynb#scrollTo=ougv5VEKX1d1系统学习是个非常不错的选择,当然作者也说了,以上知识点,你也可以选择想学哪里点哪里。学习小技巧如果你想在本地运行这些代码,那么这里有些小技巧请拿好。首先是运行环境:$ conda create -n rainbow_is_all_you_need python=3.6.1$ conda activate rainbow_is_all_you_need进入安装环节,首先,克隆存储库:git clone https://github.com/Curt-Park/rainbow-is-all-you-need.gitcd rainbow-is-all-you-need其次,安装执行代码所需的包,这很简单:make dep那么,快开始学习吧~传送门教程地址:https://github.com/Curt-Park/rainbow-is-all-you-need— 完 —
1. DQNDeepRL入门第一步,当先了解DQN(Deep Q-Learning)。这是DeepMind提出的一种算法,2015年登上Nuture。它首次将深度神经网络与强化学习进行了结合,实现了从感知到动作的端到端学习,在多种雅达利游戏当中达到了超人水平。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/01.dqn.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/01.dqn.ipynb#scrollTo=nEcnUNg8Sn3I△Colab在线训练2. Double DQNDouble DQN(DDQN)是DQN的一种改进。在DDQN之前,基本所有的目标Q值都是通过贪婪法得到的,而这往往会造成过度估计(overestimations)的问题。DDQN将目标Q值的最大动作分解成动作选择和动作评估两步,有效解决了这个问题。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/02.double_q.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/02.double_q.ipynb3.Prioritized Experience Replay该算法的核心在于抽取经验池中过往经验样本时,引入了优先级的概念。也就是说,优先级的大小会影响样本被采样的概率。采用这种方法,重要经验被回放的概率会增大,算法会更容易收敛,学习效率也就相应提高了。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/03.per.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/03.per.ipynb4. Dueling NetworksDueling DQN是通过优化神经网络的结构来优化算法的。Dueling Networks用两个子网络来分别估计状态值和每个动作的优势。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/04.dueling.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/04.dueling.ipynb5. Noisy NetworkNoisyNet通过学习网络权重的扰动来推动探索。其关键在于,对权重向量的单一更改可以在多个时间步骤中引发一致的,可能非常复杂的状态相关的策略更改。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/05.noisy_net.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/05.noisy_net.ipynb6. Categorical DQN(C51)Categorical DQN是一种采用分布视角来设计的算法,它建模的是状态-动作价值Q的分布,这样学习的结果会更加准确。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/06.categorical_dqn.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/06.categorical_dqn.ipynb7. N-step LearningDQN使用当前的即时奖励和下一时刻的价值估计作为目标价值,学习速度可能相对较慢。而使用前视多步骤目标实际上也是可行的。N-step Learning通过调整多步骤目标n来加快学习速度。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/07.n_step_learning.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/07.n_step_learning.ipynb8. Rainbow有了前七章的铺垫,现在你就能了解到Rainbow的真意了。Rainbow是结合了DQN多种扩展算法的一种新算法,在数据效率和最终性能方面,该方法表现出了惊人的效果。然而,整合并非一件简单的事情,针对这一点,教程也做出了讨论。Pytorch Jupyter Notebook:https://nbviewer.jupyter.org/github/Curt-Park/rainbow-is-all-you-need/blob/master/08.rainbow.ipynbColab:https://colab.research.google.com/github/Curt-Park/rainbow-is-all-you-need/blob/master/08.rainbow.ipynb#scrollTo=ougv5VEKX1d1系统学习是个非常不错的选择,当然作者也说了,以上知识点,你也可以选择想学哪里点哪里。学习小技巧如果你想在本地运行这些代码,那么这里有些小技巧请拿好。首先是运行环境:$ conda create -n rainbow_is_all_you_need python=3.6.1$ conda activate rainbow_is_all_you_need进入安装环节,首先,克隆存储库:git clone https://github.com/Curt-Park/rainbow-is-all-you-need.gitcd rainbow-is-all-you-need其次,安装执行代码所需的包,这很简单:make dep那么,快开始学习吧~传送门教程地址:https://github.com/Curt-Park/rainbow-is-all-you-need— 完 — 相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
